ConcurrentHashMap(1.7版本和1.8版本)
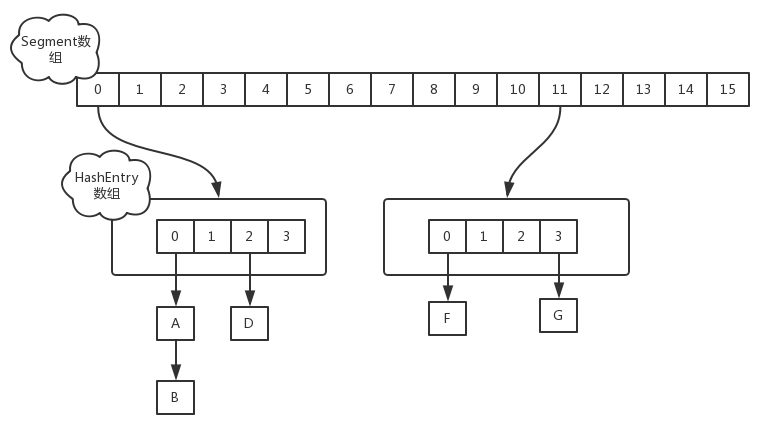
hashMap在1.7版本时使用的是哈希表(数组+链表),Java中采用链表的方式来解决hash冲突的。一个segment元素相当于一个hashMap,一个HashMap的数据结构看起来类似下图:

实现了同步的HashTable也是这样的结构,它的同步是使用锁来保证的,并且所有同步操作使用的是同一个锁对象。这样若有n个线程同时在get时,这n个线程要串行的等待来获取锁。
ConcurrentHashMap中对这个数据结构,针对并发稍微做了一点调整。它把区间按照并发级别(concurrentLevel),分成了若干个segment。默认情况下内部按并发级别16来创建。对于每个segment的容量,默认情况也是16。当然并发级别(concurrentLevel)和每个段(segment)的初始容量都是可以通过构造函数设定的。
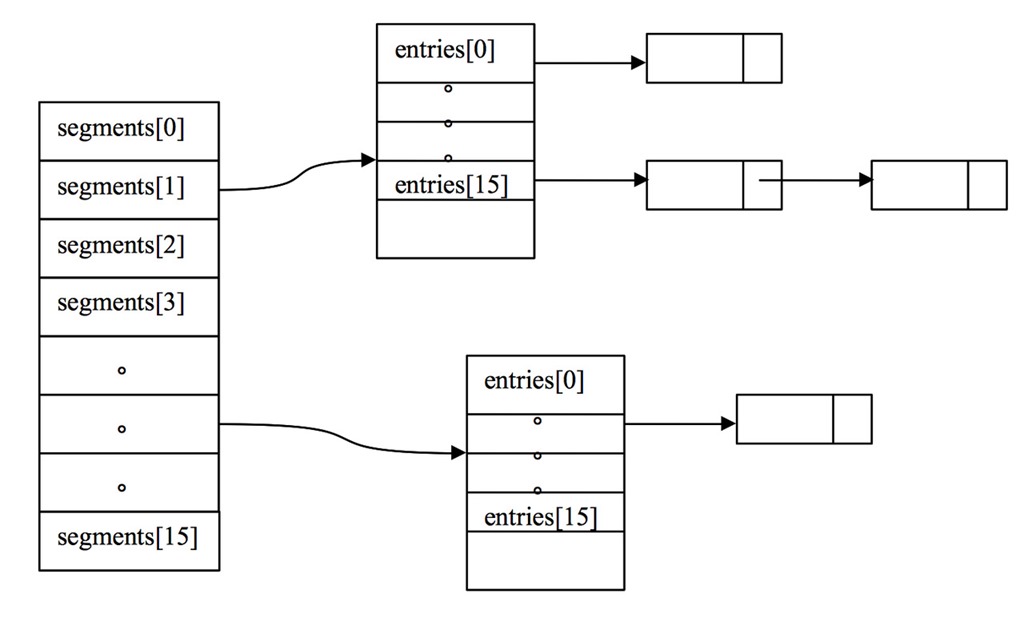
创建好默认的ConcurrentHashMap之后,它的结构大致如下图:
1.2ConcurrentHashMap的初始化
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
int sshift = ;
int ssize = ;
while (ssize < concurrencyLevel) {//如果ssize小于concurrentcylevel并发级别,则一直进行++,concurrentcylevel可以自定义,也可使用默认值16
++sshift;
ssize <<= ;
}
segmentShift = - sshift;
segmentMask = ssize - ;
this.segments = Segment.newArray(ssize);//初始化segments数组,ssize表示segment数组的长度
2.初始化segmentShift和segmentMask
segmentShift和segmentMask这两个全局变量的主要作用是用来定位Segment,int j =(hash >>> segmentShift) & segmentMask。
这两个全局变量需要在定位segment时的散列算法里使用,sshift等于ssize从1向左移位的次数,在默认情况下concurrencyLevel等于16,1需要向左移位移动4次,所以sshift等于4。segmentShift用于定位参与散列运算的位数,segmentShift等于32减sshift,所以等于28,这里之所以用32是因为ConcurrentHashMap里的hash()方法输出的最大数是32位的,后面的测试中我们可以看到这点。segmentMask是散列运算的掩码,等于ssize减1,即15,掩码的二进制各个位的值都是1。因为ssize的最大长度是65536,所以segmentShift最大值是16,segmentMask最大值是65535,对应的二进制是16位,每个位都是1。
关于segmentShift和segmentMask
segmentMask:段掩码,假如segments数组长度为16,则段掩码为16-1=15;segments长度为32,段掩码为32-1=31。这样得到的所有bit位都为1,可以更好地保证散列的均匀性
segmentShift:2的sshift次方等于ssize,segmentShift=32-sshift。若segments长度为16,segmentShift=32-4=28;若segments长度为32,segmentShift=32-5=27。而计算得出的hash值最大为32位,无符号右移segmentShift,则意味着只保留高几位(其余位是没用的),然后与段掩码segmentMask位运算来定位Segment。
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize; //ssize=5 initialCapacity=10
if (c * ssize < initialCapacity)
++c; //
int cap = ;
while (cap < c)
cap <<= ; //
for (int i = ; i < this.segments.length; ++i)
this.segments[i] = new Segment<K,V>(cap, loadFactor); //(8,0.75)
public V put(K key, V value) {
Segment<K,V> s;
//concurrentHashMap不允许key/value为空
if (value == null)
throw new NullPointerException();
//hash函数对key的hashCode重新散列,避免差劲的不合理的hashcode,保证散列均匀
int hash = hash(key);
//返回的hash值无符号右移segmentShift位与段掩码进行位运算,定位segment
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
从源码看出,put的主要逻辑也就两步:1.定位segment并确保定位的Segment已初始化 2.调用Segment的put方法。
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock();
try {
int c = count;
if (c++ > threshold) // 如果Segment中元素的数量超过了阈值(由构造函数中的loadFactor算出)这需要进行对Segment扩容,并且要进行rehash,
rehash();
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - );
HashEntry<K,V> first = tab[index];//getFirst的过程,确定链表头部的位置
HashEntry<K,V> e = first;
//在链表中寻找和要put的元素相同key的元素,如果找到,就直接覆盖key的value,如果没有找到,则进入**行这里,生成一个新的HashEntry并且把它加到整个Segment的头部,然后再更新count的值。
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
if (e != null) {
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
}
** else {
oldValue = null;
++modCount;
tab[index] = new HashEntry<K,V>(key, hash, first, value);
count = c; // write-volatile
}
return oldValue;
} finally {
unlock();
}
}
(3)对于ConcurrentHashMap的数据插入,这里要进行两次Hash去定位数据的存储位置。
|
1
|
static class Segment<K,V> extends ReentrantLock implements Serializable { |
从上Segment的继承体系可以看出,Segment实现了ReentrantLock,也就带有锁的功能,当执行put操作时,会进行第一次key的hash来定位Segment的位置,如果该Segment还没有初始化,即通过CAS操作进行初始化,然后进行第二次hash操作,找到相应的HashEntry的位置,这里会利用继承过来的锁的特性,在将数据插入指定的HashEntry位置时(链表的尾端),会通过继承ReentrantLock的tryLock()方法尝试去获取锁,如果获取成功就直接插入相应的位置,如果已经有线程获取该Segment的锁,那当前线程会以自旋的方式去继续的调用tryLock()方法去获取锁,超过指定次数就挂起,等待唤醒。
get操作
ConcurrentHashMap的get操作跟HashMap类似,只是ConcurrentHashMap第一次需要经过一次hash定位到Segment的位置,然后再hash定位到指定的HashEntry,遍历该HashEntry下的链表进行对比,成功就返回,不成功就返回null。
1.8版本的ConcurrentHashMap
1、ConcurrentHashMap原理
在ConcurrentHashMap中通过一个Node<K,V>[]数组来保存添加到map中的键值对,而在同一个数组位置是通过链表和红黑树的形式来保存的。但是这个数组只有在第一次添加元素的时候才会初始化,在刚开始建立时只是初始化一个ConcurrentHashMap对象的话,只是设定了一个sizeCtl变量,这个变量用来判断对象的一些状态和是否需要扩容,后面会详细解释。
第一次添加元素的时候,默认初期长度为16,当往map中继续添加元素的时候,通过hash值跟table数组长度取与运算来决定要放在数组的哪个位置,如果出现放在同一个位置的时候,优先以链表的形式存放,在同一个位置的个数又达到了8个以上,如果table数组的长度还小于64的时候,则会扩容数组。如果table数组的长度大于等于64了的话,在会将该节点的链表转换成树。
通过扩容数组的方式来把这些节点给分散开。然后将这些元素复制到扩容后的新的数组中,同一个链表中的元素通过hash值的数组长度位来区分,是还是放在原来的位置还是放到扩容的长度的相同位置去 。在扩容完成之后,如果某个节点的是树,同时现在该节点的个数又小于等于6个了,则会将该树转为链表。
取元素的时候,相对来说比较简单,通过计算hash来确定该元素在数组的哪个位置,然后在通过遍历链表或树来判断key和key的hash,取出value值。
往ConcurrentHashMap中添加元素的时候,往哪个位置添加,则锁住哪个位置,ConcurrentHashMap里面的数据以数组的形式存放的样子大概是这样的:
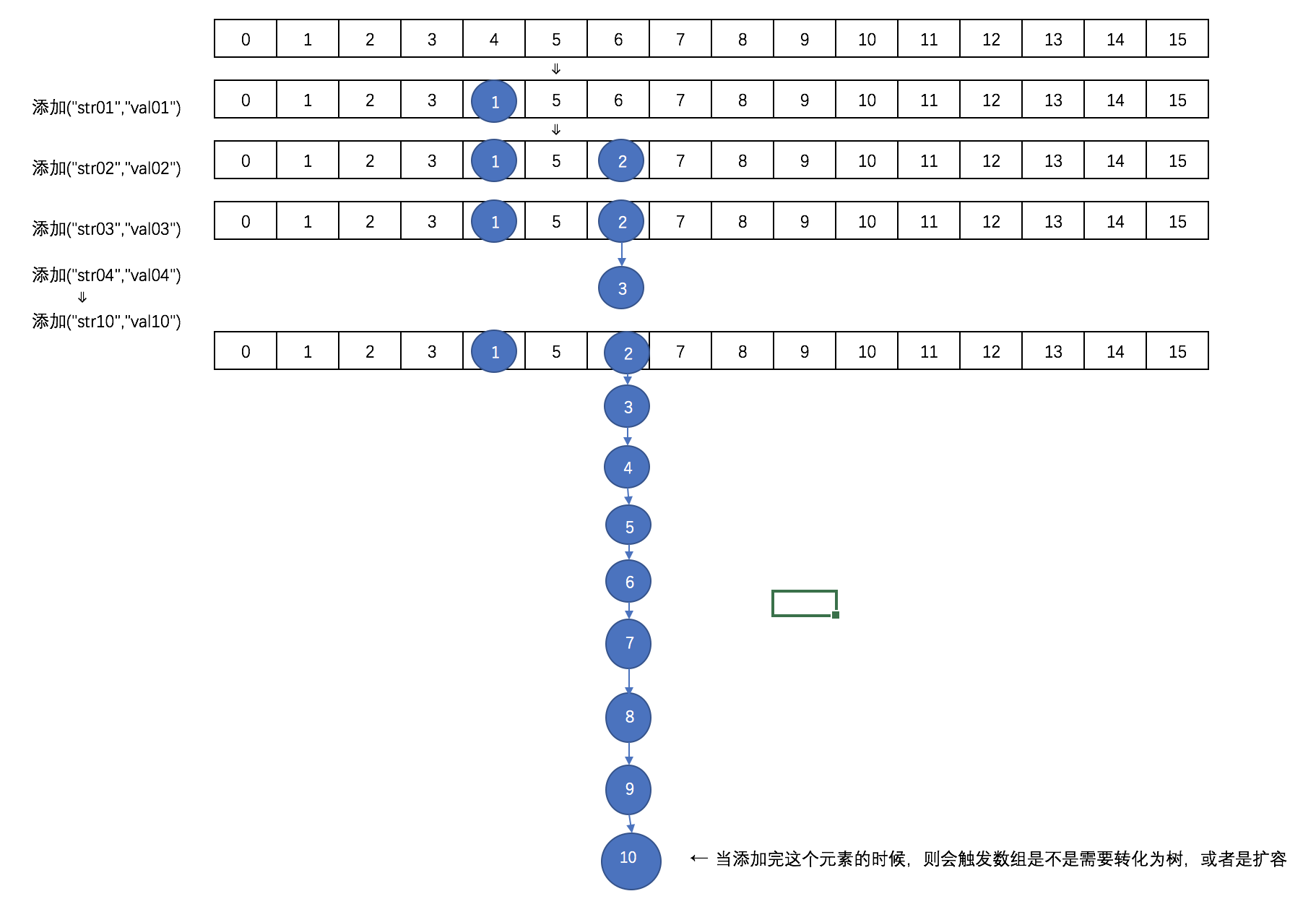
这个时候因为数组的长度才为16,则不会转化为树,而是会进行扩容。
扩容后数组大概是这样的:
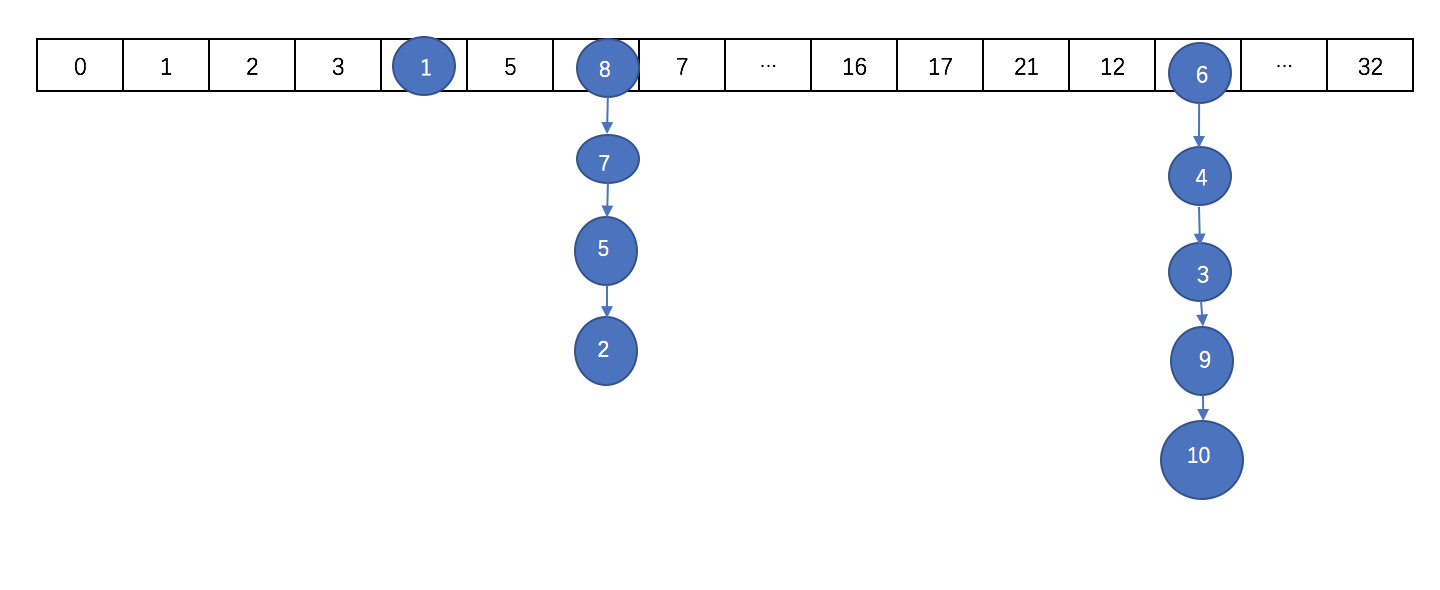
需要注意的是,扩容之后的长度不是32,扩容后的长度在后面细说。
如果数组扩张后长度达到64了,且继续在某个节点的后面添加元素达到8个以上的时候,则会出现转化为红黑树的情况。
转化之后大概是这样:
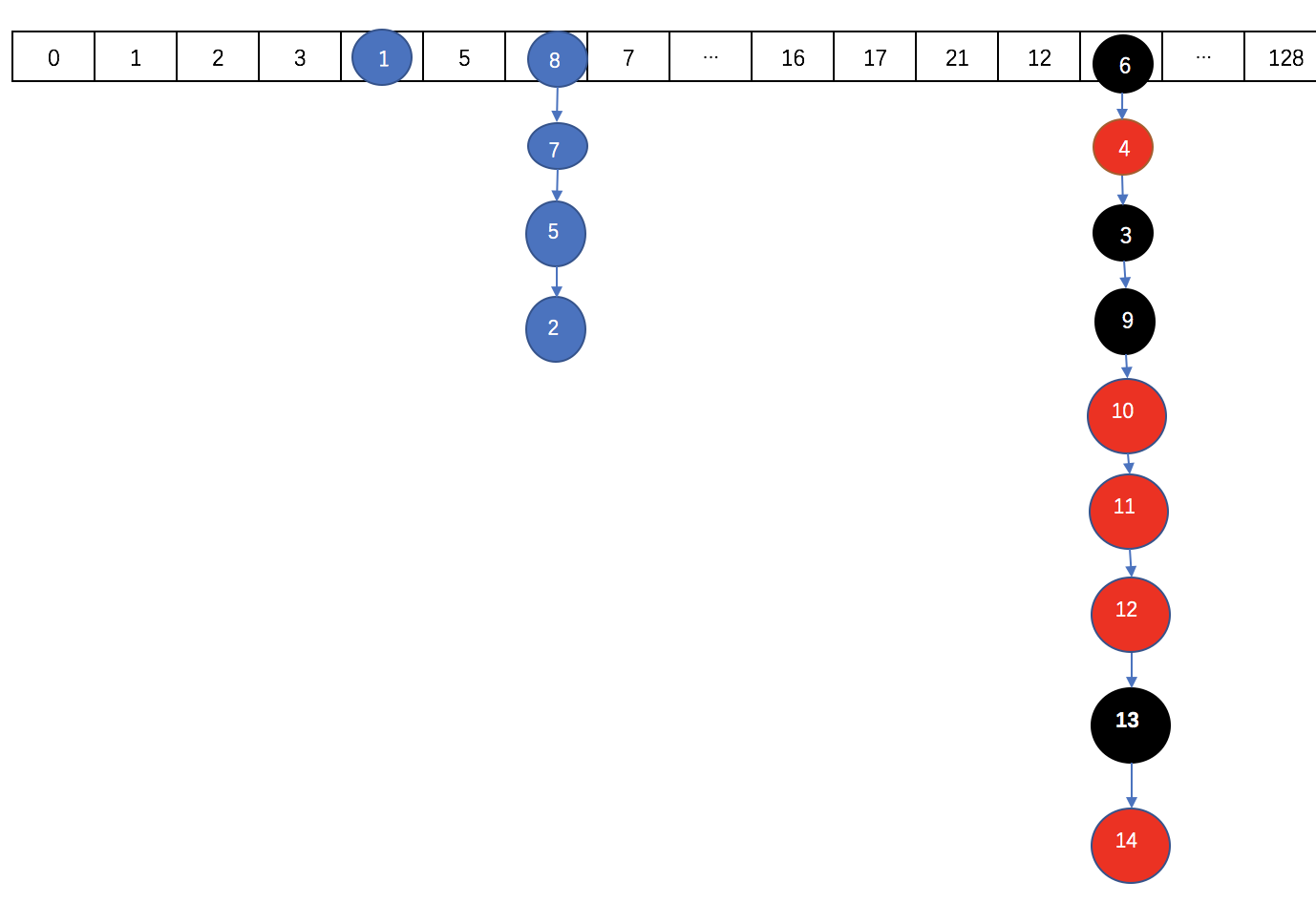
2.ConcurrentHashMap的初始化
public ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel) {//initialCapacity是segment数组的大小,loadFactor是加载因子,concurrentLevel是segment元素的个数
if (!(loadFactor > 0.0f) || initialCapacity < || concurrencyLevel <= )throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel)
initialCapacity = concurrencyLevel;
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
int cap = (size >= (long)MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}
private static final int tableSizeFor(int c) {
int n = c - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
可以看到,在任何一个构造方法中,都没有对存储Map元素Node类型的table变量进行初始化。而是在第一次put操作的时候在进行初始化。
初始化数组:
/**
* 初始化数组table,
* 如果sizeCtl小于0,说明别的数组正在进行初始化,则让出执行权
* 如果sizeCtl大于0的话,则初始化一个大小为sizeCtl的数组
* 否则的话初始化一个默认大小(16)的数组
* 然后设置sizeCtl的值为数组长度的3/4
*/
private final Node<K,V>[] initTable() {
Node<K,V>[] tab;
int sc;
while ((tab = table) == null || tab.length == ) { //第一次put的时候,table还没被初始化,进入while
if ((sc = sizeCtl) < ) //sizeCtl初始值为0,当小于0的时候表示在别的线程在初始化表或扩展表
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSwapInt(this, SIZECTL, sc, -)) { //SIZECTL:表示当前对象的内存偏移量,sc表示期望值,-1表示要替换的值,设定为-1表示要初始化表了
try {
if ((tab = table) == null || tab.length == ) {
int n = (sc > ) ? sc : DEFAULT_CAPACITY; //指定了大小的时候就创建指定大小的Node数组,否则创建指定大小(16)的Node数组
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> );
}
} finally {
sizeCtl = sc; //初始化后,sizeCtl长度为数组长度的3/4
}
break;
}
}
return tab;
}
3、ConcurrentHashMap的put操作详解
下面看看put方法的源码
/*
* 单纯的额调用putVal方法,并且putVal的第三个参数设置为false
* 当设置为false的时候表示这个value一定会设置
* true的时候,只有当这个key的value为空的时候才会设置
*/
public V put(K key, V value) {
return putVal(key, value, false);
}
再来看putVal
/*
* 当添加一对键值对的时候,首先会去判断保存这些键值对的table数组是不是初始化了,
* 如果没有就先进初始化数组
* 然后通过计算hash值来确定放在table数组的哪个位置
* 如果这个位置为空则直接添加,如果不为空的话,则取出这个节点来
* 如果取出来的节点的hash值是MOVED(-1)的话,则表示当前正在对这个数组进行扩容,复制到新的数组,则当前线程也去帮助复制
* 最后一种情况就是,如果这个节点,不为空,也不在扩容,则通过synchronized来加锁,进行添加操作
* 然后判断当前取出的节点位置存放的是链表还是树
* 如果是链表的话,则遍历整个链表,直到取出来的节点的key来个要放的key进行比较,如果key相等,并且key的hash值也相等的话,
* 则说明是同一个key,则覆盖掉value,否则的话则添加到链表的末尾
* 如果是树的话,则调用putTreeVal方法把这个元素添加到树中去
* 最后在添加完成之后,会判断在该节点处共有多少个节点(注意是添加前的个数),如果达到8个以上了的话,
* 则调用treeifyBin方法来尝试将处的链表转为树,或者扩容数组,注意只有在桶数达到64时才会扩容成功
*/
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();//K,V都不能为空,否则的话跑出异常
int hash = spread(key.hashCode()); //取得key的hash值
int binCount = ; //用来计算在这个节点总共有多少个元素,用来控制扩容或者转移为树
for (Node<K,V>[] tab = table;;) { //
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == ) //判断该table数组是否被初始化过
tab = initTable(); //第一次put的时候table没有初始化,则调用initTable()方法初始化table
else if ((f = tabAt(tab, i = (n - ) & hash)) == null) { //通过哈希计算出一个表中的位置因为n是数组的长度,所以(n-1)&hash肯定不会出现数组越界
/*
*f记录的是这个位置的元素,如果这个位置没有元素的话,则通过cas的方式尝试添加,注意这个时候是没有加锁的
*/
if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))//创建一个Node添加到数组中,null表示的是下一个节点为空
break; //
}else if ((fh = f.hash) == MOVED)
/* 能走到这一步说明该位置不为空
* 如果检测到该位置节点的hash值是MOVED,则表示正在进行数组扩张的数据复制阶段,
* 则当前线程也会参与去复制,通过允许多线程复制的功能,一次来减少数组的复制所带来的性能损失
*/
tab = helpTransfer(tab, f);
else {//
/* 走到这一步就说明这个位置有元素,且数组没有在进行扩容
* 这时候就采用synchronized的方式加锁
* 如果是链表的话(hash大于0),就对这个链表的所有元素进行遍历,
* 如果找到了key和key的hash值都一样的节点,则把它的值替换掉
* 如果没找到的话,则添加在链表的最后面
* 否则,是树的话,则调用putTreeVal方法添加到树中去
*
* 在添加完之后,会对该节点上关联的的数目进行判断,
* 如果在8个以上的话,则会调用treeifyBin方法,来尝试转化为树,或者是扩容
*/
V oldVal = null;
synchronized (f) {//往哪个位置存,则锁住哪个位置
if (tabAt(tab, i) == f) { //再次取出要存储的位置的元素,跟前面取出来的比较
if (fh >= ) { //取出来的元素的hash值大于0,当转换为树之后,hash值为-2
binCount = ;
for (Node<K,V> e = f;; ++binCount) {//遍历这个链表
K ek;
if (e.hash == hash&&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {//要存的元素的hash,key跟要存储的位置的节点的相同的时候,替换掉该节点的value即可
oldVal = e.val;
if (!onlyIfAbsent) //当使用putIfAbsent的时候,只有在这个key没有设置值得时候才设置
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) { //如果不是同样的hash,同样的key的时候,则判断该节点的下一个节点是否为空,不为空接着循环,遍历这个链表
pred.next = new Node<K,V>(hash,key,value, null); //为空的话把这个要加入的节点设置为当前节点的下一个节点
break;
}
}//for
}else if (f instanceof TreeBin) { //表示已经转化成红黑树类型了
Node<K,V> p;
binCount = ;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, //调用putTreeVal方法,将该元素添加到树中去
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)p.val = value;
}
}
}//if (tabAt(tab, i) == f)
}// synchronized (f)
if (binCount != ) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i); //当在同一个节点的数目达到8个的时候,则扩张数组或将给节点的数据转为tree
if (oldVal != null)
return oldVal;
break;
}
}//
}//
addCount(1L, binCount); //计数
return null;
}
put操作
对于ConcurrentHashMap的数据插入,这里要进行两次Hash去定位数据的存储位置
|
1
|
static class Segment<K,V> extends ReentrantLock implements Serializable { |
从上Segment的继承体系可以看出,Segment实现了ReentrantLock,也就带有锁的功能,当执行put操作时,会进行第一次key的hash来定位Segment的位置,如果该Segment还没有初始化,即通过CAS操作进行赋值,然后进行第二次hash操作,找到相应的HashEntry的位置,这里会利用继承过来的锁的特性,在将数据插入指定的HashEntry位置时(链表的尾端),会通过继承ReentrantLock的tryLock()方法尝试去获取锁,如果获取成功就直接插入相应的位置,如果已经有线程获取该Segment的锁,那当前线程会以自旋的方式去继续的调用tryLock()方法去获取锁,超过指定次数就挂起,等待唤醒
get操作
ConcurrentHashMap的get操作跟HashMap类似,只是ConcurrentHashMap第一次需要经过一次hash定位到Segment的位置,然后再hash定位到指定的HashEntry,遍历该HashEntry下的链表进行对比,成功就返回,不成功就返回null
size操作
计算ConcurrentHashMap的元素大小是一个有趣的问题,因为他是并发操作的,就是在你计算size的时候,他还在并发的插入数据,可能会导致你计算出来的size和你实际的size有相差(在你return size的时候,插入了多个数据),要解决这个问题,JDK1.7版本用两种方案
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
try { for (;;) { if (retries++ == RETRIES_BEFORE_LOCK) { for (int j = 0; j < segments.length; ++j) ensureSegment(j).lock(); // force creation } sum = 0L; size = 0; overflow = false; for (int j = 0; j < segments.length; ++j) { Segment<K,V> seg = segmentAt(segments, j); if (seg != null) { sum += seg.modCount; int c = seg.count; if (c < 0 || (size += c) < 0) overflow = true; } } if (sum == last) break; last = sum; } }finally { if (retries > RETRIES_BEFORE_LOCK) { for (int j = 0; j < segments.length; ++j) segmentAt(segments, j).unlock(); }} |
- 第一种方案他会使用不加锁的模式去尝试多次计算ConcurrentHashMap的size,最多三次,比较前后两次计算的结果,结果一致就认为当前没有元素加入,计算的结果是准确的
- 第二种方案是如果第一种方案不符合,他就会给每个Segment加上锁,然后计算ConcurrentHashMap的size返回
JDK1.8的实现
ConcurrentHashMap(1.7版本和1.8版本)的更多相关文章
- 高版本->低版本迁移,低版本客户端连接高版本数据库EXP导出报错EXP-00008,ORA-01455,EXP-00000
生产环境: 源数据库:RHEL + Oracle 11.2.0.3 目标数据库:HP-UX + Oracle 10.2.0.4 需求:迁移部分表 11.2.0.3-->10.2.0.4,若 ...
- 高版本api在低版本中的兼容
直接上例子,看如何避免crash. eg:根据给出路径,获取此路径所在分区的总空间大小. 文档说明:获取文件系统用量情况,在API level 9及其以上的系统,可直接调用File对象的相关方法,以下 ...
- 怎样去除SVN中的某个版本之前的所有版本
地狱门神 在某些时候,我们可能需要一个存放二进制文件的SVN库,用来保存每日构建的结果等.但是这种库会趋于越来越大,最后会占用很多磁盘空间.这时我们会想到能不能删掉某个版本之前的所有版本,以节省磁盘空 ...
- SQL Server 2000 sp2 及更低版本不受此版本的 Windows 支持
SQL Server 2000 sp2 及更低版本不受此版本的 Windows 支持.在安装了 SQL Server 2000 之后请应用 sp3. 出现这种现象的原因在于:Windows Serve ...
- 如何让VMware低版本运行VMware高版本创建的虚拟机
如何让VMware低版本运行VMware高版本创建的虚拟机 问题描述: 本机安装的VMware Workstation是10版本,之前VMware Workstation 11版本创建的虚拟机,在运行 ...
- PHP有两个不同的版本:4.x系列版本和5.x系列版本
在为用户提供动态内容方面,PHP和MySQL是一个强大的组合.这些年来,这两项产品已经跨越了它们最初的应用舞台,现在,一些世界上最繁忙的网站也在应用它们.虽然它们当初都是开源软件,只能在UNIX/Li ...
- MongoDB3.2版本与3.0版本写场景压力测试对比
我们主要是为了测试journal对写操作性能的影响.分别测试了3.2版本,3.0版本在ramdisk,hdd上有journal,和没journal的情况. 发现一个很怪异的现象,3.2版本时候,随着y ...
- DOS批处理命令判断操作系统版本、执行各版本对应语句
DOS批处理命令判断操作系统版本.执行各版本对应语句 昨天在家里试用 netsh interface ip set address 这些命令更改上网IP.DNS.网关等,今天将那些代码拿来办公室 ...
- DirectX SDK版本与Visual Studio版本
对于刚刚接触 DirectShow 的人来说,安装配置是一个令人头疼的问题,经常出现的情况是最基本的 baseclass 就无法编译.一开始我也为此费了很大的功夫,比如说修改代码.修改编译选项使其编译 ...
- 如何选择版本控制系统 ---为什么选择Git版本控制系统
版本控制系统 "代码"作为软件研发的核心产物,在整个开发周期都在递增,不断合入新需求以及解决bug的新patch,这就需要有一款系统,能够存储.追踪文件的修改历史,记录多个版本的开 ...
随机推荐
- HTTP协议 有这篇文章足够了
HTTP 协议详解 HTTP(HyperText Transfer Protocol)超文本传输协议.其最初的设计目的是为了提供一种发布和接收HTML页面的方法. HTTP是一个客户端(用户)和服务端 ...
- 《自拍教程36》段位三_Python面向对象类
函数只能面向过程,来回互相调用后顺序执行, 简单的编码项目,还能应付的过来, 复杂的大型项目,调用多了,就会乱. 如何才能不乱呢,可尝试下, 面向对象类的概念, 将现实世界的事物抽象成对象,将现实世界 ...
- H5页面通用头部设置
见到很多人写H5页面都不设置头部,不忍直视,于是整理一篇文章,不定期更新,为了让自己显得专业一点,也为了方便自己复制粘贴 一般来说必须设置项 <!-- 页面编码 --> <meta ...
- 学习Vue.js-Day2
书接上文/思考反馈 react,ng,vue作用差不多,那各个都有什么特点啊,实际工作中应该用哪一个? 答:其实在实际工作中,组员会通过讨论而选择框架:这三个框架都能解放你的工作量,也适合做单页面应用 ...
- cordova+vue打包ios调用相机闪退解决
cordova+vue项目打包android,打开相机正常使用,但是打包ios后,需要多几个配置,才能打开,否则当调用的时候会闪退,上配置图 需要在选中的文件里面添加 <key>NSCam ...
- div隐藏滚动条,仍可滚动
<!DOCTYPE html><html><head lang="en"> <meta charset="UTF-8" ...
- python基础(初识)
Python简介 python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏姆(中文名字:龟叔)为了在阿姆斯特丹打发时间,决心开发一个新的脚本解 ...
- Chrome开发者工具之测试应用
一.Chrome开发者工具简介 浏览器的开发者工具(DevTools)可以帮助开发人员对网页进行布局,比如HTML+CSS,帮助前端工程师更好的调试脚本(JavaScript.jQuery)之类的,还 ...
- 将xml处理为json对象数组
function xmlStr2js(xmlStr) { var tagNames = xmlStr.match(/<\w+>/g) tagNames = deWeightTagNames ...
- 03.文件I/O
UNIX系统中的大多数文件I/O只需用到5个函数:open.read.write.lseek和close. 本章所说明的函数称为不带缓冲的I/O.不带缓冲指的是每个read和write都调用内核中的一 ...