Oracle优化器基础知识之访问数据的方法
一、访问数据的方法
Oracle访问表中数据的方法有两种,一种是直接表中访问数据,另外一种是先访问索引,如果索引数据不符合目标SQL,就回表,符合就不回表,直接访问索引就可以。
本博客先介绍直接访问数据的方法,下一篇博客在访问索引的方法
1、直接访问数据
Oracle直接访问表中数据的方法又分为两种:一种是全表扫描;另一种是ROWID扫描
1.1 全表扫描
全表扫描是Oracle直接访问数据的一种方法,全表扫描时从第一个区(EXTENT)的第一个块(BLOCK)开始扫描,一直扫描的到表的高水位线(High Water Mark),这个范围内的数据块都会扫描到
全表扫描是采用多数据块一起扫的,并不是一个个数据库扫的,然后我们经常说全表扫描慢是针对数据量很多的情况,数据量少的话,全表扫描并不慢的,不过随着数据量越多,高水位线也就越高,也就是说需要扫描的数据库越多,自然扫描所需要的IO越多,时间也越多
注意:数据量越多,全表扫描所需要的时间就越多,然后直接删了表数据呢?查询速度会变快?其实并不会的,因为即使我们删了数据,高位水线并不会改变,也就是同样需要扫描那么多数据块
1.2 ROWID扫描
ROWID也就是表数据行所在的物理存储地址,所谓的ROWID扫描是通过ROWID所在的数据行记录去定位。ROWID是一个伪列,数据库里并没有这个列,它是数据库查询过程中获取的一个物理地址,用于表示数据对应的行数。
用sql查询:
select t.* , rowid from 表格
随意获取一个ROWID序列:AAAWSJAAFAAAWwUAAA,前6位表示对象编号(Data Object number),其后3位文件编号(Relative file number),接着其后6位表示块编号(Block number), 再其后3位表示行编号(Row number)
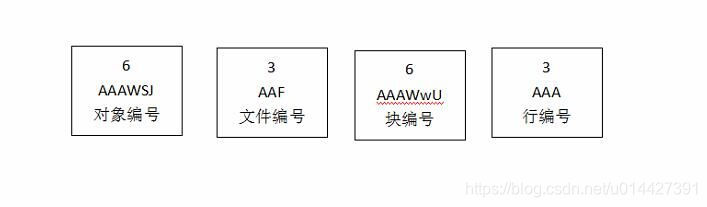
ROWID编码方法是:A ~ Z表示0到25;a ~ z表示26到51;0~9表示52到61;+表示62;/表示63;刚好64个字符。
这里随意找张表查一下文件编号、区编号、行编号,查询后会返回rowid的一系列物理地址和文件编号(rowid_relative_fno(rowid))、块编号(rowid_block_number(rowid))、行编号(rowid_row_number(rowid))
select t.seq,
rowid,
dbms_rowid.rowid_relative_fno(rowid),
dbms_rowid.rowid_block_number(rowid),
dbms_rowid.rowid_row_number(rowid)
from t_info t
SQL查询一下表格名称为TABLE的对象编码
select owner,object_id,data_object_id,status from dba_objects where object_name='TABLE';
相对文件id和绝对文件编码
相对文件id是指相对于表空间,在表空间唯一;绝对文件编码是指相当于全局数据库而言的,全局唯一;下面SQL查询一下相对文件id和绝对文件编码
select file_name,file_id,relative_fno from dba_data_files;
2、访问索引
对于Oracle数据库来说,B树索引是最常见的了,下面给出B树索引的图,图来自《基于Oracle的SQL优化》一书:
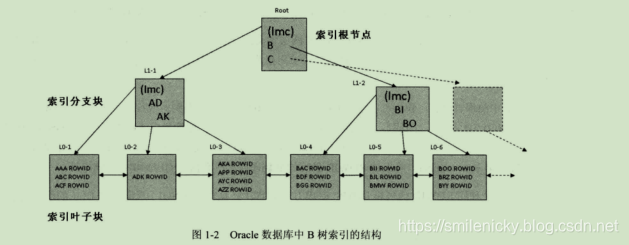
对于B树索引,分成两种类型的数据块,一种是索引分支块,另外一种是索引叶子块,索引根块是一种特殊的索引分支块。
影响逻辑读的缓存:
清Buffer Cache
alter system flush buffer_cache;//请勿随意在生产环境执行此语句
清数据字典缓存(Data Dictionary Cache)
alter system flush shared_pool;//请勿随意在生产环境执行此语句
2.1 索引唯一扫描
索引唯一性扫描(INDEX UNIQUE SCAN)是针对唯一性索引(UNIQUE INDEX)来说的,也就是建立唯一性索引才能索引唯一性扫描,唯一性扫描,其结果集只会返回一条记录。
创建唯一性索引SQL是:
create unique index 索引名 on 表名(列名)
例子,例子来自《基于Oracle的SQL优化》一书:
scott用户登录
SQL> create table emp_temp as select * from emp;//创建一个测试表
SQL> create unique index idx_emp_temp on emp_temp(empno);//创建唯一型索引
SQL> set autotrace on//设置执行计划显示
SQL> select * from emp_temp where empno =7369;//走索引唯一性扫描
EMPNO ENAME JOB MGR HIREDATE SAL COMM
---------- ---------- --------- ---------- -------------- ---------- ----------
DEPTNO
----------
7369 SMITH CLERK 7902 17-12月-80 800
20
执行计划
----------------------------------------------------------
Plan hash value: 3451700904
--------------------------------------------------------------------------------
------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)
| Time |
--------------------------------------------------------------------------------
------------
| 0 | SELECT STATEMENT | | 1 | 87 | 1 (0)
| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP_TEMP | 1 | 87 | 1 (0)
| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN | IDX_EMP_TEMP | 1 | | 0 (0)
| 00:00:01 |
--------------------------------------------------------------------------------
------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("EMPNO"=7369)
2.2 索引范围扫描
索引范围扫描(INDEX RANGE SCAN)适用于所有类型的B树索引,一般不包括唯一性索引,因为唯一性索引走索引唯一性扫描。 当扫描的对象是非唯一性索引的情况,where谓词条件为Between、=、<、>等等的情况就是索引范围扫描,注意,可以是等值查询,也可以是范围查询。如果where条件里有一个索引键值列没限定为非空的,那就可以走索引范围扫描,如果改索引列是非空的,那就走索引全扫描
前面说了,同样的SQL建的索引不同,就可能是走索引唯一性扫描,也有可能走索引范围扫描。在同等的条件下,索引范围扫描所需要的逻辑读和索引唯一性扫描对比,逻辑读如何?索引范围扫描可能返回多条记录,所以优化器为了确认,肯定会多扫描,所以在同等条件,索引范围扫描所需要的逻辑读至少会比相应的唯一性扫描的逻辑读多1
继续上面的例子:
SQL> drop index idx_emp_temp;//删了刚才的唯一性索引
索引已删除。
SQL> create index idx_emp_temp on emp_temp(empno);//创建一个B树索引
索引已创建。
SQL> select * from emp_temp where empno=7369;//走索引范围扫描,因为empno没有限定为非空
EMPNO ENAME JOB MGR HIREDATE SAL COMM
---------- ---------- --------- ---------- -------------- ---------- ----------
DEPTNO
----------
7369 SMITH CLERK 7902 17-12月-80 800
20
执行计划
----------------------------------------------------------
Plan hash value: 351331621
--------------------------------------------------------------------------------
------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)
| Time |
--------------------------------------------------------------------------------
------------
| 0 | SELECT STATEMENT | | 1 | 87 | 2 (0)
| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP_TEMP | 1 | 87 | 2 (0)
| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_EMP_TEMP | 1 | | 1 (0)
| 00:00:01 |
--------------------------------------------------------------------------------
------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("EMPNO"=7369)
Note
-----
- dynamic sampling used for this statement (level=2)
2.3 索引全扫描
索引全扫描(INDEX FULL SCAN)适用于所有类型的B树索引(包括唯一性索引和非唯一性索引)。
索引全扫描过程简述:索引全扫描是指扫描目标索引所有叶子块的索引行,但不意思着需要扫描所有的分支块,索引全扫描时只需要访问必要的分支块,然后定位到位于改索引最左边的叶子块的第一行索引行,就可以利用改索引叶子块之间的双向指针链表,从左往右依次顺序扫描所有的叶子块的索引行
索引全扫描的例子:直接查emp表就好,因为empno是非空的
SQL> select * from emp;
EMPNO ENAME JOB MGR HIREDATE SAL COMM
---------- ---------- --------- ---------- -------------- ---------- ----------
DEPTNO
----------
7369 SMITH CLERK 7902 17-12月-80 800
20
7499 ALLEN SALESMAN 7698 20-2月 -81 1600 300
30
7521 WARD SALESMAN 7698 22-2月 -81 1250 500
30
EMPNO ENAME JOB MGR HIREDATE SAL COMM
---------- ---------- --------- ---------- -------------- ---------- ----------
DEPTNO
----------
7566 JONES MANAGER 7839 02-4月 -81 2975
20
7654 MARTIN SALESMAN 7698 28-9月 -81 1250 1400
30
7698 BLAKE MANAGER 7839 01-5月 -81 2850
30
EMPNO ENAME JOB MGR HIREDATE SAL COMM
---------- ---------- --------- ---------- -------------- ---------- ----------
DEPTNO
----------
7782 CLARK MANAGER 7839 09-6月 -81 2450
10
7788 SCOTT ANALYST 7566 19-4月 -87 3000
20
7839 KING PRESIDENT 17-11月-81 5000
10
EMPNO ENAME JOB MGR HIREDATE SAL COMM
---------- ---------- --------- ---------- -------------- ---------- ----------
DEPTNO
----------
7844 TURNER SALESMAN 7698 08-9月 -81 1500 0
30
7876 ADAMS CLERK 7788 23-5月 -87 1100
20
7900 JAMES CLERK 7698 03-12月-81 950
30
EMPNO ENAME JOB MGR HIREDATE SAL COMM
---------- ---------- --------- ---------- -------------- ---------- ----------
DEPTNO
----------
7902 FORD ANALYST 7566 03-12月-81 3000
20
7934 MILLER CLERK 7782 23-1月 -82 1300
10
已选择14行。
执行计划
----------------------------------------------------------
Plan hash value: 3956160932
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 14 | 532 | 3 (0)| 00:00:01 |
| 1 | TABLE ACCESS FULL| EMP | 14 | 532 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------
2.4 索引快速全扫描
索引快速全扫描和索引全扫描很类似,也适用于所有类型的B树索引(包括唯一性索引和非唯一性索引)。和索引全扫描类似,也是扫描所有叶子块的索引行,这些都是索引快速全扫描和索引全扫描的相同点
索引快速全扫描和索引全扫描区别:
- 索引快速全扫描只适应于CBO(基于成本的优化器)
- 索引快速全扫描可以使用多块读,也可以并行执行
- 索引全扫描会按照叶子块排序返回,而索引快速全扫描则是按照索引段内存储块顺序返回
- 索引快速全扫描的执行结果不一定是有序的,而索引全扫描的执行结果是有序的,因为索引快速全扫描是根据索引行在磁盘的物理存储顺序来扫描的,不是根据索引行的逻辑顺序来扫描的
条件是使用复合索引,而且使用Hint
/*+ index_ffs(表名 索引名) */
select /*+ index_ffs(emp_test pk_emp_test) */ empno from emp_test;
例子:
SQL> create table emp_test (empno number,ename varchar2(50));
表已创建。
SQL> alter table emp_test add constraint pk_emp_test primary key (empno,ename);
表已更改。
SQL> insert into emp_test select empno,ename from emp;
已创建14行。
SQL> commit;
提交完成。
SQL> select count(1) from emp_test;
SQL> select /*+ index_ffs(emp_test pk_emp_test) */ empno from emp_test;
EMPNO
----------
7369
7499
7521
7566
7654
7698
7782
7788
7839
7844
7876
EMPNO
----------
7900
7902
7934
已选择14行。
执行计划
----------------------------------------------------------
Plan hash value: 3550420785
--------------------------------------------------------------------------------
----
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time
|
--------------------------------------------------------------------------------
----
| 0 | SELECT STATEMENT | | 14 | 182 | 2 (0)| 00:00:
01 |
| 1 | INDEX FAST FULL SCAN| PK_EMP_TEST | 14 | 182 | 2 (0)| 00:00:
01 |
--------------------------------------------------------------------------------
----
Note
-----
- dynamic sampling used for this statement (level=2)
2.5 索引跳跃式扫描
索引跳跃式扫描(INDEX SKIP SCAN)适用于所有类型的复合B树索引(包括唯一性索引和非唯一性索引),索引跳跃式扫描可以使那些在where条件中没有目标索引的前导列指定查询条件但是有索引的非前导列指定查询条件的目标SQL依然可以使用跳跃索引,定义解释有点绕,举个例子说明
假如新建了复合索引:
create index 索引名 on 表名(列名1,列名2)
这里新建了复合索引,假如查询如:
select * from 表名 where 列名1 = 条件1
假如改目标SQL符合索引跳跃式扫描的条件,即使,只有列名1这个前导列,还是可以走索引跳跃式扫描的,这个就是跳跃式扫描,不需要如下sql,全部索引列都定位到
select * from 表名 where 列名1 = 条件1 and 列名2 = 条件2
当然索引跳跃式扫描并不是说适用所有情况,不加前导列,有时候是不走跳跃式扫描的,Oracle中的索引跳跃式扫描仅仅适用于那些目标索引前导列的distinct值数量较少,后续非导列的可选择性又非常好的情况,索引跳跃式扫描的执行效率一定会随着目标索引前导列的distinct值数量的递增而递减的
拓展补充
对于索引来说,如果索引条件有null值,是不走索引的
Oracle优化器基础知识之访问数据的方法的更多相关文章
- Oracle 优化器
http://blog.csdn.net/it_man/article/details/8185370一.优化器基本知识 Oracle在执行一个SQL之前,首先要分析一下语句的执行计划,然后再按执 ...
- Oracle优化器介绍
Oracle优化器介绍 本文讲述了Oracle优化器的概念.工作原理和使用方法,兼顾了Oracle8i.9i以及最新的10g三个版本.理解本文将有助于您更好的更有效的进行SQL优化工作. RBO优化器 ...
- ORACLE优化器RBO与CBO介绍总结
RBO和CBO的基本概念 Oracle数据库中的优化器又叫查询优化器(Query Optimizer).它是SQL分析和执行的优化工具,它负责生成.制定SQL的执行计划.Oracle的优化器有两种,基 ...
- Oracle索引梳理系列(一)- Oracle访问数据的方法
版权声明:本文发布于http://www.cnblogs.com/yumiko/,版权由Yumiko_sunny所有,欢迎转载.转载时,请在文章明显位置注明原文链接.若在未经作者同意的情况下,将本文内 ...
- Oracle 优化器_表连接
概述 在写SQL的时候,有时候涉及到的不仅只有一个表,这个时候,就需要表连接了.Oracle优化器处理SQL语句时,根据SQL语句,确定表的连接顺序(谁是驱动表,谁是被驱动表及 哪个表先和哪个表做链接 ...
- [转]ORACLE优化器RBO与CBO的区别
RBO和CBO的基本概念 Oracle数据库中的优化器又叫查询优化器(Query Optimizer).它是SQL分析和执行的优化工具,它负责生成.制定SQL的执行计划.Oracle的优化器有两种,基 ...
- Unity 着色器基础知识
一.着色器基础知识 着色器通过代码模拟物体表面发生的事情,其实就是GPU中运行的一段代码. 着色器的类型: 顶点着色器.片元着色器.无光照着色器.表面着色器.图像特效着色器.计算着色器. 坐标空间: ...
- 多媒体基础知识之PCM数据《 转》
多媒体基础知识之PCM数据 1.什么是PCM音频数据 PCM(Pulse Code Modulation)也被称为脉冲编码调制.PCM音频数据是未经压缩的音频采样数据裸流,它是由模拟信号经过采样.量化 ...
- Python基础知识(六)------小数据池,集合,深浅拷贝
Python基础知识(六)------小数据池,集合,深浅拷贝 一丶小数据池 什么是小数据池: 小数据池就是python中一种提高效率的方式,固定数据类型使用同一个内存地址 代码块 : 一个文 ...
随机推荐
- 探究osg中的程序设计模式【目录】
前序 探究osg中的程序设计模式---开篇 探究osg中的程序设计模式---创造性模式 探究osg中的程序设计模式---创造型模式---Factory(工厂)模式 探究osg中的程序设计模式---创造 ...
- import os, glob, fnmatch--Python os/glob/fnmatch主要函数总结
auther: Lart date: 2019-01-17 update: 2019-01-18 09:55:36 --- import os, glob, fnmatch 针对某些操作, 官方推荐这 ...
- Codeforces 1086D Rock-Paper-Scissors Champion
Description \(N\) 个人排成一排, 每个人都事先决定出剪刀.石头.布. 每次可以任意选两个相邻的人进行决斗. 规则和游戏一样. 但是如果平局, 则掷硬币来决定胜负. 输的人下场. 现要 ...
- 根据select出来的数据进行update
update t_tbl_desc set num=b.num from t_tbl_desc a, (select distinct(name) as name,count(name) num fr ...
- 什么是JavaScript原型
JS 原型 转载自[EC前端 - JavaScript原型] 原型是JavaScript最重要的概念.同时也是初级开发者最忌惮的内容,原因在于网上很少有关于它的合理描述. 但事实上,原型很简单,你可以 ...
- 检测2个url的不同之处(爬虫分析接口)
就是简单的检测2个url的不同之处,在做爬虫时,要分析接口地址的不同之处,靠自己的眼睛有点累,所以写了一个小程序,不喜勿喷 #测试数据 a = "https://list.tmall.com ...
- canvas简易画板。
在学canvas的时候,想到可以做一个自己用来画画的简易画板,加上canvas的基础都已经学完,便尝试做了一个画板.如图 1.获取标签. var c=document.getElementById(' ...
- [总结]给pcDuino v2编译Linux kernel
1.版本问题 推荐选择pcdunio提供的官方的kernel. 当然可以选用www.github.com/linux-sunxi 中的kernel,不过有很多驱动都用不了包括arduino. 我尝试了 ...
- (摘录)Java 详解 JVM 工作原理和流程
作为一名Java使用者,掌握JVM的体系结构也是必须的. 说起Java,人们首先想到的是Java编程语言,然而事实上,Java是一种技术,它由四方面组成:Java编程语言.Java类文件格式.Java ...
- list常用方法
1.切片: ①.顾头不顾尾,从头开始取,但不包括最后一个. ②.从左向右数为正,从零开始,从右开始为负,从-1开始 如: names=['1','2','3'] ames[-1]与names[2]效果 ...