python之循删list
先来看下循环遍历删除list元素的一段代码:
L=[1,3,1,4,3,6,5]
# 0 1 2 3 4 5 6(下标)
for i in L:
if i%2!=0:#%表示除商取余数,除以2余数为0,则表示为偶数,反之为奇数
L.remove(i)#若是奇数,则从list中剔除
print(L)
运行结果是:
[1, 2, 4]
想一下,1是奇数,为什么没有被删除?
逐步来分析下,首先取第一元素i=1(下标为0),判断1%2!=0条件成立,所以剔除1,这时L变为L1=[1,1,2,3,4,5]。这时第二个1的下标变成0了,for循环已经取过下标0的元素了,所以后面取值时会跳过L1中的第一个元素1。so切记:循环list时不要删除list中的元素,否则会导致下标错位,结果异常。
如果你非要循环删除list中元素,可以定义两个一样的list,如下所示:
L=[1,1,1,2,3,4,5]
# 0 1 2 3 4 5 6
L2=[1,1,1,2,3,4,5]#与L中元素下标一样
for i in L2:#从L2中循环,从L中删除元素
if i%2!=0:
L.remove(i)
print(L)
运行结果为:
[2, 4]
#循环遍历过程中,L2列表一直未改变,只删除L中的元素,这样保证了每次循环时下标未变。
将上述代码中,分别定义了两个一样的list,如果改成L2=L,运行下面程序,你会发现结果还正确吗?
L=[1,1,1,2,3,4,5]
# 0 1 2 3 4 5 6
# L2=[1,1,1,2,3,4,5]
L2=L
for i in L2:
if i%2!=0:
L.remove(i)
print(L)
运行结果:
[1, 2, 4]
可以看出,定义两个一样的list和L2=L,运行的结果不同,这就涉及到浅拷贝和深拷贝的概念。
定义的变量存储在内存中,实际上变量名存放的是内存地址,数据存放在另一块区域。从变量名找到存放数据的内存地址,就可以找到数据。
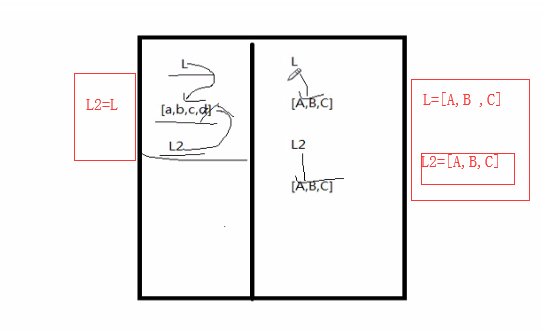
浅拷贝:L2=L或L2=L.copy(),这种方式,L2和L都指向同一块内存地址,所以L中元素被删除时,L2也是改变的。print(id())可打印内存地址
深拷贝:import copy这个模块,即L2=copy.deepcopy(L),L2和L的内存地址不一样,在内存中重新分配一个内存地址给L2.所以两个互不影响。
python之循删list的更多相关文章
- python while循环与for循环
今天刚看了一下python的while和for循环,所以打算记录一下: while语句是python中的循环条件语句,while 判断条件 : pass break 例如: i = 1 sum = 1 ...
- python while循坏和for循坏
while循坏 while 条件: 条件成立,执行循坏体(注意,while循坏必须有结束条件,不然会进入死循坏) 简单做个演示: # -*- coding:utf-8 -*- # Author:覃振鸿 ...
- python中的生成器
什么是生成器? 生成器是一个包含了特殊关键字yield的函数.当被调用的时候,生成器函数返回一个生成器.可以使用send,throw,close方法让生成器和外界交互. 生成器也是迭代器,但是它不仅仅 ...
- python 之编码问题详解
前在一个项目中遇到用post提交一个xml,xml中含有中文,对于单独的py文件,使用urllib2.urlopen完全ok,但在django中使用就一直报编码错误,然后在网上看到这篇文章不错,决定m ...
- Python学习--13 文件I/O
Python内置了读写文件的函数,用法和C是兼容的. 读写文件前,我们先必须了解一下,在磁盘上读写文件的功能都是由操作系统提供的,现代操作系统不允许普通的程序直接操作磁盘,所以,读写文件就是请求操作系 ...
- python学习笔记——列表操作
python列表操作——增 append:追加一条数据到列表的最后 name = ["Zhangsan","XiongDa","Lisi"] ...
- Python编码规范(PEP8)
Introduction 介绍 本文提供的Python代码编码规范基于Python主要发行版本的标准库.Python的C语言实现的C代码规范请查看相应的PEP指南1. 这篇文档以及PEP 257(文档 ...
- Python PEP 8 编码规范中文版
原文链接:http://legacy.python.org/dev/peps/pep-0008/ 转发链接:https://blog.csdn.net/ratsniper/article/detail ...
- python 编码规范起源:PEP8 编码规范中文版
PEP: 8 标题: Python代码的样式指南 版: c451868df657 最后修改: 2016-06-08 10:43:53 -0400(2016年6月8日星期三) 作者: Guido van ...
随机推荐
- Linux相关笔记
vim下 r /etc/hosts 会把这个文件读进来 r! df -Th 会把执行的内容读取进来 查找 / ? 替换:s/old/new/g 2到9行替换2,9s/old/new/g 全部替换 ...
- @Autowired的几个使用细节
1.使用@Autowired的当前类也必须由spring容器托管(打@Coponent.@Controller.@Service .@repository) 2.不管是public 和 privat ...
- 干货 | CDN搭配OSS最佳实践 ——搭建动静态分离的应用架构
一.传统架构及痛点 传统的网站产品应用架构,所有资源部署在应用服务器本地存储或挂载的数据存储区,对于动静态资源不作分离, 产品架构如下图所示: 该架构存在诸多问题: ● 系统性能会随着系统访问量的增长 ...
- textarea高度自适应解决方法
引入autosize.js <script src="./autosize.js"></script> autosize(document.getEleme ...
- 14)载入png图片
1)之前在窗口中载入图片 一般都是bmp的 但是 我想从网上下一些图片,这些图片可能是png的 2)那么就有了下面的操作 3)png图片可以直接做成透明的. 4)首先是创建窗口的基本代码: #i ...
- 对于centos的运用ssh远程连接
1,首先安装ssh服务器 $yum install openssh-server 2,记录你当前centos的ip地址 $ifconfig 3,再在windows里面安装putty 4安装完成后, 在 ...
- XssFilter EscapeUtil
package com.ruoyi.framework.config; import java.util.HashMap; import java.util.Map; import javax.ser ...
- PAT Advanced 1092 To Buy or Not to Buy (20) [Hash散列]
题目 Eva would like to make a string of beads with her favorite colors so she went to a small shop to ...
- python函数中的参数(关键字参数,默认参数,位置参数,不定长参数)
默认参数:定义函数的时候给定变量一个默认值. def num(age=1): 位置参数:调用函数的时候根据定义函数时的形参位置和实参位置进行引用. 关键字参数:如果定义的函数中含有关键字参数,调用函数 ...
- 题解 P6005 【[USACO20JAN]Time is Mooney G】
抢第一篇题解 这题的思路其实就是一个非常简单的dijkstra,如果跑到第一个点的数据不能更新的时候就输出 很多人不知道要跑多少次才停.其实这题因为答案要减去 T*c^2,而每条边的值 <= 1 ...