使用jTessBoxEditorFX训练Tesseract-OCR教程
使用jTessBoxEditorFX训练Tesseract-OCR教程
注:1,工具是JAVA编写的,所以在使用工具之间,需要安装JAVA环境。
2,安装Tesseract-OCR应用程序,并将目录添加到环境变量中,方便使用cmd调用命令。
步骤一:使用画图软件生成要训练的.tif文件,本例做了34个.tif文件,如下:
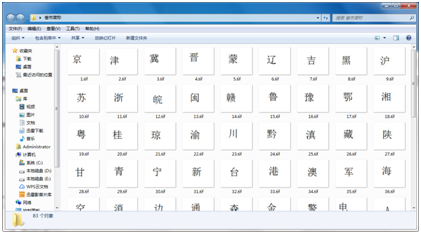
注:图片的格式不限定。我使用灰度图像。
步骤二:使用jTessBoxEditorFX将所有.tif文件合并成一个.tif文件,如图:
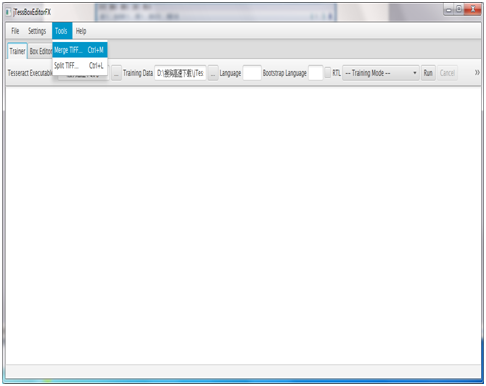


并在该目录下可以看见合并后你所命名的tif文件。如图:
文件名的格式有限制。[lang].[fontname].exp[num].tif
其中lang为语言名称,fontname为字体名称,num为序号,可以随便定义。
例子:num.font.exp0.box
比如我们要训练自定义字库 ec 字体名:unfont
那么我们把tif文件重命名 ec.ufont.exp0.tif
打开cmd窗口,输入以下命令,生成 .box文件
tesseract ec.ufont.exp0.tif ec.ufont.exp0 batch.nochop makebox (主要使用这个命令)
使用训练过的字库生成.box文件
tesseract ec.ufont.exp0.tif ec.ufont.exp0 -l ufont batch.nochop makebox
注:l是L的小写。
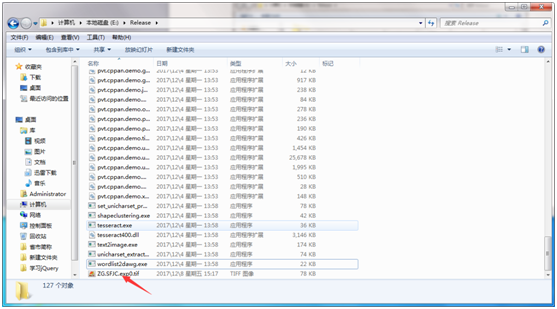
先前自己定义tessdata的环境变量 TESSDATA_PREFIX
值为 E:\tesseract\tessdata,就是字库的路径。
并在该目录下会生成ec.ufont.exp0.box文件,如图:
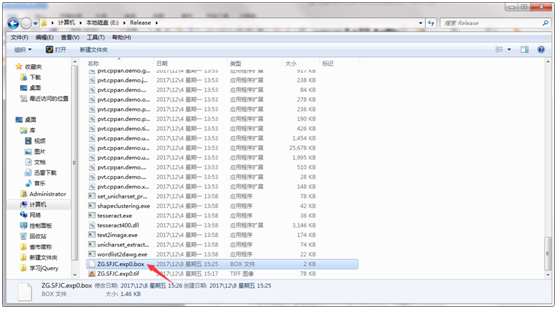
步骤四:使用jTessBoxEditorFX工具选择Box
Editor-Open,打开tif文件(此时同名的tif、box文件必须同处一个目录下,我都给他放在tesseract安装目录下了),如下图:
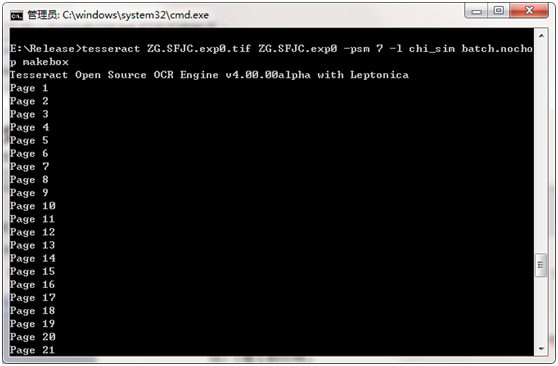
步骤三:打开cmd窗口,输入以下命令,生成box文件,如图:tesseract
[lang].[fontname].exp[num].tif [lang].[fontname].exp[num] batch.nochop
makebox
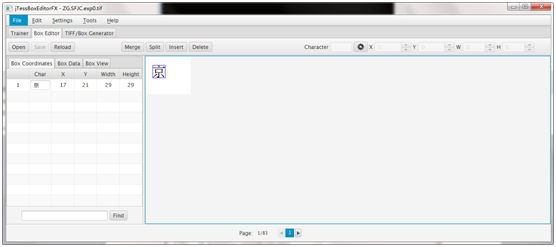
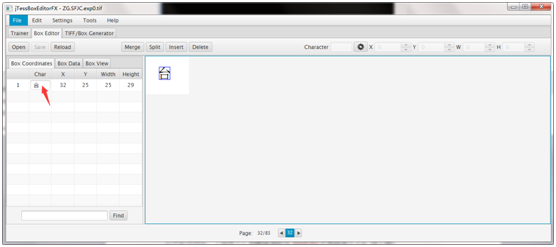
tesseract ec.ufont.exp0.tif ec.ufont.exp0 batch.nochop makebox 查看所有文件并校正错误的文件,如图:
双击红色箭头处,将其修改为台,并单击character 后的后,单击save。矫正完毕。
1. 产生字符特征文件 .tr
tesseract
ec.ufont.exp0.tif ec.ufont.exp0 nobatch box.train
这一步将会产生 ec.ufont.exp0.tr文件和一个 ec.ufont.exp0.txt文件,txt文件貌似没什么用,看看而以。
2.计算字符集(生成unicharset文件)
unicharset_extractor ec.ufont.exp0.box
3.定义字体特征文件
—Tesseract-OCR3.01以上的版本在训练之前需要创建一个名称为font_properties.txt的字体特征文件
手工建立一个文件font_properties.txt
内容如:ufont 0 0 0 0 0
注意:这里 必须与训练名中的名称保持一致,填入下面内容 ,这里全取值为0,表示字体不是粗体、斜体等等。注:[fontname]:即是ec.ufont.exp0中的ufont。公司文档会加密,编辑后一定要进行解密,否者虽然不会报错,但是运行没有反应。
4.聚集字符特征
1) shapeclustering -F font_properties.txt -U unicharset ec.ufont.exp0.tr
注意:如果font_properties不加扩展名.txt,可能会报错
2) mftraining -F font_properties.txt -U unicharset -O unicharset
ec.ufont.exp0.tr
使用上一步产生的字符集文件unicharset,来生成当前新语言的字符集文件unicharset。同时还会产生图形原型文件inttemp和每个字符所对应的字符
特征数文件pffmtable。最重要的就是这个inttemp文件了,他包含了所有需要产生的字的图形原型。
3)cntraining ec.ufont.exp0.tr
这一步产生字符形状正常化特征文件normproto。
shapeclustering 操作不是必须的,若没有进行此步,在mftraining的时候 会自动进行。
5.改名字
把目录下的unicharset、inttemp、pffmtable、shapetable、normproto这五个文件前面都加上ufont.
6.执行combine_tessdata ufont.
然后把ufont.traineddata放到tessdata目录
注:一定不要忘记加ufont后面的那个点
7.测试
必须确定的是第type 1、3、4、5的数据不是-1,那么一个新的字典就算生成了。
tesseract ec.ufont.exp0.tif papapa -l ufont
tesseract也提出,通过使用多个语言训练库联合使用。如此,新的字体训练库也可以与原有的数据训练库联合使用。如参数 -l 之后 tesseract input.tif output -l eng+newfont。
cntraining和mftraining只能最多采用32个.tr文件,因此,对于相同的字体,你必须从多种语言中,以字体独立的方式,将所有的文件cat到一起来让32种语言结合在一起。cntraining/mftraining以及unicharset_extractor命令行工具必须各自由给定的.tr和.box文件,以相同的顺序,为不同的字体进行不同的过滤。可以提供一个程序来完成以上的事情,并在字符集表中挑出相同字符集。这样会将事情更简单些。
使用jTessBoxEditorFX训练Tesseract-OCR教程的更多相关文章
- tesseract ocr文字识别Android实例程序和训练工具全部源代码
tesseract ocr是一个开源的文字识别引擎,Android系统中也可以使用.可以识别50多种语言,通过自己训练识别库的方式,可以大大提高识别的准确率. 为了节省大家的学习时间,现将自己近期的学 ...
- tesseract-ocr如何训练Tesseract 4.0
引自:https://blog.csdn.net/huobanjishijian/article/details/76212214 原文:https://github.com/tesseract-oc ...
- 用jTessBoxEditorFX训练字库
软件下载:https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/ 官方字库下载:https://github.com/tesser ...
- Tesseract OCR使用介绍
#Tesseract OCR使用介绍 ##目录[TOC] ##下载地址及介绍 官网介绍:http://code.google.com/p/tesseract-ocr/wiki/TrainingTess ...
- Tesseract——OCR图像识别 入门篇
Tesseract——OCR图像识别 入门篇 最近给了我一个任务,让我研究图像识别,从我们项目的screenshot中识别文字信息,so我开始了学习,与大家分享下. 我看到目前OCR技术有很多,最主要 ...
- 开源图片文字识别引擎——Tesseract OCR
Tessseract为一款开源.免费的OCR引擎,能够支持中文十分难得.虽然其识别效果不是很理想,但是对于要求不高的中小型项目来说,已经足够用了. 文字识别可应用于许多领域,如阅读.翻译.文献资料的检 ...
- Tesseract Ocr引擎
Tesseract Ocr引擎 1.Tesseract介绍 tesseract 是一个google支持的开源ocr项目,其项目地址:https://github.com/tesseract-ocr/t ...
- Python下Tesseract Ocr引擎及安装介绍
1.Tesseract介绍 tesseract 是一个google支持的开源ocr项目,其项目地址:https://github.com/tesseract-ocr/tesseract,目前最新的源码 ...
- 孤荷凌寒自学python第八十四天搭建jTessBoxEditor来训练tesseract模块
孤荷凌寒自学python第八十四天搭建jTessBoxEditor来训练tesseract模块 (完整学习过程屏幕记录视频地址在文末) 由于本身tesseract模块针对普通的验证码图片的识别率并不高 ...
随机推荐
- 数据库关闭,shutdown三种语句。
1.shutdown normal 正常方式关闭数据库. 2.shutdown immediate 立即方式关闭数据库. 在SVRMGRL中执行shutdown immedia ...
- python查询mysql并生成excel表
需求说明 开发不愿意单独为某个项目做后台 并且运营那边需要合并多个表的数据 因此找上了我. 要求每周执行一次.月初也执行一次 要查询2个mysql数据库多个表并生成excel表 我的想法 找开发要sq ...
- Redis 5.0.3集群部署
参考文章 https://blog.csdn.net/yyTomson/article/details/85783753 https://www.cnblogs.com/zy-303/p/102731 ...
- 把一个对象转成map对象
import java.lang.reflect.Field;import java.util.HashMap; public class Util { public static HashMap&l ...
- Linux中KVM桥接的配置
Linux中KVM桥接的配置 1. 原理 1.1 说明 在安装一个拥有虚拟化功能的Linux操作系统(此处以CentOS为例),一般我们有两种方法: .在光盘安装的时候安装好虚拟化包或者PXE服务器上 ...
- 使用LFSR搭建误差补偿系统
使用LFSR搭建误差补偿系统 首先弄明白什么是LFSR 线性反馈移位寄存器(LFSR)是内测试电路中最基本的标准模块结构,既用作伪随机测试码产生器,也作为压缩测试结果数据的特征分析器. 一个n阶的LF ...
- centos7 php-apache镜像添加redis/memcache/gd/mysql_pdo/mysqli/imagick
FROM php:5.6-apache-stretch RUN /usr/local/bin/docker-php-ext-install mysqli pdo_mysql; \ && ...
- django template模板 母板 include导入
一,使用{% block name %}{% endblock %}定义一个模板,在模板页面中它的内容为空,在各页面用{% block name %}自己的标签内容{% endblock %}调用. ...
- tomcat中间件提交表单数据量过大警告处理方案
http://www.bubuko.com/infodetail-976418.html http://www.cnblogs.com/yg_zhang/p/4248061.html tomcat中间 ...
- refreshContext(context)方法源码探究
该方法目的是刷新应用上下文,是容器启动最主要的方法,其实现是一个模板方法,内容巨大,所以先看模板方法都做了哪些事,然后再细看每个方法的实现机制. refreshContext(context)方法首先 ...