某图片站反爬加密字段x-api-key破解
前言
此次逆向的是某“你们都懂”领域的图片站,目前此站限制注册,非会员无法访问;前两天偶然搞到了份邀请码,进入后发现质量还可以,于是尝试爬取,在爬虫编写过程中发现此站点采用了不少手段来阻止自动化脚本(或者重放攻击),可以作为一个比较有代表性的爬虫逆向案例,故记录于此。
分析过程
登录进来后,发现页面显示了一段Loading动画,然后才自上而下加载了出来,右键查看主页源代码
<!DOCTYPE html> <html lang="zh-Hans"> <head> <title>Loading... - Poi</title> <meta charset="utf-8">.......
这里基本就可以确定,是异步加载类的资源站,而且在代码底部还有vendor.js,大概是用vue开发的,传统的页面元素定位法在这里不适用,应该是要找接口了。由于我希望整合进系统(见此前的E站爬虫文章)的爬虫入口是画册页的链接,所以暂时不需要对index页进行分析,开Charles,随便点开一本,找到链接对应的条目,重点关注headers和cookies

首先尝试ctrl c+v大法,直接复制headers和cookies构造一模一样的请求,这招在不少登录验证网站都是有用的,但在此网站并未起效:网站返回了一个友好错误页面,并提示不要搞事情,显然cookies或headers里有某些时变或由算法在本地动态生成的字段。事实上,cookie里的st很明显就是一个时间戳,而其余几个字段也基本都是口令或id的意思,想要了解这些字段的产生,或许得从登录开始分析。
从抓包结果来看,登录分为两个过程,https://xxxx.com/auth/login先GET,然后POST,其中的POST提交为json序列化后的用户名密码数据,GET中的response有set cookie操作,为st和poi_session赋了值,而POST时request携带的cookie依旧是这两个(还有三个谷歌统计的cookies),所以cookies不需太关注。但headers却增加了一个关键字段:

字符串里两个连等号,这基本就是base64编码的标志,但等号却出现在了前面,应该是做了一次逆序,逆序后解码
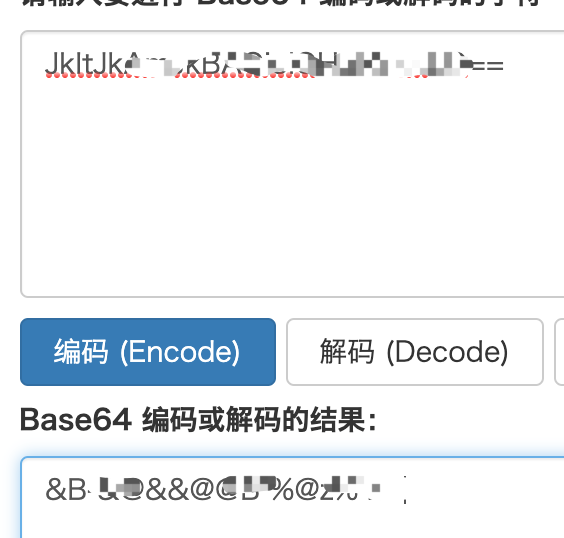
依旧没什么规律,大概率是用js动态生成的,那么想解析就需要找到生成函数和函数传参。回到Charles,在login页面的GET方法时序后,POST前,有三个js文件和一个/env目录的页面被请求了,三个js文件分别是manifest.js, vendor.js和app.js,实锤是拿webpack打包的了,里面都是好几千行,先放在一边;/env请求时发现请求头没有异常的字段,说明x-api-key生成很可能在它之后,此页面返回了一个json, 其中比较引人注意的一个字段是client_secret

哎咋这么眼熟......跟上面我们解码出的base64字符串相比,虽然顺序不一样,但基础字符似乎是一致的,两者之间肯定存在某种联系。
(笔者其实一开始并没有发现这点,到后面找到生成函数才反应过来的)
/env到此已经没什么线索了,login页面本身的<script>标签内也没有什么信息,x-api-key的生成函数只可能位于三个js文件内,app.js是程序入口文件,从这里开始分析是比较合理的,而且这种明显是自创的加密字段也不太可能是第三方库。首先想到的是打断点,但这不是点击事件,单步调试又基本没有可操作性,于是尝试通过关键字定位函数;app.js中搜索x-api-key,然而......并没有,但搜索authtoken是能找到相关函数定义和多出调用的,像这类功能相近的函数没理由分散在不同的文件里。
从另一个角度思考,js语句要在headers里增加一项,除了字段名外,语句里也会出现"headers"字样,那搜索"headers"呢?出现的地方并不多,结果在约3/4的位置找到了这么一段
(function(e){return e.headers.common[atob(atob("V0MxaFVHa3RTMFY1")).toUpperCase()]=t.e()
atob是base64解码函数,把"V0MxaFVHa3RTMFY1"解码两次看看

发现了,这段话就是x-api-key计算的核心语句!接下来看看t和e都是什么。
往上找,跟t最近相关的是这样一段
function() {
var t = this,
e = arguments.length > 0 && void 0 !== arguments[0] ? arguments[0] : 0;
this.initUserState()
.then((function() {
return t.initialized = !0
}))
.catch((function() {
e < 2 && setTimeout((function() {
return t.initUser(++e)
}), 2e3)
}))
}
t = this,所以重点还在e上。本段提到的e显然是一个数值类型,不是方法,继续寻找
由于app.js内大量的变量名重用,通过调用关系定位e()很困难,但根据js内的函数定义风格,e的定义一定是这样的
e:function(){.....
果然查找到了
e: function() {
var t = this.env.client_secret,
e = this.$moment()
.unix() + this.serverTimeOffset,
n = (Math.pow(e, 2) + Math.pow(navigator.userAgent.length, 2))
.toString()
.split("")
.map((function(e) {
return t[e]
}))
.join("");
return btoa(n)
.split("")
.reverse()
.join("")
}
看到这里涉及到了取当前时间戳,浏览器头"user-agent"长度,平方运算,最后把得到的整数分割成单个数字,map取到client_secret的值,而client_secret之前已经获取到了,还差一个serverTimeOffset,搜索后找到它的定义函数
setServerTimeOffset: function() {
var t = Math.floor((window.performance.timing.responseEnd - window.performance
.timing.responseStart) / 1e3) || 0;
t = t >= 0 ? t : 0, this.serverTimeOffset = Number(cookies.get("st")) +
t - this.$moment()
.unix()
}
t由请求报文的时延决定,几百毫秒的延时,运算结果认为是0即可(不严谨,但大多数时候没问题),所以serverTimeOffset就是cookies的st值减去当前时间,到此x-api-key的所有运算参数都获得了,用Python写就是
client_secret = self.env.get("client_secret")
serverTimeOffset=int(self.session.cookies.get("st"))+0-int(time.time())
e = int(time.time())+serverTimeOffset
n = "".join(map(lambda x: client_secret[int(x)], str(pow(e,2)+pow(len(head['user-agent']),2))))
x_api_key = str(base64.b64encode(n.encode("utf-8")), "utf-8")[::-1]
至此x-api-key的构造分析完毕,接下来进入画册详情页的分析。
详情页的headers和cookies未有特别之处,sentinel和auth_token分别在login的POST和GET index页时由set cookie添加。
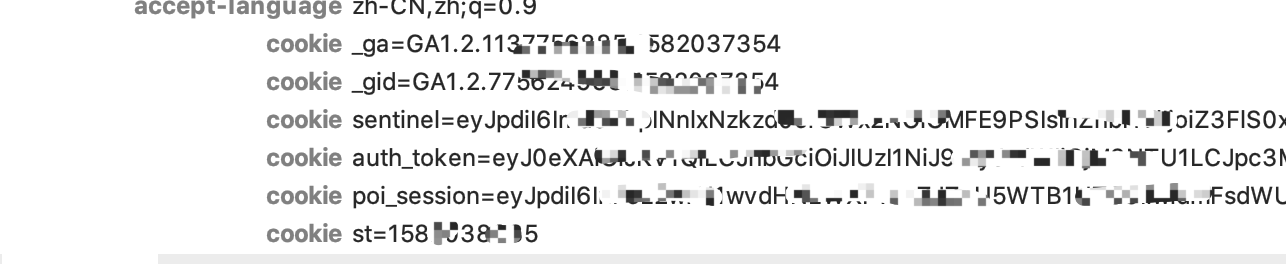
详情页同样是异步加载,内容的接口如下图,用GET方法获取。
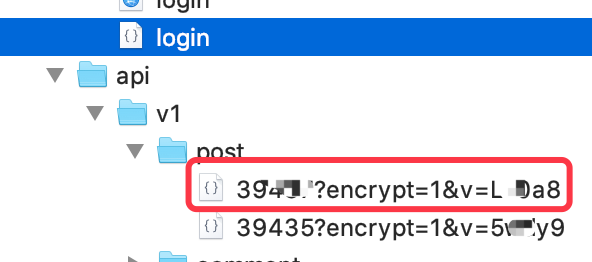
headers部分除了x-api-key外,多了authorization,值就是"Bearer "+auth_token,很简单,但它返回json里的数据有些不是明文

等号在前,果断逆序解码,获得标题。如果没想到逆序的话,在app.js里搜索"encrypt"或"title",也能搜到加解密函数的定义,思想与上面其实是一致的。
图片资源列表也在此json中,以明文储存,虽然不能直接用所给的地址下载图片,但用正则提取出特征码后,即可拼接出真正的图片地址。
最后一个坑在心跳包上,因为笔者发现此网站的每个页面都会隔120s往/heartbeat发一个心跳包,一开始并没在意,后来才发现,heartbeat会更新cookies里的st字段值,x-api-key是用st值算出来的,而每个带x-api-key字段的请求发生时,x-api-key要重新运算更新!如果st的值小于当前时间120秒,那算出来的x-api-key就会非法!表现为在下载完一本漫书(通常耗时超两分钟)后,访问新页面就会401,解决的话倒也不用真2分钟发一次,只需要在请求新页面前几秒发一个心跳包,令st得到更新即可。
2020/03/04更新:/env的返回值里还有一个expired字段,当时间超过expired所指定的时间戳后,auth_token值就会失效,需要再任意请求站内一个页面,来更新auth_token值。
总结
逆向此网站花了一天时间,非专业人员,手法比较生疏,如果说有一些感受,那就是对前后端分离设计的网站,抓包时注意包的时序;定位js函数时,功能相近的很多时候也会写在一起;有些字段找不到时,编码成base64再试试,以及细心观察。
某图片站反爬加密字段x-api-key破解的更多相关文章
- Python爬虫反反爬:CSS反爬加密彻底破解!
刚开始搞爬虫的时候听到有人说爬虫是一场攻坚战,听的时候也没感觉到特别,但是经过了一段时间的练习之后,深以为然,每个网站不一样,每次爬取都是重新开始,所以,爬之前谁都不敢说会有什么结果. 前两天,应几个 ...
- 【Python3爬虫】大众点评爬虫(破解CSS反爬)
本次爬虫的爬取目标是大众点评上的一些店铺的店铺名称.推荐菜和评分信息. 一.页面分析 进入大众点评,然后选择美食(http://www.dianping.com/wuhan/ch10),可以看到一页有 ...
- k 近邻算法解决字体反爬手段|效果非常好
字体反爬,是一种利用 CSS 特性和浏览器渲染规则实现的反爬虫手段.其高明之处在于,就算借助(Selenium 套件.Puppeteer 和 Splash)等渲染工具也无法拿到真实的文字内容. 这种反 ...
- 【Python3爬虫】反反爬之破解同程旅游加密参数 antitoken
一.前言简介 在现在各个网站使用的反爬措施中,使用 JavaScript 加密算是很常用的了,通常会使用 JavaScript 加密某个参数,例如 token 或者 sign.在这次的例子中,就采取了 ...
- 我去!爬虫遇到JS逆向AES加密反爬,哭了
今天准备爬取网页时,遇到『JS逆向AES加密』反爬.比如这样的: 在发送请求获取数据时,需要用到参数params和encSecKey,但是这两个参数经过JS逆向AES加密而来. 既然遇到了这个情况,那 ...
- python爬虫---详解爬虫分类,HTTP和HTTPS的区别,证书加密,反爬机制和反反爬策略,requests模块的使用,常见的问题
python爬虫---详解爬虫分类,HTTP和HTTPS的区别,证书加密,反爬机制和反反爬策略,requests模块的使用,常见的问题 一丶爬虫概述 通过编写程序'模拟浏览器'上网,然后通 ...
- 爬虫入门到放弃系列07:js混淆、eval加密、字体加密三大反爬技术
前言 如果再说IP请求次数检测.验证码这种最常见的反爬虫技术,可能大家听得耳朵都出茧子了.当然,也有的同学写了了几天的爬虫,觉得爬虫太简单.没有啥挑战性.所以特地找了三个有一定难度的网站,希望可以有兴 ...
- python高级—— 从趟过的坑中聊聊爬虫、反爬以及、反反爬,附送一套高级爬虫试题
前言: 时隔数月,我终于又更新博客了,然而,在这期间的粉丝数也就跟着我停更博客而涨停了,唉 是的,我改了博客名,不知道为什么要改,就感觉现在这个名字看起来要洋气一点. 那么最近到底咋不更新博客了呢?说 ...
- Python爬虫——反爬
反爬概述 网络爬虫,是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成. 但是当网络爬虫被滥用后,互联网上就出现太多同质的东西,原创得不到保护. 于是,很多网站开始反网络爬 ...
随机推荐
- 一条sql关联删除多张表数据
现有6张表存在关联关系,要删除主表则其他5张表关联数据也要一块删掉(单条sql多id批量删除) delete t1,t2,t3,t4,t5,t6 FROM rmd_v AS t1 LEFT JOIN ...
- windows10+apache2.4+python3.6部署Django2.2.4项目
刚从家回来,老师让写专利,就开始准备写,初稿交给老师后,把我说了一顿,我就想着回去改呀,然后...老师找到了我,说是食品院那急需一个展示数据的平台,然我尽快干出来,我也是菜鸟啊,就没单独干过呀,即使是 ...
- Linux服务器性能查看命令
一.uptime命令 [root@#test~]# uptime15:26:42 up 101 days, 18:44, 3 users, load average: 0.18, 0.22, 0. ...
- linux进程(一)
回顾:CentOS6的启动过程开机自检->找硬盘->操作系统->内核->进程->登录 Systemd借鉴了很多launchd的思想,他的重要特性如下:1.同SysVini ...
- django框架进阶-ModelForm组件-长期维护
############################################################ """ 通常在Django项目中,我们编写的大部 ...
- IntelliJ IDEA 的便捷操作性
快捷键 说明 IntelliJ IDEA 的便捷操作性,快捷键的功劳占了一大半,对于各个快捷键组合请认真对待.IntelliJ IDEA 本身的设计思维是提倡键盘优先于鼠标的,所以各种快捷键组合层出不 ...
- mysql简介/安装以及破解密码等
1.什么是数据库: 数据库即存放数据的仓库,只不过这个仓库是在计算机存储设备上,而且数据是按一定的格式存放的 过去人们将数据存放在文件柜里,现在数据量庞大,已经不再适用 数据库是长期存放在计算机内.有 ...
- Web服务器的配置与管理
Web服务器的配置与管理(2) 虚拟主机技术 在上篇博文中,我们已经利用IIS搭建好了一台Web服务器,并可以成功访问IIS中自带的默认站点,那么我们是否可以在这台服务器中再创建另外一个Web站点?也 ...
- HDU-1425-sort(计数排序以及快速排序和堆排序的变种)
计数排序 Accepted 1425 483MS 5276K 997 B G++ #include "bits/stdc++.h" using namespace std; typ ...
- BZOJ 1~10 精简题解
从这星期起,我开始了怒刷BZOJ的旅程.这几天刷了10道题(由于"档期"的原因,所以有几道题没打完-..捂脸--..) 精简题解: 1000 A+B Problem --.. [B ...