数据标准化 Normalization
数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。
其中最典型的就是数据的归一化处理,即将数据统一映射到[0,1]区间上,常见的数据归一化的方法有:
min-max标准化(Min-max normalization)
也叫离差标准化,是对原始数据的线性变换,使结果落到[0,1]区间,转换函数如下:
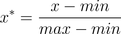
其中max为样本数据的最大值,min为样本数据的最小值。这种方法有一个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。
log函数转换
通过以10为底的log函数转换的方法同样可以实现归一下,具体方法如下:
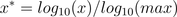
看了下网上很多介绍都是x*=log10(x),其实是有问题的,这个结果并非一定落到[0,1]区间上,应该还要除以log10(max),max为样本数据最大值,并且所有的数据都要大于等于1。
atan函数转换
用反正切函数也可以实现数据的归一化:
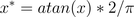
使用这个方法需要注意的是如果想映射的区间为[0,1],则数据都应该大于等于0,小于0的数据将被映射到[-1,0]区间上。
而并非所有数据标准化的结果都映射到[0,1]区间上,其中最常见的标准化方法就是Z标准化,也是SPSS中最为常用的标准化方法:
z-score 标准化(zero-mean normalization)
也叫标准差标准化,经过处理的数据符合标准正态分布,即均值为0,标准差为1,其转化函数为:

其中μ为所有样本数据的均值,σ为所有样本数据的标准差。
数据标准化 Normalization的更多相关文章
- 数据标准化/归一化normalization
http://blog.csdn.net/pipisorry/article/details/52247379 基础知识参考: [均值.方差与协方差矩阵] [矩阵论:向量范数和矩阵范数] 数据的标准化 ...
- 转:数据标准化/归一化normalization
转自:数据标准化/归一化normalization 这里主要讲连续型特征归一化的常用方法.离散参考[数据预处理:独热编码(One-Hot Encoding)]. 基础知识参考: [均值.方差与协方差矩 ...
- sklearn5_preprocessing数据标准化
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- 数据标准化方法及其Python代码实现
数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间.目前数据标准化方法有多种,归结起来可以分为直线型方法(如极值法.标准差法).折线型方法(如三折线法).曲线型方法 ...
- 用SVM处理XSS时,数据清洗打标数据标准化处理的方法和意义
def get_len(url): return len(url) def get_url_count(url): if re.search('(http://)|(https://)', url, ...
- 利用 pandas 进行数据的预处理——离散数据哑编码、连续数据标准化
数据的标准化 数据标准化就是将不同取值范围的数据,在保留各自数据相对大小顺序不变的情况下,整体映射到一个固定的区间中.根据具体的实现方法不同,有的时候会映射到 [ 0 ,1 ],有时映射到 0 附近的 ...
- R实战 第九篇:数据标准化
数据标准化处理是数据分析的一项基础工作,不同评价指标往往具有不同的量纲,数据之间的差别可能很大,不进行处理会影响到数据分析的结果.为了消除指标之间的量纲和取值范围差异对数据分析结果的影响,需要对数据进 ...
- python数据标准化
def datastandard(): from sklearn import preprocessing import numpy as np x = np.array([ [ 1., -1., 2 ...
- Matlab数据标准化——mapstd、mapminmax
Matlab神经网络工具箱中提供了两个自带的数据标准化处理的函数——mapstd和mapminmax,本文试图解析一下这两个函数的用法. 一.mapstd mapstd对应我们数学建模中常使用的Z-S ...
随机推荐
- 非官方windows下Cpython二进制扩展包下载地址
Unofficial Windows Binaries for Python Extension Packages url:http://www.lfd.uci.edu/~gohlke/pythonl ...
- ZooKeeper在centos6.4的集群搭建
首先给一个小tips,在搭建zookeeper之前,需要配置好java环境,请参看我的另一篇文章<Jdk1.8在CentOS7中的安装与配置>,还需要免密码登录,请参看我的另一篇文章< ...
- 【树上莫队】【带修莫队】【权值分块】bzoj4129 Haruna’s Breakfast
#include<cstdio> #include<cstring> #include<algorithm> #include<cmath> using ...
- IOS-synthesize和dynamic的异同(转)
一,retain, copy, assign区别 1. 假设你用malloc分配了一块内存,并且把它的地址赋值给了指针a,后来你希望指针b也共享这块内存,于是你又把a赋值给(assign)了b.此时a ...
- 【技术贴】VirtualBox给VDI格式的虚拟机扩容
新建立了一个虚拟机用来装一些比较烦的软件,比如数据库什么的,但是初始的时候硬盘放小了,找了很久才找到解决方案(我的数据库是动态大小的): 1.直接在虚拟机关闭的状态下,在设置-->存储--> ...
- C语言误区
int date[10] ; //定义一个字长10的数组,从date[0]....date[9] static char c ; //静态变量(有静态外部变量和静态局部变量),静态外部变量 ...
- 从一个Fragment跳转到另一个Fragment
我们知道Activity之间的跳转可以使用 startActivity(intent).但Fragment之间的跳转却不能使用该方法,那该怎么办呢? 直接上代码: 核心代码 @Override//核心 ...
- java servlet 代码样例 (demo)
今天又搞了下jsp +servlet 的代码样例,感觉虽然搭了好多次,可是每次还是不记得那些参数,都要去网上搜索,索性自己把这次的简单demo给记录下来,供下次使用的时候直接复制吧. 这个web逻辑 ...
- Rsync 3.1.0 发布,文件同步工具
文件同步工具Rsync 3.1.0发布.2013-09-29 上一个版本还是2011-09-23的3.0.9 过了2年多.Rsync基本是Linux上文件同步的标准了,也可以和inotify配合做实时 ...
- 跟我一起学WCF(12)——WCF中Rest服务入门
一.引言 要将Rest与.NET Framework 3.0配合使用,还需要构建基础架构的一些部件.在.NET Framework 3.5中,WCF在System.ServiceModel.Web组件 ...