一个完整的机器学习项目在Python中演练(三)
大家往往会选择一本数据科学相关书籍或者完成一门在线课程来学习和掌握机器学习。但是,实际情况往往是,学完之后反而并不清楚这些技术怎样才能被用在实际的项目流程中。就像你的脑海中已经有了一块块”拼图“(机器学习技术),你却不知道如何讲他们拼起来应用在实际的项目中。如果你也遇见过同样的问题,那么这篇文章应该是你想要的。本系列文章将介绍一个针对真实世界实际数据集的完整机器学习解决方案,让你了解所有部分如何结合在一起。
本系列文章按照一般机器学习工作流程逐步进行:
- 数据清洗与格式处理
- 探索性数据分析
- 特征工程和特征选取
- 机器学习模型性能指标评估
- 微调最佳模型(超参数)
- 在测试集上评估最佳模型
- 解释模型结果
- 总结分析
通过完成所有流程,我们将看到每个步骤之间是怎么联系起来的,以及如何在Python中专门实现每个部分。该项目在GitHub上可以找到,附实现过程。本篇文章将详细介绍第四-五个步骤,剩下的内容将在后面的文章中介绍。前三个步骤详见:数据清洗与格式处理、探索性数据分析、特征工程和特征选取。
模型评估和模型选择
需要时刻注意的是,我们正在解决的是一项有监督回归任务:使用纽约市建筑的能源数据,开发一个能够预测建筑物能源之星评分的模型。预测的准确性和模型的可解释性是最重要的两个指标。
从大量现有的机器学习模型中选择出适用的模型并不是一件容易的事。尽管有些“模型分析图表”(如下图)试图告诉你要去选择哪一种模型,但亲自去尝试多种算法,并根据结果比较哪种模型效果最好,也许是更好的选择。机器学习仍然是一个主要由经验(实验)而不是理论结果驱动的领域,事先就知道哪种模型最好,几乎是不可能的。
(来源:https://docs.microsoft.com/en-us/azure/machine-learning/studio/algorithm-cheat-sheet)
一般来说,可以从简单的可解释模型(如线性回归)开始尝试,如果发现性能不足再转而使用更复杂但通常更准确的模型。一部分模型的准确性与可解释性关系(无科学依据)如下:
(来源:http://blog.fastforwardlabs.com/2017/09/01/LIME-for-couples.html)
我们将评估涵盖复杂模型的五种不同模型:
- 线性回归(LR)
- K-近邻(KNN)
- 随机森林(RF)
- 梯度提升(GBM)
- 支持向量机(SVM)
在这篇文章中,我们将重点介绍这些方法的使用,而不是其背后的理论。对于想学习模型背后理论的朋友,可以看这两本书–“统计学习简介”(在线免费:http://www-bcf.usc.edu/~gareth/ISL/)或“Hands-On Machine Learning with Scikit-Learn and TensorFlow”(http://shop.oreilly.com/product/0636920052289.do)。
缺失值填补
虽然我们在数据清洗的时候丢弃了含有超过50%缺失值的列,但仍有不少值缺失。机器学习模型无法处理任何含缺失值的数据,因此我们必须设法天秤那个它们。这个过程被称作“插补”。
首先,读入所有数据并输出数据规模:
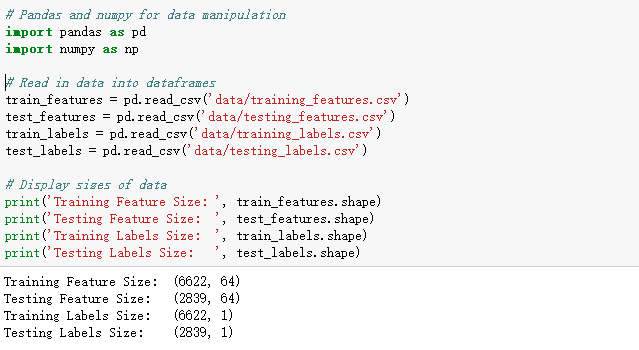
每一个NaN代表一个缺失对象。有着多种方法可以填补缺失数据(https://www.omicsonline.org/open-access/a-comparison-of-six-methods-for-missing-data-imputation-2155-6180-1000224.php?aid=54590),这里使用一种一种相对简单的方法–中值插补法。通过使用这个方法,每一列中的缺失对象都会被该列的中值所替换列。
在下面的代码中,我们借用Scikit-Learn库中封装好的函数创建了一个以“中值替换”(median)为填补策略的Imputer对象。然后,在训练集上(使用imputer.fit函数)上训练这个对象,并用imputer.transform函数填充所有数据(训练集+测试集)中的缺失值。也就是说,测试集中的缺失值也会被相对应训练集中的中值所填充。
(以这样的方式做“插补”是很有必要的,若是对所有数据进行训练以得出中值可能造成“测试数据泄漏”(详见:https://www.kaggle.com/dansbecker/data-leakage)问题–测试集中的信息有可能溢出到训练数据中。)

过处理后,所有特征都不再含有缺失值。
特征缩放
特征缩放是一种用于标准化自变量或数据特征范围的方法。在数据处理中,它也被称为数据标准化。数据中的各项特征是以不同单位测量得到的,因此涵盖了不同的范围,所以进行特征缩放是很有必要的。诸如支持向量机和K近邻这些会考虑各项特征之间距离的方法显著地受到这些特征范围的影响,特征缩放对这些模型来说是很重要的,进行特征缩放使得他们能够学习数据特征。尽管像线性回归和随机森林等方法实际上并不需要特征缩放,但在比较多种算法时进行这一步骤仍然是最佳选择。
接下来通过“将每个特征值放置在0到1之间”来缩放特征。具体来说,我们先获取每个特征的每一个值,然后减去对应特征的最小值并除以特征值区间(区间=最大值减最小值)来完成。这种操作在特征缩放中通常被称为归一化(normalization),另一个主要方法是标准化(standardization)。
尽管这个过程很容易手动实现,但这里我们可以使用Scikit-Learn中的MinMaxScale函数实现。此方法的代码与插补相似。同样地,我们仅使用训练数据进行训练,然后转换所有数据(训练集+测试集)。

现在,数据中每个特征值最小为0最大为1。缺失值填补和特征缩放几乎在完成所有机器学习任务中都需要做的两个步骤。
在Scikit-Learn中实现机器学习模型
在完成所有数据清洗与格式化工作后,实际模型创建、训练和预测工作反而相对简单。这里在Python中使用Scikit-Learn库完成接下来的工作。Scikit-Learn有着完善的帮助文档和统一的模型构建语法。一旦你了解如何在Scikit-Learn中创建模型,那么很快就可以快速实现各种算法。
接下来以梯度提升法(Gradient Boosting Regressor)为例演示模型创建、训练(使用.fit函数)和预测(使用.predict函数)。代码如下:


模型创建、训练和测试都是通过一行代码就可以实现。同理,我们构造了其它模型,只改变名称。结果如下:

我们之前使用目标中值计算的基线(baseline)为24.5,从上图中可以很清晰的对比模型表现。显然,机器学习的表现比基线(baseline)有了显著的改进,它适用于我们的问题。
梯度增加法(GBM)的平均绝对误差(MAE = 10.013)微小的领先击败了随机森林(RF:MAE=10.014)。值得注意的是,由于我们使用超参数的默认值,所以这些结果并不完全代表模型最终的表现。尤其是诸如支持向量机(SVM)这类模型,它们的性能高度依赖于这些超参数设置。尽管如此,通过上图中的表现对比分析,我们还是选择梯度提升回归模型并在接下来的步骤中对其进行优化处理。
模型优化之超参数调整
对于机器学习任务,在选择了一个模型后我们可以针对我们的任务调整模型超参数来优化模型表现。
首先,超参数是什么,它们与普通参数有什么不同?
- 模型超参数通常被认为是数据科学家在训练之前对机器学习算法的设置。例如:随机森林算法中树的个数或K-近邻算法中设定的邻居数。
- 模型参数是模型在训练期间学习的内容,例如线性回归中的权重。
超参数的设定影响着模型“欠拟合”与“过拟合”的平衡,进而影响模型表现。欠拟合是指我们的模型不足够复杂(没有足够的自由度)去学习从特征到目标特征的映射。一个欠适合的模型有着很高的偏差(bias),我们可以通过增加模型的复杂度来纠正这种偏差(bias)。
过拟合是指我们的模型过渡记忆了训练数据的情况。过拟合模型具有很高的方差(详见:https://en.wikipedia.org/wiki/Bias%E2%80%93variance_tradeoff)。针对这种情况,我们可以通过正则化来限制模型的复杂度来纠正。“欠拟合”和“过拟合”在测试集上都不会有较好的表现。
对于每一个机器学习问题,都有着特有的最优超参数组合。因此,找到最佳超参数设置的唯一方法就是尝试多种超参数设置来分析哪一个表现最佳。幸运的是,Scikit-Learn中有多种方法可以让我们高效地评估超参数。此外,也有一些其他的方式选取最优超参数,例如Epistasis Lab的TPOT(https://epistasislab.github.io/tpot/)等项目正试图使用遗传算法等方法优化超参数搜索。有兴趣的可以了解一下。本项目中将使用Scikit-Learn实现最优超参数选取。
本篇主要介绍了机器学习模型性能指标评估与部分模型超参数调整概念,下篇将详细介绍模型超参数调整与模型在测试集上的评估。
一个完整的机器学习项目在Python中演练(三)的更多相关文章
- 一个完整的机器学习项目在Python中演练(四)
大家往往会选择一本数据科学相关书籍或者完成一门在线课程来学习和掌握机器学习.但是,实际情况往往d是,学完之后反而并不清楚这些技术怎样才能被用在实际的项目流程中.就像你的脑海中已经有了一块块" ...
- 一个完整的机器学习项目在Python中的演练(二)
大家往往会选择一本数据科学相关书籍或者完成一门在线课程来学习和掌握机器学习.但是,实际情况往往是,学完之后反而并不清楚这些技术怎样才能被用在实际的项目流程中.就像你的脑海中已经有了一块块"拼 ...
- 一个完整的机器学习项目在Python中的演练(一)
大家往往会选择一本数据科学相关书籍或者完成一门在线课程来学习和掌握机器学习.但是,实际情况往往是,学完之后反而并不清楚这些技术怎样才能被用在实际的项目流程中.就像你的脑海中已经有了一块块"拼 ...
- Sklearn 与 TensorFlow 机器学习实战—一个完整的机器学习项目
本章中,你会假装作为被一家地产公司刚刚雇佣的数据科学家,完整地学习一个案例项目.下面是主要步骤: 项目概述. 获取数据. 发现并可视化数据,发现规律. 为机器学习算法准备数据. 选择模型,进行训练. ...
- Hands on Machine Learning with sklearn and TensorFlow —— 一个完整的机器学习项目(加州房地产)
数据集地址:https://github.com/ageron/handson-ml/tree/master/datasets 先行知识准备:NumPy,Pandas,Matplotlib的模块使用 ...
- 3.Scikit-Learn实现完整的机器学习项目
1 完整的机器学习项目 完成项目的步骤: (1) 项目概述 (2) 获取数据 (3) 发现并可视化数据,发现规律. (4) 为机器学习算法准备数据. (5) ...
- 手把手搭建一个完整的javaweb项目
手把手搭建一个完整的javaweb项目 本案例使用Servlet+jsp制作,用MyEclipse和Mysql数据库进行搭建,详细介绍了搭建过程及知识点. 下载地址:http://download.c ...
- react全家桶从0搭建一个完整的react项目(react-router4、redux、redux-saga)
react全家桶从0到1(最新) 本文从零开始,逐步讲解如何用react全家桶搭建一个完整的react项目.文中针对react.webpack.babel.react-route.redux.redu ...
- python中实现三目运算
python中没有其他语言中的三元表达式,不过有类似的实现方法 如: a = 1 b =2 k = 3 if a>b else 4 上面的代码就是python中实现三目运算的一个小demo, 如 ...
随机推荐
- JavaScript逻辑分支switch 练习题
1.输入月份,显示当月的天数, 利用case穿透简化代码 var month = prompt("请输入月份"); var year = prompt("请输入年份&q ...
- SpringBoot图文教程8 — SpringBoot集成MBG「代码生成器」
有天上飞的概念,就要有落地的实现 概念十遍不如代码一遍,朋友,希望你把文中所有的代码案例都敲一遍 先赞后看,养成习惯 SpringBoot 图文教程系列文章目录 SpringBoot图文教程1「概念+ ...
- 06.深入浅出 Spring Boot - 数据访问之Druid
代码下载:https://github.com/Jackson0714/study-spring-boot.git 一.Druid是什么? 1.Druid是数据库连接池,功能.性能.扩展性方面都算不错 ...
- c++获取屏幕大小
API: 要取得屏幕大小,可以用下面几个函数: # include <windows.h>int cx = GetSystemMetrics( SM_CXFULLSCREEN ); int ...
- 嗨! Apriori算法
Association Rule 一:项集和规则 1.1 认识名词: Association Rule : 关联规则 Frequent Itemsets : 频繁项集 Sequential Patte ...
- 修改gridfilters.js源码,往后台多传递一个参数,并设置NumericFilter、StringFilter默认提示信息
创作不易,转载请注明出处!!! 效果 修改:ext-extend.js源码 在最后面添加3行,重写方法 代码拷贝区 Ext.override(Ext.ux.grid.GridFilters, { me ...
- 动手搞一个Promise
Javascript语言的执行环境是"单线程"(single thread).所谓"单线程",就是指一次只能完成一件任务.如果有多个任务,就必须排队,前面一个任 ...
- SQL数据库中的增删改查总结1
一.增:有2种方法 1.使用insert插入单行数据: 语法:insert [into]<表名> [列名] values <列值> 例:insert into Strdents ...
- Head First设计模式——生成器和责任链模式
生成器 生成器模式:封装一个产品的构造过程,并允许按步骤构造. 现又一个度假计划指定,需要指定度假每一天的活动.旅馆.用餐.门票等等事情,但是每个客人的度假计划可能不太一样.例如天数.活动类型.用餐等 ...
- 网址封锁的几种方法 公司把 pan.baidu.com 封了 研究实现原理
HTTP 和 HTTPS 协议HTTP 协议在 头部会发送 host 就是要访问的域名,可以用来被检测. HTTPS 协议虽然会加密全部通讯,但是在握手之前还是明文传输.有证书特证可被检测. 1, D ...