【Hadoop离线基础总结】数据仓库和hive的基本概念
数据仓库和Hive的基本概念
数据仓库
概述
数据仓库英文全称为 Data Warehouse,一般简称为DW。主要目的是构建面向分析的集成化数据环境,主要职责是对仓库中的数据进行分析,支持我们做决策。主要特征
面向主题(Subject-Oriented):数据分析有一定的范围,需要选取一定的主题进行分析。
集成性(Integrated):集成各个其他方面关联的数据,比如分析订单购买人的情况,就涉及到用户信息的数据。
非易失性(Non-Volatile):数据分析主要是分析过去已经发生的数据,都是既成的事实,不会再改变
时变性(Time-varient):随着时间的推移发展,数据的形态也在发生变化,数据分析的手段也要相应的改变数据仓库与数据库的区别

数据仓库分层架构
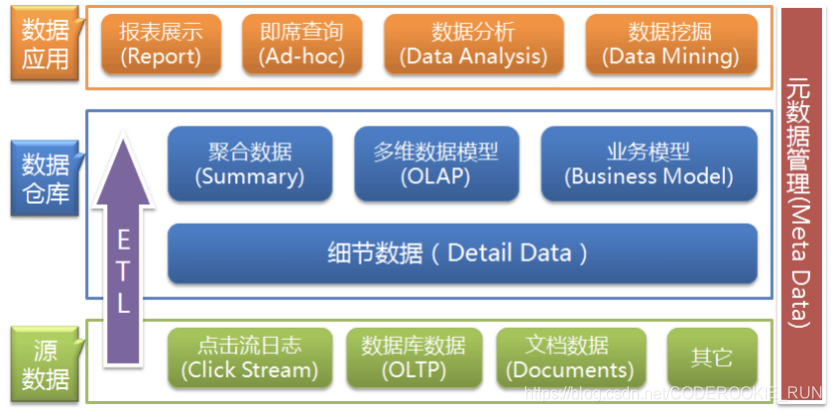
数据仓库架构可分为三层:源数据、数据仓库、数据应用
源数据层(ODS):是产生数据的地方。此层数据直接沿用外围系统数据结构和数据,不对外开放,为临时存储层,是接口数据的临时存储区域,为后一步的数据处理做准备。
数据仓库层(DW):也称为细节层,主要集中存储数据,面向主题进行分析。DW层的数据应该是一致的、准确的、干净的数据,即对源系统数据进行了清洗(去除了杂质)后的数据。
数据应用层(DA/APP):前端应用直接读取的数据源;根据报表、专题分析需求而计算生成的数据,主要用于展示分析之后的数据结果。
ETL(抽取Extract, 转化Transfer, 装载Load):数据仓库从各数据源获取数据及在数据仓库内的数据转换和流动都可以认为是ETL的过程。ETL是数据仓库的流水线,也可以认为是数据仓库的血液,它维系着数据仓库中数据的新陈代谢,而数据仓库日常的管理和维护工作的大部分精力就是保持ETL的正常和稳定。
对数据仓库分层的原因:用空间换时间。通过数据分层管理可以简化数据清洗的过程,也就是把原来一步的工作分到了多个步骤去完成,每一层的处理逻辑都相对简单和容易理解,这样我们比较容易保证每一个步骤的正确性,当数据发生错误的时候,往往我们只需要局部调整某个步骤即可。数据仓库元数据管理
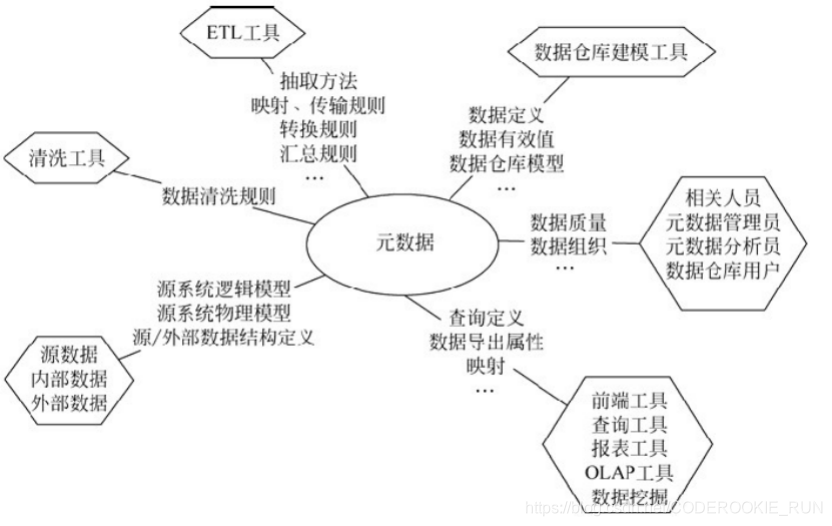
元数据(Meta Date):主要记录数据仓库中模型的定义、各层级间的映射关系、监控数据仓库的数据状态及ETL的任务运行状态。简单来讲,元数据记录了ETL一整套流程。如果要更为 详细地说,元数据定义了源数据系统到数据仓库的映射、数据转换的规则、数据仓库的逻辑结构、数据更新的规则、数据导入历史记录以及装载周期等相关内容。数据抽取和转换的专家以及数据仓库管理员正是通过元数据高效地构建数据仓库。
Hive的基本概念
概述
Hive是基于Hadoop的一个数据仓库处理工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。本质是将sql语句转换成MapReduce的任务进行执行,所以一定程度上可以说hive是MapReduce的一个客户端。结构化、半结构化、非结构化数据
结构化数据:体现为数据字段固定,数据类型固定(数据库的表就是一种最典型的结构化数据)
半结构化数据:XML,JSON,数据类型一定,但是数据的字段个数不定
非结构化数据:完全没有任何规律,字段类型不定、字段个数不定、数据类型不定,比如说音频、视频选择用Hive的原因
直接使用Hadoop的弊端:人员学习成本高、项目周期要求短、MapReduce实现复杂查询逻辑开发难度大
用Hive的好处:操作接口采用类sql语法,提供快速开发的能力。 避免了去写MapReduce,减少开发人员的学习成本。 功能扩展很方便Hive架构
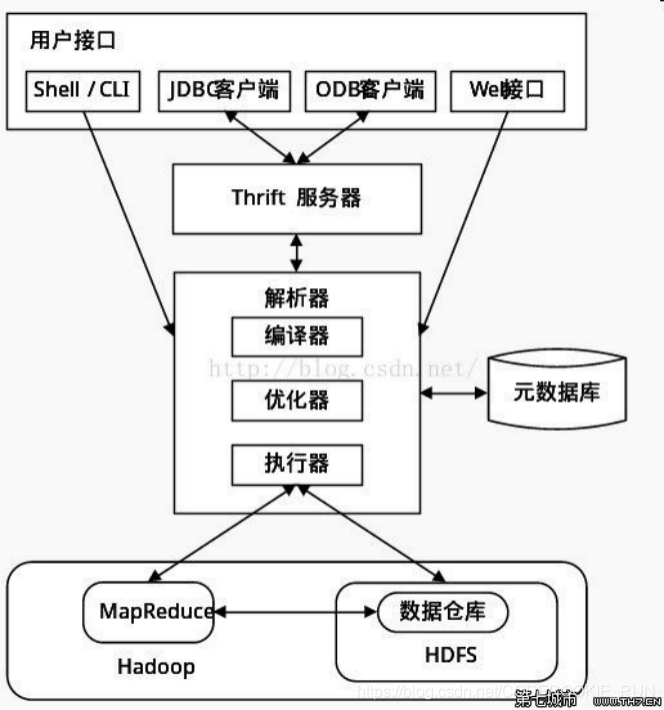
用户接口:就是提供写sql语句的地方。包括CLI、JDBC/ODBC、WebGUI。其中,CLI (command line interface) 为shell命令行;JDBC/ODBC是Hive的JAVA实现,与传统数据库JDBC类似;WebGUI是通过浏览器访问Hive。
解析器:解析sql语句,转换成MepReduce的任务提交并准备执行,是重中之重。
元数据存储:通常是存储在关系数据库如mysql/derby中(Derby不好用,元数据一般都保存在mysql或者oracle中等)。Hive 将元数据存储在数据库中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。Hive与Hadoop的关系

一句话来说明:Hive是MapReduce的一个客户端Hive和传统数据库的对比
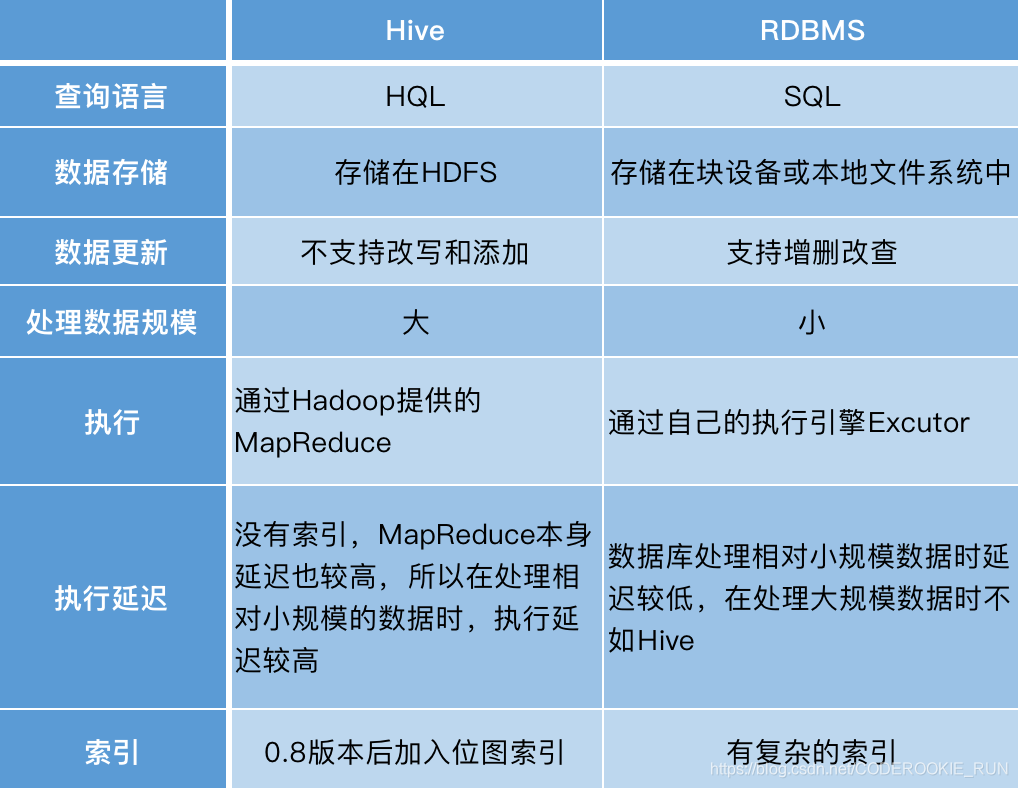
Hive的数据存储
Hive中所有的数据都存储在 HDFS 中,没有专门的数据存储格式(可支持Text,SequenceFile,ParquetFile,ORC,RCFILE等),只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
【Hadoop离线基础总结】数据仓库和hive的基本概念的更多相关文章
- 【Hadoop离线基础总结】Hive调优手段
Hive调优手段 最常用的调优手段 Fetch抓取 MapJoin 分区裁剪 列裁剪 控制map个数以及reduce个数 JVM重用 数据压缩 Fetch的抓取 出现原因 Hive中对某些情况的查询不 ...
- 【Hadoop离线基础总结】流量日志分析网站整体架构模块开发
目录 数据仓库设计 维度建模概述 维度建模的三种模式 本项目中数据仓库的设计 ETL开发 创建ODS层数据表 导入ODS层数据 生成ODS层明细宽表 统计分析开发 流量分析 受访分析 访客visit分 ...
- 【Hadoop离线基础总结】oozie的安装部署与使用
目录 简单介绍 概述 架构 安装部署 1.修改core-site.xml 2.上传oozie的安装包并解压 3.解压hadooplibs到与oozie平行的目录 4.创建libext目录,并拷贝依赖包 ...
- 【Hadoop离线基础总结】Hue的简单介绍和安装部署
目录 Hue的简单介绍 概述 核心功能 安装部署 下载Hue的压缩包并上传到linux解压 编译安装启动 启动Hue进程 hue与其他框架的集成 Hue与Hadoop集成 Hue与Hive集成 Hue ...
- 【Hadoop离线基础总结】impala简单介绍及安装部署
目录 impala的简单介绍 概述 优点 缺点 impala和Hive的关系 impala如何和CDH一起工作 impala的架构及查询计划 impala/hive/spark 对比 impala的安 ...
- 【Hadoop离线基础总结】Sqoop常用命令及参数
目录 常用命令 常用公用参数 公用参数:数据库连接 公用参数:import 公用参数:export 公用参数:hive 常用命令&参数 从关系表导入--import 导出到关系表--expor ...
- 【Hadoop离线基础总结】Hive的基本操作
Hive的基本操作 创建数据库与创建数据库表 创建数据库的相关操作 创建数据库:CREATE TABLE IF NOT EXISTS myhive hive创建表成功后的存放位置由hive-site. ...
- 【Hadoop离线基础总结】Hive的安装部署以及使用方式
Hive的安装部署以及使用方式 安装部署 Derby版hive直接使用 cd /export/softwares 将上传的hive软件包解压:tar -zxvf hive-1.1.0-cdh5.14. ...
- 【Hadoop离线基础总结】Sqoop数据迁移
目录 Sqoop介绍 概述 版本 Sqoop安装及使用 Sqoop安装 Sqoop数据导入 导入关系表到Hive已有表中 导入关系表到Hive(自动创建Hive表) 将关系表子集导入到HDFS中 sq ...
随机推荐
- C - 剪花布条 (KMP例题)
一块花布条,里面有些图案,另有一块直接可用的小饰条,里面也有一些图案.对于给定的花布条和小饰条,计算一下能从花布条中尽可能剪出几块小饰条来呢? Input输入中含有一些数据,分别是成对出现的花布条和 ...
- Cucumber(2)——目录结构以及基本语法
目录 回顾 HelloWorld 扩展 回顾 在上一节中,我大致的介绍了一下cucumber的特点,以及基于ruby和JavaScript下关于cucumber环境的配置,如果你还没有进行相关的了解或 ...
- 详解 NIO流
在观看本篇博文前,建议先观看本人博文 -- <详解 IO流> NIO流: 首先,本人来介绍下什么是NIO流: 概述: Java NIO ( New IO )是从 Java 1.4 版本开始 ...
- [转载]绕过CDN查找真实IP方法总结
前言 类似备忘录形式记录一下,这里结合了几篇绕过CDN寻找真实IP的文章,总结一下绕过CDN查找真实的IP的方法 介绍 CDN的全称是Content Delivery Network,即内容分发网络. ...
- 非常简单的string驻留池,你对它真的了解吗
昨天看群里在讨论C#中的string驻留池,炒的火热,几轮下来理论一堆堆,但是在证据提供上都比较尴尬.虽然这东西很基础,但比较好的回答也不是那么容易,这篇我就以我能力范围之内跟大家分享一下 一:无处不 ...
- tp5--路由的使用方法(深入)
懒得写注释,直接上代码 配置文件Route: <?php use think\Route; //tp5路由测试 //动态注册 //Route::rule('路由表达式','路由地址','请求类型 ...
- 2019-2020-1 20199328《Linux内核原理与分析》第九周作业
笔记部分 2019/11/12 14:45:44 从CPU和内存的角度看linux系统的运行 CPU角度:首先我们进行了系统调度,然后系统进入内核态,把信息压栈,然后我们进行进程管理,由于进入系统调用 ...
- Qt 用户通过对话框选择文件
void class::on_pushButton_clicked() { fileFullPath = QFileDialog::getOpenFileName(this, tr("Sel ...
- Spring5参考指南:Bean作用域
文章目录 Bean作用域简介 Singleton作用域 Prototype作用域 Singleton Beans 中依赖 Prototype-bean web 作用域 Request scope Se ...
- Linux网络服务第五章NFS共享服务
1.笔记 NFS一般用在局域网中,网络文件系统c/s格式 服务端s:设置一个共享目录 客户端c:挂载使用这个共享目录 rpc:111远程过程调用机制 Showmount -e:查看共享目录信息 def ...