048 SparkSQL自定义UDAF函数
一:程序
1.需求
实现一个求平均值的UDAF。
这里保留Double格式化,在完成求平均值后与系统的AVG进行对比,观察正确性。
2.SparkSQLUDFDemo程序
package com.scala.it import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkConf, SparkContext} import scala.math.BigDecimal.RoundingMode object SparkSQLUDFDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[*]")
.setAppName("udf")
val sc = SparkContext.getOrCreate(conf)
val sqlContext = new HiveContext(sc) // ==================================
// 写一个Double数据格式化的自定义函数(给定保留多少位小数部分)
sqlContext.udf.register(
"doubleValueFormat", // 自定义函数名称
(value: Double, scale: Int) => {
// 自定义函数处理的代码块
BigDecimal.valueOf(value).setScale(scale, RoundingMode.HALF_DOWN).doubleValue()
}) // 自定义UDAF
sqlContext.udf.register("selfAvg", AvgUDAF) sqlContext.sql(
"""
|SELECT
| deptno,
| doubleValueFormat(AVG(sal), 2) AS avg_sal,
| doubleValueFormat(selfAvg(sal), 2) AS self_avg_sal
|FROM hadoop09.emp
|GROUP BY deptno
""".stripMargin).show() }
}
3.AvgUDAF程序
package com.scala.it import org.apache.spark.sql.Row
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types._ object AvgUDAF extends UserDefinedAggregateFunction{
override def inputSchema: StructType = {
// 给定UDAF的输出参数类型
StructType(
StructField("sal", DoubleType) :: Nil
)
} override def bufferSchema: StructType = {
// 在计算过程中会涉及到的缓存数据类型
StructType(
StructField("total_sal", DoubleType) ::
StructField("count_sal", LongType) :: Nil
)
} override def dataType: DataType = {
// 给定该UDAF返回的数据类型
DoubleType
} override def deterministic: Boolean = {
// 主要用于是否支持近似查找,如果为false:表示支持多次查询允许结果不一样,为true表示结果必须一样
true
} override def initialize(buffer: MutableAggregationBuffer): Unit = {
// 初始化 ===> 初始化缓存数据
buffer.update(0, 0.0) // 初始化total_sal
buffer.update(1, 0L) // 初始化count_sal
} override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
// 根据输入的数据input,更新缓存buffer的内容
// 获取输入的sal数据
val inputSal = input.getDouble(0) // 获取缓存中的数据
val totalSal = buffer.getDouble(0)
val countSal = buffer.getLong(1) // 更新缓存数据
buffer.update(0, totalSal + inputSal)
buffer.update(1, countSal + 1L)
} override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
// 当两个分区的数据需要进行合并的时候,该方法会被调用
// 功能:将buffer2中的数据合并到buffer1中
// 获取缓存区数据
val buf1Total = buffer1.getDouble(0)
val buf1Count = buffer1.getLong(1) val buf2Total = buffer2.getDouble(0)
val buf2Count = buffer2.getLong(1) // 更新缓存区
buffer1.update(0, buf1Total + buf2Total)
buffer1.update(1, buf1Count + buf2Count)
} override def evaluate(buffer: Row): Any = {
// 求返回值
buffer.getDouble(0) / buffer.getLong(1)
}
}
4.效果

二:知识点
1.udf注册

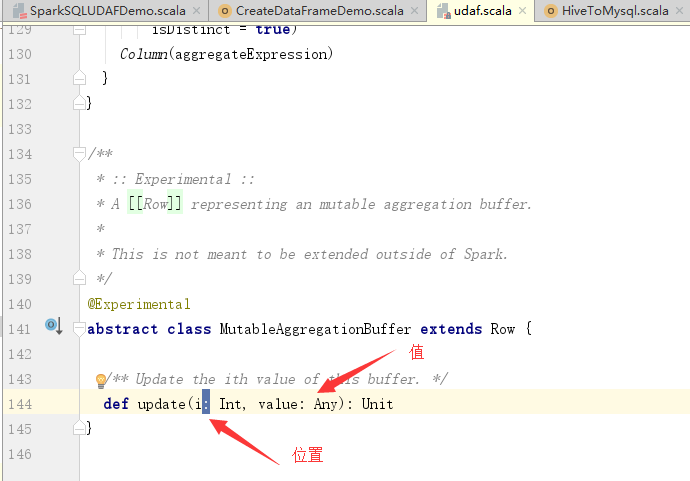
2.解释上面的update
重要的是两个参数的意思,不然程序有些看不懂。
所以,程序的意思是,第一位存储总数,第二位存储个数。
3.还要解释一个StructType的生成
在以前的程序中,是使用Array来生成的。如:

在上面的程序中,不是这种方式,使用集合的方式。

048 SparkSQL自定义UDAF函数的更多相关文章
- hive自定义udaf函数
自定义udaf函数的代码框架 //首先继承一个类AbstractGenericUDAFResolver,然后实现里面的getevaluate方法 public GenericUDAFEvaluator ...
- sparksql 自定义用户函数(UDF)
自定义用户函数有两种方式,区别:是否使用强类型,参考demo:https://github.com/asker124143222/spark-demo 1.不使用强类型,继承UserDefinedAg ...
- 047 SparkSQL自定义UDF函数
一:程序部分 1.需求 Double数据类型格式化,可以给定小数点位数 2.程序 package com.scala.it import org.apache.spark.{SparkConf, Sp ...
- 关于CDH5.2+ 添加hive自定义UDAF函数的方法
- Spark(十三)【SparkSQL自定义UDF/UDAF函数】
目录 一.UDF(一进一出) 二.UDAF(多近一出) spark2.X 实现方式 案例 ①继承UserDefinedAggregateFunction,实现其中的方法 ②创建函数对象,注册函数,在s ...
- 【Spark篇】---SparkSql之UDF函数和UDAF函数
一.前述 SparkSql中自定义函数包括UDF和UDAF UDF:一进一出 UDAF:多进一出 (联想Sum函数) 二.UDF函数 UDF:用户自定义函数,user defined functio ...
- Spark基于自定义聚合函数实现【列转行、行转列】
一.分析 Spark提供了非常丰富的算子,可以实现大部分的逻辑处理,例如,要实现行转列,可以用hiveContext中支持的concat_ws(',', collect_set('字段'))实现.但是 ...
- 自定义Hive函数
7. 函数 7.1 系统内置函数 查看系统自带的函数:show functions; 显示自带的函数的用法:desc function upper(函数名); 详细显示自带的函数的用法:desc fu ...
- 入门大数据---SparkSQL常用聚合函数
一.简单聚合 1.1 数据准备 // 需要导入 spark sql 内置的函数包 import org.apache.spark.sql.functions._ val spark = SparkSe ...
随机推荐
- zipkin 整合elastic
前提: <dependency> <groupId>io.zipkin.java</groupId> <artifactId>zipkin</ar ...
- __dict__(字典的另一种用法)
class Foo(): def __init__(self): self.name=None self.age=19 self.addr='上海' @property def dict(self): ...
- linux进程内存布局
一个程序本质上都是由 BSS 段.data段.text段三个组成的.这样的概念在当前的计算机程序设计中是很重要的一个基本概念,而且在嵌入式系统的设计中也非常重要,牵涉到嵌入式系统运行时的内存大小分 ...
- kafka集群报错
bin/kafka-server-start.sh config/server.properties ,问题来了 : [root@localhost kafka_2.12-0.10.2.0]# Exc ...
- 8 张图帮你一步步看清 async/await 和 promise 的执行顺序(转)
https://mp.weixin.qq.com/s?__biz=MzAxODE2MjM1MA==&mid=2651555491&idx=1&sn=73779f84c289d9 ...
- Confluence 6 的 WebDAV 客户端整合介绍
WebDAV 允许用户通过一个 WebDAV 客户端来访问 Confluence.例如,微软 Windows 的 'My Network Places'.通过为访问的用户提供权限,这个用户可以在 Co ...
- Confluence 6 数据库结构图
结构图细节 下面的 SVG 图片(可缩放矢量图)包括了 Confluence 数据库中使用的所有表.单击下面的连接在你的浏览器中打开图片连接,你也可以随后将图片下载到本地.你可以使用浏览器的缩放快捷键 ...
- 【转载】中文输入法下onKeyPress不能触发的问题
onKeypress---->oninput https://segmentfault.com/a/1190000008820968
- java----DOS命令
dir /? 查看帮助 dir /s 查看当前的目录,以及子目录
- idea首次创建新模块的详细操作
依赖网址:https://mvnrepository.com/artifact/javax.servlet/javax.servlet-api/3.1.0 https://mvnrepository. ...