面试(一)-HashMap
一、前言
其实这一面来的挺突然,也是意想不到的,这个要起源于BOSS直聘,很巧,其实也算是一种缘分吧,谢谢BOSS那个哥们,还是那句话来滨江我请你吃饭,身怀感激你总会遇到帮助你的人,只是这个我没有想到,我转Java也没多久,很多东西也没有搞清楚,没想到菜鸟会给我这个电话,内心是震惊的,但是也感谢给我这个机会让我真正认清自己,谢谢菜鸟,那我现在将这份迟到答卷交一交吧。
二、试卷
1、HashMap和Hashtable区别在哪?
2、Synchronized是怎么实现同步的?
3、Spring IOC的启动流程?另外还说一下BeanFactory和ApplicationContext的区别?
4、拦截器和过滤器的区别?
5、单点登录?
6、RabbitMQ怎么保证消息到达的?
这6个问题其实我感觉就第5个问题回答的比较好,剩下都是似懂非懂,这可能是对于我的自满的一个警钟,还是那句话深挖基础,来年再战,接下来我们来用来深耕一下这些问题,给自己再交一份满意的答卷。
第一个问题我们从基层结构、对null值的处理、数据结构以及线程安全这4个方面结合源码来谈一下:
1.继承结构
Map总体继承:
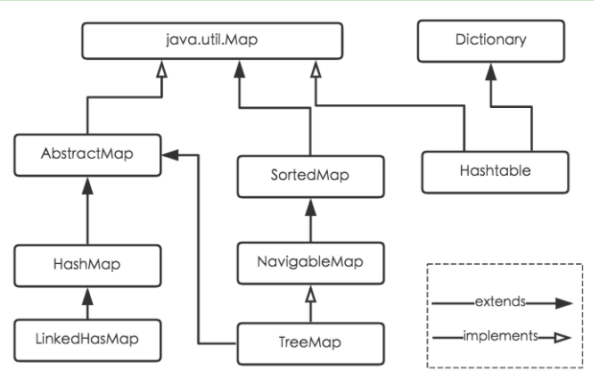
HashMap的继承结构:

HashTable的继承结构:

对比下实现,不同点主要在基类上继承上,对比下暴露出的API主要是Hashtable多elements和contains方法,elemets主要是返回所有的value的值,为空的时候返回空枚举对象,而contains方法和containsValue方法都是查询是否包含value的值,剩下方法基本上都是相同。
2.对null的处理
Hashtable对null的处理,如果发现为null会报空引用异常;
public synchronized V put(K key, V value) {
// value为空引用异常
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
//key计算的时候同样为空引用异常
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}
HashMap对Null的处理以及添加元素的整个流程:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
static final int hash(Object key) {
int h;
//key为null则默认hashcode为0
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//判断一下是否为第一次插入,如果是第一次插入则创建
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//根据键值key计算hash值得到插入的数组索引i,如果table[i]==null,直接新建节点添加
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {//对应的节点存在
Node<K,V> e; K k;
//判断table[i]的首个元素是否和key一样,如果相同直接覆盖value
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 该链为链表,就用链地址法
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
//创建头部链表
p.next = newNode(hash, key, value, null);
//如果个数大于8则转为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//如果key值存在覆盖
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//找到或者新建key和hashcode相等的键值进行插入
if (e != null) { // existing mapping for key
V oldValue = e.value;
//onlyIfAbsent为false或旧值为null时,允许替换旧值
//这个地方有点不明,明明啥时候都为false
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
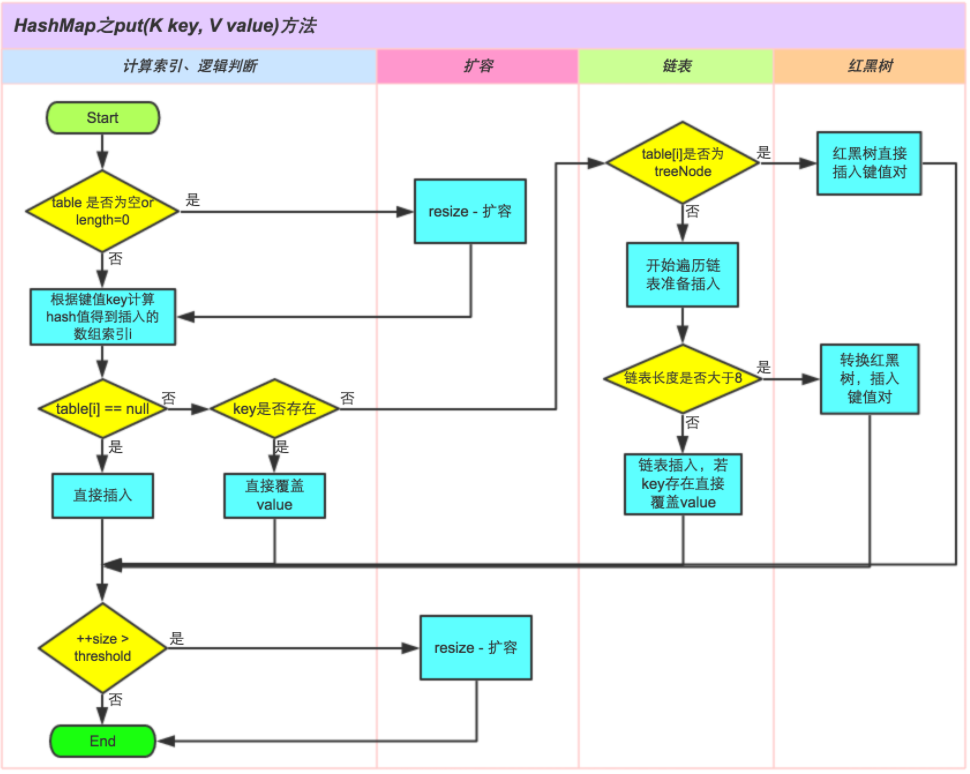
3.数据结构

总体上两者的数据结构都是通过数组+链表实现,但是JDK1.8以后当链表的长度超过8以后会更改为红黑树,都是通过继承Entry数组实现哈希表;
//Hashtable节点定义
private static class Entry<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Entry<K,V> next; protected Entry(int hash, K key, V value, Entry<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
} @SuppressWarnings("unchecked")
protected Object clone() {
return new Entry<>(hash, key, value,
(next==null ? null : (Entry<K,V>) next.clone()));
} // Map.Entry Ops public K getKey() {
return key;
} public V getValue() {
return value;
} public V setValue(V value) {
if (value == null)
throw new NullPointerException(); V oldValue = this.value;
this.value = value;
return oldValue;
} public boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<?,?> e = (Map.Entry<?,?>)o; return (key==null ? e.getKey()==null : key.equals(e.getKey())) &&
(value==null ? e.getValue()==null : value.equals(e.getValue()));
} public int hashCode() {
return hash ^ Objects.hashCode(value);
} public String toString() {
return key.toString()+"="+value.toString();
}
}
//HashMap节点定义
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next; Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
} public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; } public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
} public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
} public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
初始化Hashtable默认初始化的长度为11,加载因子为0.75;HashMap默认为16,加载因子为0.75
扩容Hashtable为2n+1,HashMap为2倍,另外HashMap如果为整数的最大值则就不会扩容,这块是JDK8实现的别的还请自己去查看一下;
另外就是算法问题,JDK8中实现高位运算的算法,相比Hashtable的去模算法来具有更高的效率;具体看下https://tech.meituan.com/java-hashmap.html,
扩容算法也有必要看下;
//Hashtable默认构造函数
public Hashtable() {
this(11, 0.75f);
}
//Hashtable扩容
protected void rehash() {
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table; // overflow-conscious code
//位运算相当于2n+1
int newCapacity = (oldCapacity << 1) + 1;
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
// Keep running with MAX_ARRAY_SIZE buckets
return;
newCapacity = MAX_ARRAY_SIZE;
}
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity]; modCount++;
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
table = newMap; for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next; int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (Entry<K,V>)newMap[index];
newMap[index] = e;
}
}
}
//HashMap扩容
final Node<K,V>[] resize() {
//保存旧的值
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
//如果超过最大的值则碰撞吧
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
//新容量调整旧容量的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
//初始化默认为16
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 计算新的resize上限
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
4.线程安全性
主要针对这块说一说,我就是死在这里的,首先明确的是Hashtable肯定是线程安全的,因为使用Synchronized修饰,所以内部调用的时候是线程安全的;接下主要说下HashMap,这个其实面试官感觉我能回答上来,还好几次问我你确定嘛,我说我确定,哈哈当时也真是,我没说出死循环这个点来,接下来我们分析下为什么会照成死循环?同样上面那个美团技术博客也是有这部分讲解的,这部分JDK8确实写的很麻烦,我们使用JDK7来看下怎么照成的,站到巨人的肩膀上,消化为自己的;
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
以上为主要代码,接下来我们来谈下照成死循环的过程,下面这段代码是主要的罪魁祸首:

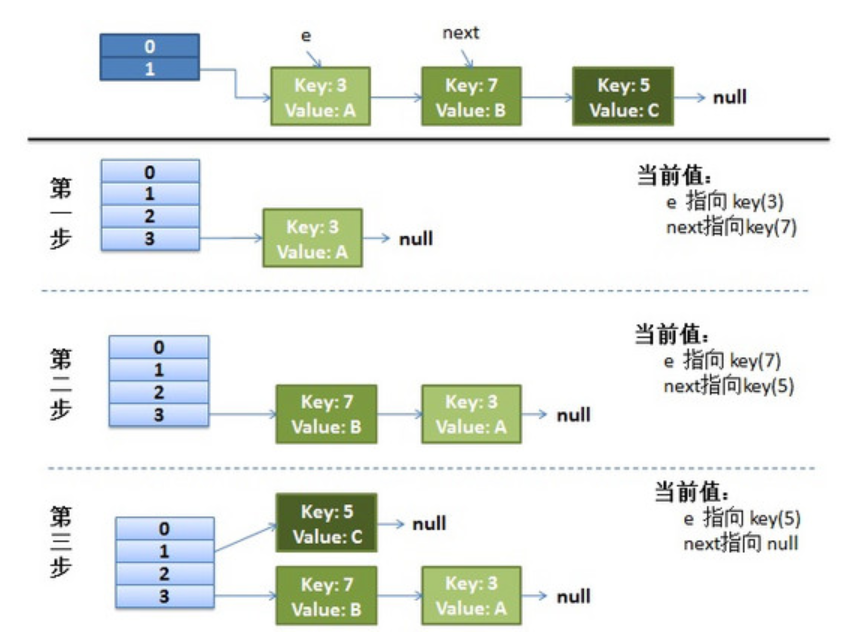
首先来看下单线程下运行状况,代码如下,过程如图:
1.扩容的时候首先遍历数组中的元素;
2.对链表的每一个节点进行遍历,next指向下一个要移动元素,将e转向转向Hash表的头部,使用头插入元素;
3.循环到链表为null结束这次循环;
4.最终等数组循环完毕,完成HashMap扩容;
HashMap<Integer,String> map = new HashMap<>(2,0.75f);
map.put(5, "C");
map.put(7, "B");
map.put(3, "A");
思考一个问题,当多线程操作做时候,这块不是原子操作,所以肯定会出现问题,假设这样一种情况,代码如下:
HashMap<Integer,String> map = new HashMap<>(2,0.75f);
map.put(5, "C");
new Thread("Thread1") {
public void run() {
map.put(7, "B");
System.out.println(map);
};
}.start();
new Thread("Thread2") {
public void run() {
map.put(3, "A");
System.out.println(map);
};
}.start();
map.put(11,"D");
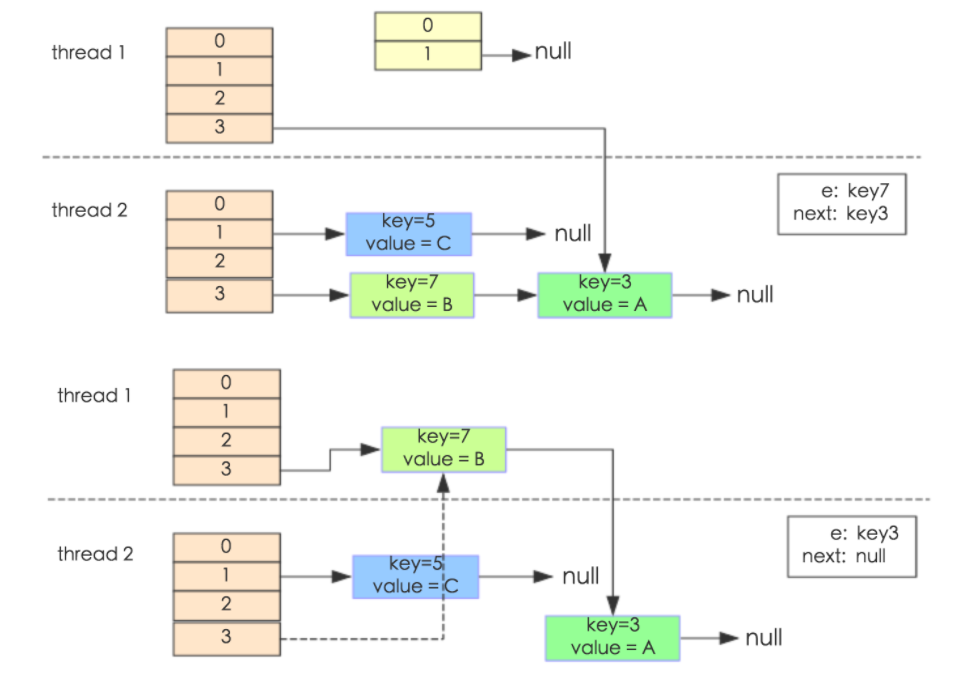
当线程1和线程2同时进入put方法,进入transfer()该方法时候,线程1执行到"Entry<k,v> next = e.next"然后被挂起,线程2开始执行resize()方法,最终形成如下:这部分可以使用多线程调试进行模拟,不会的请参考:http://blog.csdn.net/kevindai007/article/details/71412324
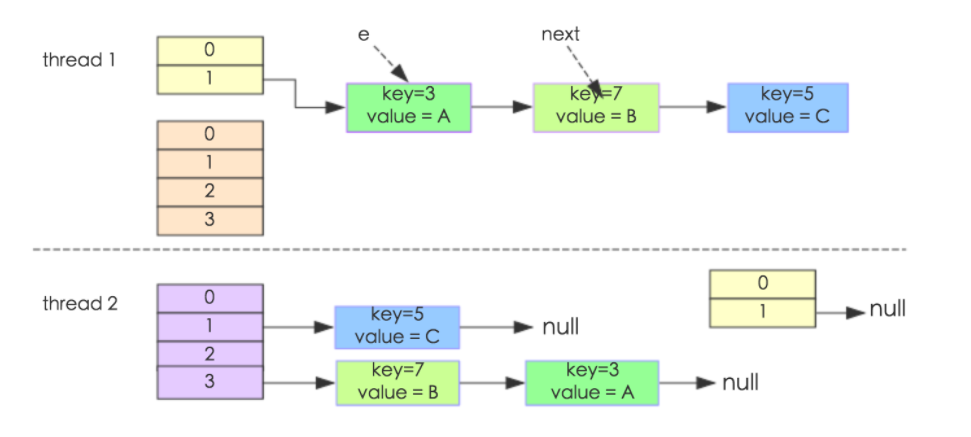
这个时候线程1被唤醒,执行步骤如下:
1.执行e.next = newTable[i],这个时候 key(3)的 next 指向了线程1的新 Hash 表,所以e.next=null;
2.执行newTable[i]=e,e = next,导致e指向了key(7);
3.下一次循环的next = e.next导致了next指向了key(3)。
4.e.next = newTable[i] 导致 key(3).next 指向了 key(7),环形链表就这样出现了。

另外还有一种情况,也就是常见的更新丢失问题的,当2个线程同时插入到数组同一个位置的时候,线程A也写入,线程B也写入,则会照成B写入的覆盖A写入的,照成更新丢失,执行如下代码,这种情况不是很容易出现,多执行几次代码会发现,截图如下:
HashMap<String,String> map=new HashMap<>();
//线程1
Thread t1 = new Thread(){
public void run() {
for(int i=0; i<25; i++){
map.put(String.valueOf(i), String.valueOf(i));
}
}
};
//线程2
Thread t2 = new Thread(){
public void run() {
for(int i=25; i<50; i++){
map.put(String.valueOf(i), String.valueOf(i));
}
}
};
t1.start();
t2.start(); Thread.currentThread().sleep(1000);
//System.out.print(map.values());
for(int i=0; i<50; i++){
//如果key和value不同,说明在两个线程put的过程中出现异常。
if(!String.valueOf(i).equals(map.get(String.valueOf(i)))){
System.err.println(String.valueOf(i) + ":" + map.get(String.valueOf(i)));
}
}
三、结束语
这几个问题要好好深耕一下的话,估计1篇或者几篇是写不完的,我会慢慢写,请大家耐心等待吧,先进行一个预告,下一篇我会再把第一题发散一下:HashMap和ConcurrentHashMap对比,上面有不明白的地方可以找我,QQ群:438836709
面试(一)-HashMap的更多相关文章
- java面试之Hashmap
在java面试中hashMap应该说一个必考的题目,而且HashMap 和 HashSet 是 Java Collection Framework 的两个重要成员,其中 HashMap 是 Map 接 ...
- 面试总结hashmap
考点: 1.hashing的概念 2.HashMap中解决碰撞的方法 3.equals()和hashCode()的应用,以及它们在HashMap中的重要性 4.不可变对象的好处 5.HashMap多线 ...
- 面试中HashMap链表成环的问题你答出了吗
HashMap作为老生常谈的问题,备受面试官的青睐,甚至成为了面试必问的问题.由于大量的针对HashMap的解析横空出世,面试官对HashMap的要求越来越高,就像面试官对JVM掌握要求越来越高一样, ...
- 面试笔记--HashMap扩容机制
转载请注明出处 http://www.cnblogs.com/yanzige/p/8392142.html 扩容必须满足两个条件: 1. 存放新值的时候当前已有元素的个数必须大于等于阈值 2. 存放新 ...
- Android面试之HashMap的实现原理
1.HashMap与HashTable的区别 HashMap允许key和value为null: HashMap是非同步的,线程不安全,也可以通过Collections.synchronizedMap( ...
- 深入解读大厂java面试必考基本功-HashMap集合
课程简介 HashMap集合在企业开发中是必用的集合同时也是面试官面试率很高的集合,因为HashMap里面涉及了很多的知识点,可以比较全面考察面试者的基本功,想要拿到一个好offer,这是一个迈不过的 ...
- 一个HashMap能跟面试官扯上半个小时
一个HashMap能跟面试官扯上半个小时 <安琪拉与面试官二三事>系列文章 一个HashMap能跟面试官扯上半个小时 一个synchronized跟面试官扯了半个小时 一个volatile ...
- HashMap原理阅读
前言 还是需要从头阅读下HashMap的源码.目标在于更好的理解HashMap的用法,学习更精炼的编码规范,以及应对面试. 它根据键的hashCode值存储数据,大多数情况下可以直接定位到它的值,因而 ...
- HashMap实现原理、核心概念、关键问题的总结
简单罗列一下较为重要的点: 同步的问题 碰撞处理问题 rehash的过程 put和get的处理过程 HashMap基础: HashMap的理论基础:维基百科哈希表 JDK中HashMap的描述:Has ...
随机推荐
- awesomium_v1.6.6_sdk 百度云下载地址
awesomium的官网已经关闭很久了,所以找不到正规的下载地址. 而csdn上面的又收费.所以这里提供一个不收费的百度云的下载地址给大家. 不足就是不是1.7版本,所以对于某些有特殊用途的满足不了了 ...
- mssql sqlserver xml数据类型专题
摘要: 下文将详细讲述sql server xml数据类型的相关知识,如下所示: 实验环境: sql server 2008 R2 xml数据类型简介: mssql sqlserver xml数据类型 ...
- IIS ip访问限制插件
Dynamic IP Restrictions Overview The Dynamic IP Restrictions Extension for IIS provides IT Professio ...
- CentOS6.5 安装并配置vsftpd
一.获取root权限 su 输入root密码 二.检查是否安装 rpm -qa | grep vsftpd 如果安装,会显示安装版本号,没有就什么都不显示 三.若已安装过vsftpd,先卸载.卸载前, ...
- LeetCode算法题-Isomorphic Strings(Java实现)
这是悦乐书的第191次更新,第194篇原创 01 看题和准备 今天介绍的是LeetCode算法题中Easy级别的第50题(顺位题号是205).给定两个字符串s和t,确定它们是否是同构的.如果s中的字符 ...
- Kafka如何删除topic?
Kafka如何删除topic? 今天为大家带来“Kafka删除topic原理解析”,希望可以帮到那些苦于无法删除topic的朋友们. 前提条件: 在启动broker时候开启删除topic的开关,即在s ...
- spark program guide
概述 Spark 应用由driver program 组成,driver program运行用户的主函数,在集群内并行执行各种操作 主要抽象RDD: spark提供RDD,是贯穿整个集群中所有节点的分 ...
- ES5-ES6-ES7_数组的扩展
Array.prototype.indexOf(value) 得到值在数组中的第一个下标,如果元素不存在返回-1,可以用来判断是否包含指定的元素 var arr = [6,5,4,3,1,7,6]; ...
- c# 反射 去掉对象中字符串属性多余空格
- 为什么二流程序员都喜欢黑php?
为什么二流程序员都喜欢黑php? 为什么程序员都喜欢黑php?这个嘛!你骂一句php是垃圾试试,保准php程序员不揍扁你!这就好像自己的母校,纵然有很多不好的地方,但是只允许自己调侃,不允许外人骂半句 ...