HashMap ConcurrentHashMap解读
前言:
常见的关于HahsMap与ConcurrentHashMap的问题:
数据结构、线程安全、扩容、jdk1.7 HashMap死循环、jdk1.8 HashMap红黑树、容量必须是2的冥次
HashMap
数据结构:数组,单向链表
线程安全:不安全,HashTable线程安全,但是全用了 synchronized ,性能低
一、jdk1.7中
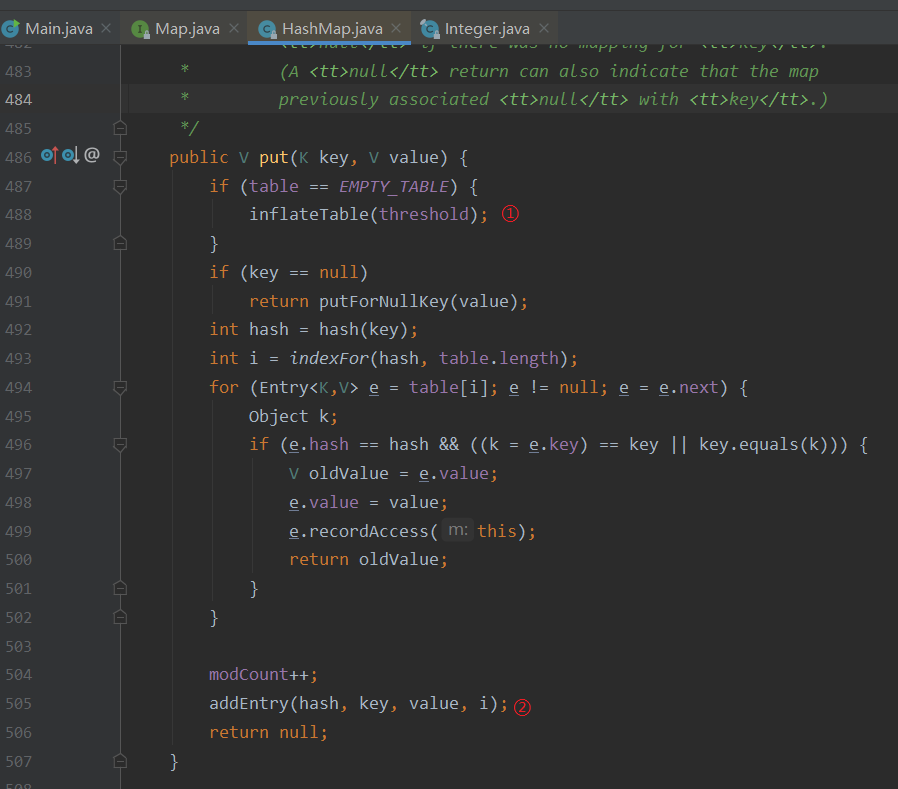
①:对HashMap初始化进行初始化;
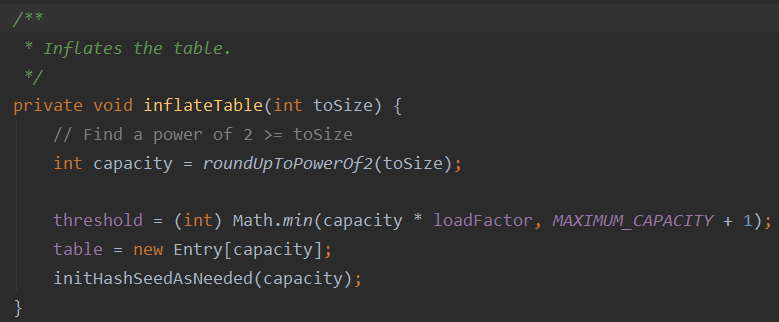
初始化HashMap的 threshold 字段,通过因子算出,默认为0.75,算出来是16 * 0.75为12;
初始化hash种子信息;
保证了HashMap的容量是2的冥次。为什么HashMap的容量必须是2的冥次,因为可以增加有效长度,减少hash碰撞,关于hash碰撞:https://blog.csdn.net/qq_35583089/article/details/80048285
②:添加Entry对象,赋值
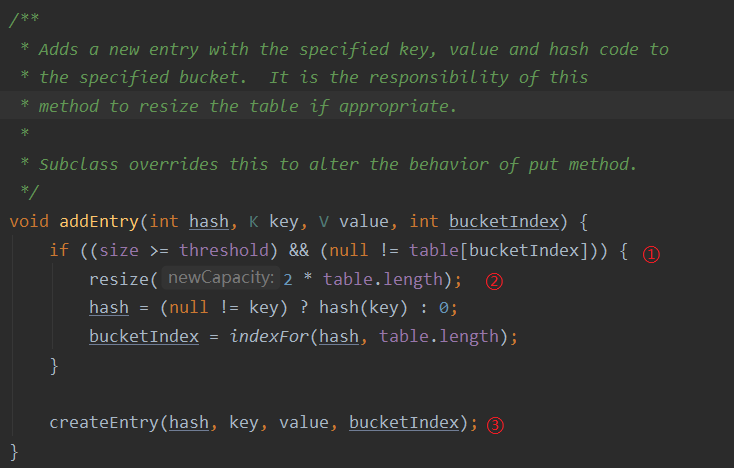
①:判断当前容量是否到达阈值,例如12
②:扩容
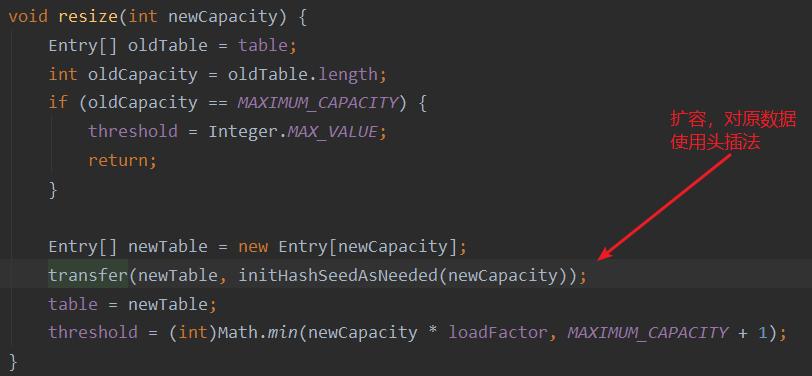
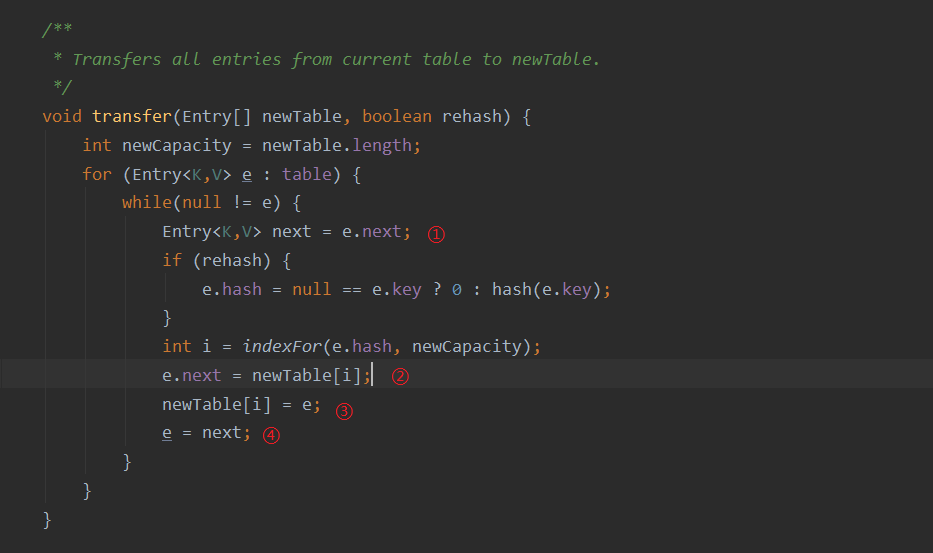
头插法:原先的头会成为新链表的尾部,原先的尾部会成为新链表的头
这里的代码就是为什么不建议并发时使用HashMap的原因,e.next形成死循环,导致CPU 100%卡死,并且线程不安全
二、jdk1.8中
jdk1.8中,当容量超过2的8次方(64)时,使用红黑树替代链表
ConcurrentHashMap
数据结构(jdk1.7):Segment数组,Segment下又有HashEntry,HashEntry为数组+链表
数据结构(jdk1.8):但是在jdk1.8中,起始的数据结构是数组+链表的。但是当单个链表长度
ConcurrentHashMap是一个线程安全的Map类,其通过多个Segment来保存数据,操作不同Segment之间是可以并发的,而操作统计个Segment进行数据的插入时,会进行 ReentrantLock 上锁操作
一、jdk1.7
先看看put方法
public V put(K key, V value) {
ConcurrentHashMap.Segment<K,V> s;
if (value == null)
throw new NullPointerException();
//通过key的hash值算出segment的下标
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (ConcurrentHashMap.Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
//这里会判断对应下标的segment是否存在,不存在会进行初始化
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
下面是Segment.put方法
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
//尝试获得锁,并开始同步
ConcurrentHashMap.HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
ConcurrentHashMap.HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
ConcurrentHashMap.HashEntry<K,V> first = entryAt(tab, index);
for (ConcurrentHashMap.HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
//和HashMap一样,链表使用头插法,后插入的元素永远在数组的最前面
if (node != null)
node.setNext(first);
else
node = new ConcurrentHashMap.HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
//超过Segment阈值时,对HashEntry进行扩容
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
二、jdk1.8
java1.7采用volatile去获取已存在的Segment。java1.8采用的CAS算法,而没用使用Segment进行数据存储
HashMap ConcurrentHashMap解读的更多相关文章
- HashTable & HashMap & ConcurrentHashMap 原理与区别
一.三者的区别 HashTable HashMap ConcurrentHashMap 底层数据结构 数组+链表 数组+链表 数组+链表 key可为空 否 是 否 value可为空 否 是 否 ...
- 深入理解HashMap+ConcurrentHashMap的扩容策略
前言 理解HashMap和ConcurrentHashMap的重点在于: (1)理解HashMap的数据结构的设计和实现思路 (2)在(1)的基础上,理解ConcurrentHashMap的并发安全的 ...
- Jdk8 Hashmap ConcurrentHashMap
JDK1.8 Hashmap JDK1.8 ConcurrentHashMap 不采用segment而采用 synchronized (f) f = table[i]; 减小锁的力度 设计了MOVE ...
- java多线程之hashmap concurrenthashmap的状态同步
最近在高并发的系统中发现,concurrenthashmap除了大家熟知的避免循环期间发生ConcurrentModificationException异常外,还有重要的一点是Retrievals r ...
- HashMap完全解读
一.什么是HashMap 基于哈希表的 Map 接口的实现.此实现提供所有可选的映射操作,并允许使用 null 值和 null 键.(除了非同步和允许使用 null 之外,HashMap 类与 Has ...
- HashMap? ConcurrentHashMap? 相信看完这篇没人能难住你!
前言 Map 这样的 Key Value 在软件开发中是非常经典的结构,常用于在内存中存放数据. 本篇主要想讨论 ConcurrentHashMap 这样一个并发容器,在正式开始之前我觉得有必要谈谈 ...
- ConcurrentHashMap 解读
初始化: 问题:如何当且仅只有一个线程初始化table private final Node<K,V>[] initTable() { Node<K,V>[] tab; int ...
- Java7/8 HashMap ConcurrentHashMap
网上关于 HashMap 和 ConcurrentHashMap 的文章确实不少,不过缺斤少两的文章比较多,所以才想自己也写一篇,把细节说清楚说透,尤其像 Java8 中的 ConcurrentHas ...
- HashMap? ConcurrentHashMap?
前言 Map 这样的 Key Value 在软件开发中是非常经典的结构,常用于在内存中存放数据. 本篇主要想讨论 ConcurrentHashMap 这样一个并发容器,在正式开始之前我觉得有必要谈谈 ...
随机推荐
- app生命周期之即将关闭
需求:当软件正在进行任务还未结束时,如果用户强制退出软件,需要将一些数据进行保存等处理. 策略:当用户使用多任务将软件挂起,并滑掉软件时,接下来有5妙钟的时间留给软件做处理.会调用- (void)ap ...
- Node Sass does not yet support your current environment: Linux 64-bit with Unsupported runtime
环境: ubuntu18 webstorm vue项目 报错原因: 缺少相关依赖 解决方法: npm rebuild node-sass 还未解决: npm uninstall --save node ...
- java事务/springboot事务/redis事务
java事务(数据库事务):jdbc事务--ACID springboot事务:@Transactional--ACID redis事务:命令集合 将redis事务与mysql事务对比: Mysq ...
- Caffe2 模型与数据集(Models and Datasets)[3]
Models and Datasets 这一节没什么有用的信息为了保证教程完整性,这里仍然保留这一节. 这一节唯一提到的一点就是: Caffe2的模型文件后缀是:.pb2 结语: 转载请注明出处:ht ...
- shell脚本中执行shell脚本
1.a.sh #!/bin/sh name="hello" ./b.sh $name 2.b.sh(这里把b.sh与a.sh放在同一目录下,便于演示) #!/bin/sh ech ...
- 【PAT甲级】1025 PAT Ranking (25 分)(结构体排序,MAP<string,int>映射)
题意: 输入一个正整数N(N<=100),表示接下来有N组数据.每组数据先输入一个正整数M(M<=300),表示有300名考生,接下来M行每行输入一个考生的ID和分数,ID由13位整数组成 ...
- 安卓手机的屏幕规格很多。app开发者在设计User Interface的时候,要怎么处理,才能适应不同屏幕大小?
在app store下载应用时经常看到:此App已针对iPhone 5 进行优化.可是Android手机屏幕规格这么多,相差这么远.难道要针对每个尺寸都进行一次优化吗?(题主非专业人士,看到2014年 ...
- 使用eclipse搭建springboot项目pom.xml文件第一行报错(Maven Configuration Problem)
今天在https://start.spring.io/上搭建了一个2.1.5版本的springboot项目,但是把它导入后,pom.xml第一行报错了,查看Problems发现下面的错误 百度后发现方 ...
- Java - 实现双向链表
熟悉一下Java... package ChianTable; import java.util.Scanner; /** * Created by Administrator on 2018/3/2 ...
- R语言 sample抽样函数
Sample 函数用法: sample(x, size, replace = FALSE, prob = NULL) Arguments x - 可以是含有一个或多个元素的向量或只是一个正整数.x的长 ...