CVPR 2020 三篇有趣的论文解读
作者 | 文永亮
学校 | 哈尔滨工业大学(深圳)
研究方向 | 视频预测、时空序列预测
目录
- AdderNet — 其实不需要这么多乘法
- Deep Snake for Real-Time Instance Segmentation — 用轮廓做实例分割
- Blurry Video Frame Interpolation — 完美的金字塔
AdderNet (在深度学习中我们真的需要乘法?)

这篇论文是北大、诺亚、鹏城、悉大的论文,观点比较有趣,在喜提CVPR2020之前也比较火了,下面我可以介绍一下。
论文指出我们可以定义如下公式,首先我们定义核大小为d,输入通道为\(c_{in}\),输出通道为\(c_{out}\)的滤波器\(F \in \mathbb{R}^{d \times d \times c_{i n} \times c_{o u t}}\),长宽为H, W 的输入特征为\(X \in \mathbb{R}^{H \times W \times c_{i n}}\),
\[
Y(m, n, t)=\sum_{i=0}^{d} \sum_{j=0}^{d} \sum_{k=0}^{c_{i n}} S(X(m+i, n+j, k), F(i, j, k, t))
\]
其中 \(S(\cdot, \cdot)\) 为相似度计算方法,如果设 \(S(x, y)=x×y\) ,这就是卷积的一种定义方法了。 那么论文就引出加法网络的基本算子如何定义的:
\[
Y(m, n, t)=-\sum_{i=0}^{d} \sum_{j=0}^{d} \sum_{k=0}^{c_{i n}}|X(m+i, n+j, k)-F(i, j, k, t)|
\]
如上定义只用了加法的\(\ell{1}\)距离,可以有效地计算滤波器和特征之间的相似度。
在CIFAR-10和CIFAR-100以及ImageNet的实验结果:
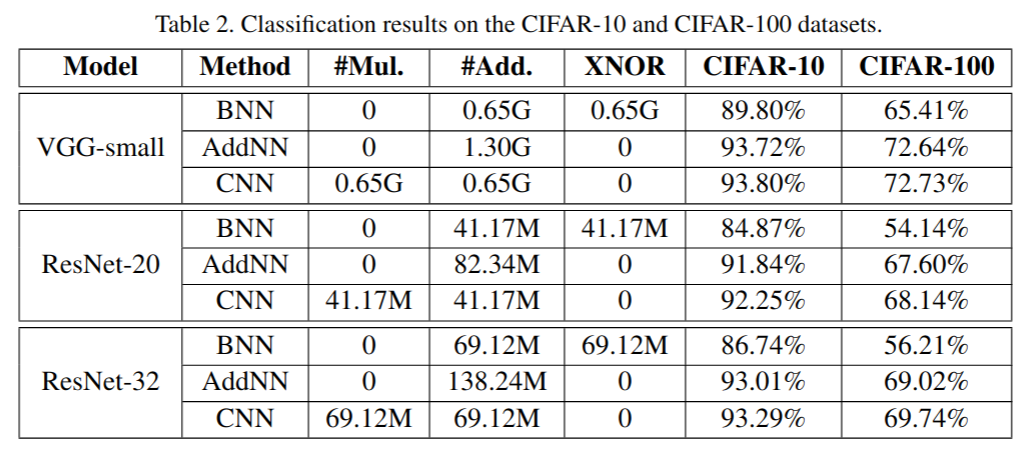
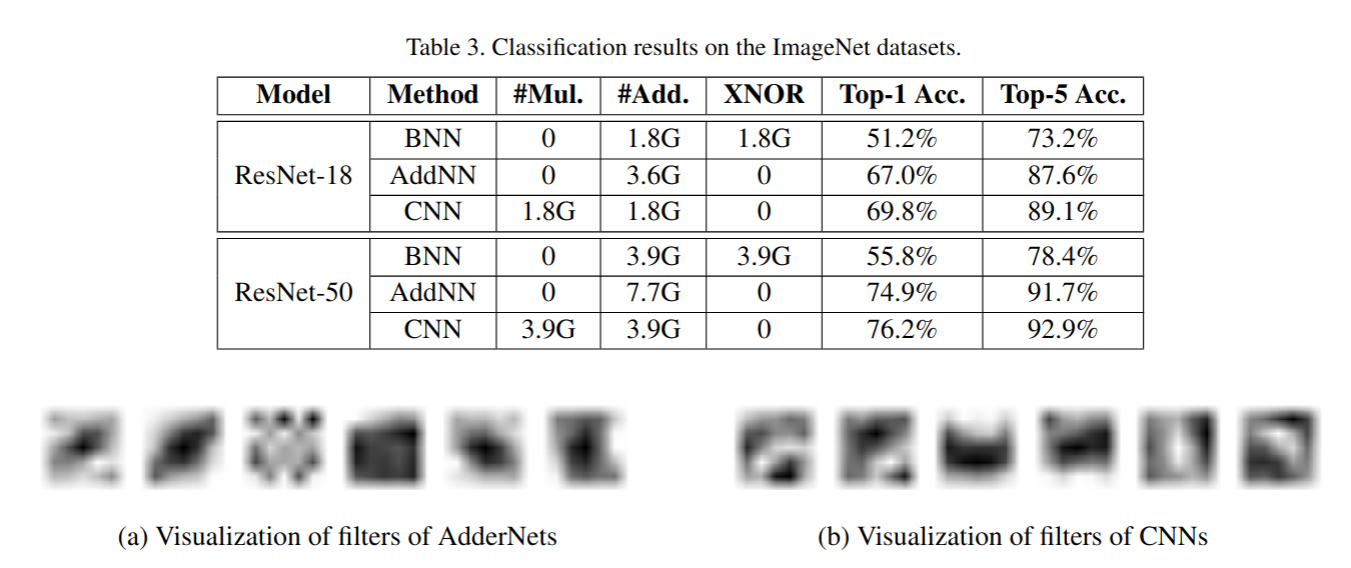
可以看到在把卷积替换成加法之后好像也没有太多精度的丢失,正如标题说的,我们真的需要这么多乘法吗?
Deep Snake用于实例分割

这篇工作是来自浙江大学Deepwise AI Lab的,我起初看到感觉十分有趣,这篇论文的实例分割并不是每个像素的去分,而是用轮廓围住了实例。代码已经开源,有兴趣的同学可以去看看。
repo url:https://github.com/zju3dv/snake
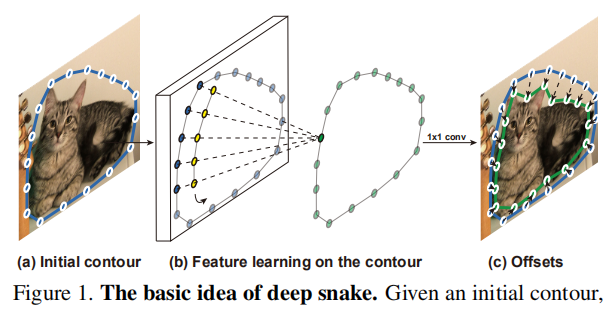
基本思想是给实例一个初始轮廓,用循环卷积(Circular Convolution)方法学习更新轮廓,最后得到offsets。
我在下面介绍一下Circular Convolution:
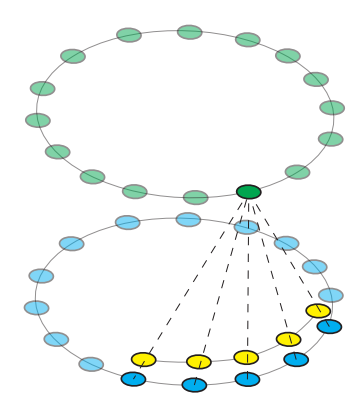
\[
\left(f_{N}\right)_{i} \triangleq \sum_{j=-\infty}^{\infty} f_{i-j N}=f_{i(\bmod N)}\\
\left(f_{N} * k\right)_{i}=\sum_{j=-r}^{r}\left(f_{N}\right)_{i+j} k_{j}
\]
我们定义特征为蓝色部分的圆圈,那么它可以表达为\(f_{i(\bmod N)}\) ,*是标准的卷积操作,整个循环卷积就是每一个蓝色的特征与黄色的kernel相乘得到对应高亮的绿色输出,一圈下来就得到完整的输出,kernel也是共享的。
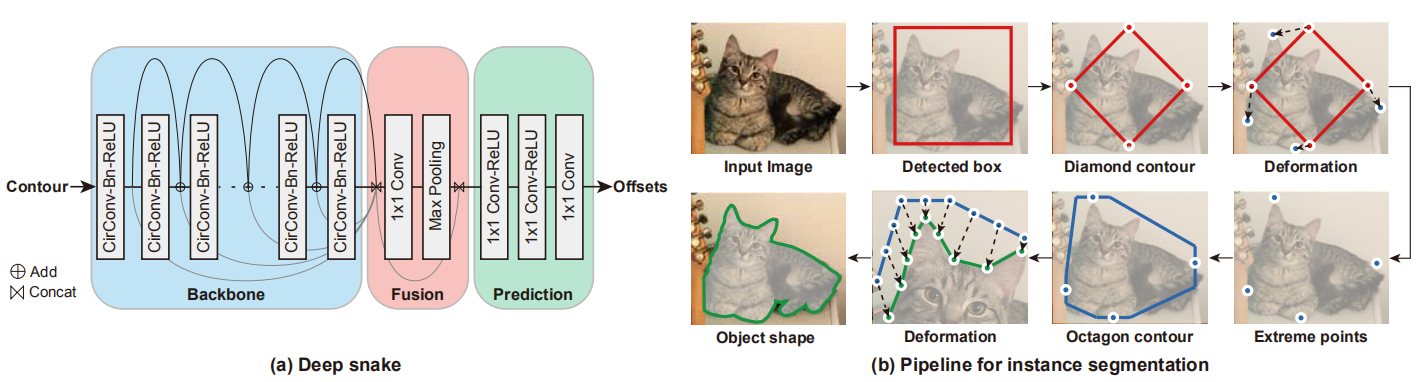
我们可以通过图(b)看到整个算法的pipeline,首先输入图片,实验中使用了CenterNet作为目标检测器, Center Net将检测任务重新定义为关键点检测问题,这样得到一个初始的box,然后取每边的中点连接作为初始的Diamond contour(实际实验中作者说他upsample成了40个点),然后通过变形操作使点回归到实例的边界点,然后通过边界点一半向外拓展1/4的边长得到一个Octagon contour(八边形轮廓),再做变形操作最终回归到目标的形状边界。
作者在三个数据集上做了实验,分别是Cityscapes, Kins, Sbd。可以看到在Kins上的数据集的AP值比Mask RCNN好一些。
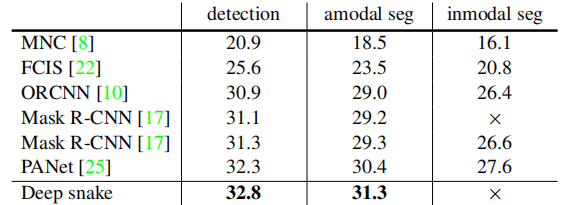
其分割的效果也不错且有点有趣:

可以看到确实挺快的, Sbd数据集的512 × 512 的图片,在Intel i7 3.7GHz,GTX 1080 Ti GPU达到32.3 fps。

BIN 模糊视频插帧

这篇paper是上海交通大学的翟广涛教授组的模糊视频插帧技术,主要是为了提高视频质量并且达到插帧的效果,我觉得这篇论文十分优秀,只可惜代码还在重构中,repo说6.14公布,这也有点久啊。
repo url : https://github.com/laomao0/BIN
这篇论文设计的很精巧,模型构建中分为两块:
1.金字塔模块
2.金字塔间的递归模块
如下图所示:
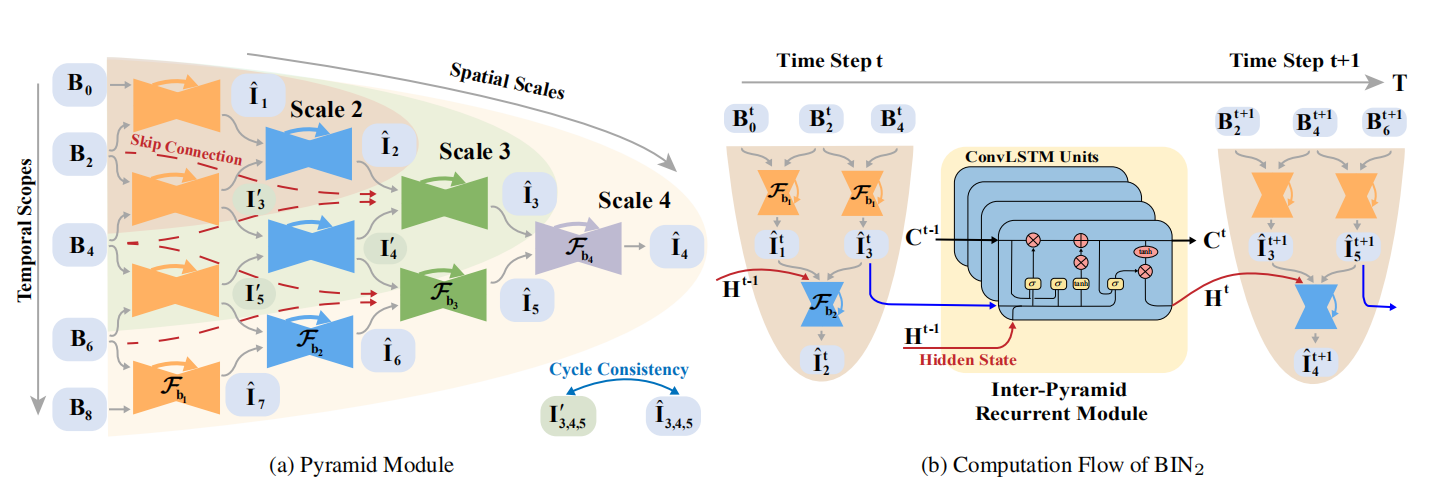
其实这网络结构很容易理解,\(B_0,B_2,B_4,B_6,B_8\)都是输入,当我们取Scale 2的时候,输入取\(B_0,B_2,B_4\), 我们可通过\(B_0,B_2\)得到中间插帧\(\hat{{I}}_1\),同理可得\(\hat{I}_3\),最后通过\(\hat{{I}}_1\)和\(\hat{I}_3\)插帧得到\(\hat{{I}}_2\)。
数学表达如下:
\[
\hat{\mathbf{I}}_{1: 1: 2 N-1}=\mathcal{F}\left(\mathbf{B}_{0: 2: 2 N}\right)
\]
\[
\hat{\mathbf{I}}_{1}=\mathcal{F}_{\mathrm{b}}\left(\mathbf{B}_{0}, \mathbf{B}_{2}\right)
\]
但是Scale 3和4的时候就不一样了,我举例Scale 3的时候,Scale 4同理
\[
\hat{\mathbf{I}}_{1}=\mathcal{F}_{\mathrm{b_1}}\left(\mathbf{B}_{0}, \mathbf{B}_{2}\right)\\
{\mathbf{I'}}_{3}=\mathcal{F}_{\mathrm{b_1}}\left(\mathbf{B}_{2}, \mathbf{B}_{4}\right)\\
\hat{\mathbf{I}}_{2}=\mathcal{F}_{\mathrm{b_2}}\left(\mathbf{\hat{I}}_{1}, \mathbf{I'}_{3}\right)\\
\hat{\mathbf{I}}_{3}=\mathcal{F}_{\mathrm{b_2}}\left(\mathbf{\hat{I}}_{2}, \mathbf{\hat{I}}_{4},\mathbf{B}_{3},\mathbf{B}_{4}\right)\\
{\mathbf{I'}}_{5}=\mathcal{F}_{\mathrm{b_1}}\left(\mathbf{B}_{4}, \mathbf{B}_{6}\right)
\]
这样通过\(B_0,B_2,B_4,B_6\)就会得到中间1,3,5的插帧,或许有人疑惑为什么会有\(\mathbf{I'}_{3}\) 和\(\hat{\mathbf{I}}_{3}\) ,这两个有什么区别,这里主要就是因为作者做了一个Cycle Consistency的loss,主要是保证中间产生的帧与金字塔最后产生的帧保持空间上的一致性。
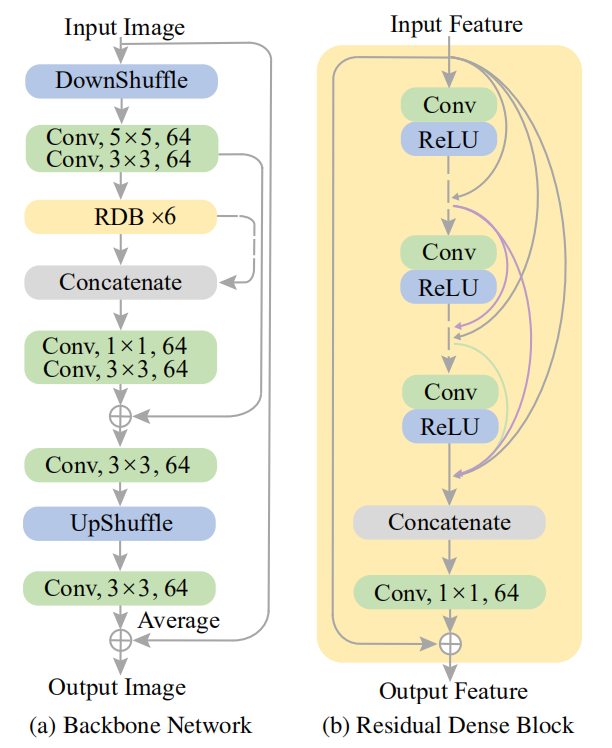
金字塔模块的构建有(a)Backbone (b)Residual Dense Block 两种
其中金字塔模块具有可调节的空间感受域和时间范围,可以从图中看到,作者采用了三种scale,随着scale的增加,网络将会拓展的更深,因此具有更大的空间感受域,同时在时间范围内输入的数量会需要更多,所以说时间范围也正是如此,从而控制计算复杂度和复原能力。金字塔模块使用普通的卷积神经网络搭建而成,其中同一级的共享权重,这其实节省了很多参数空间,但是这样是否就缺乏了时间上的信息呢?
如果采用Scale 2的时候,我们可以分析金字塔之间如何传递信息的,如图中(b)部分:
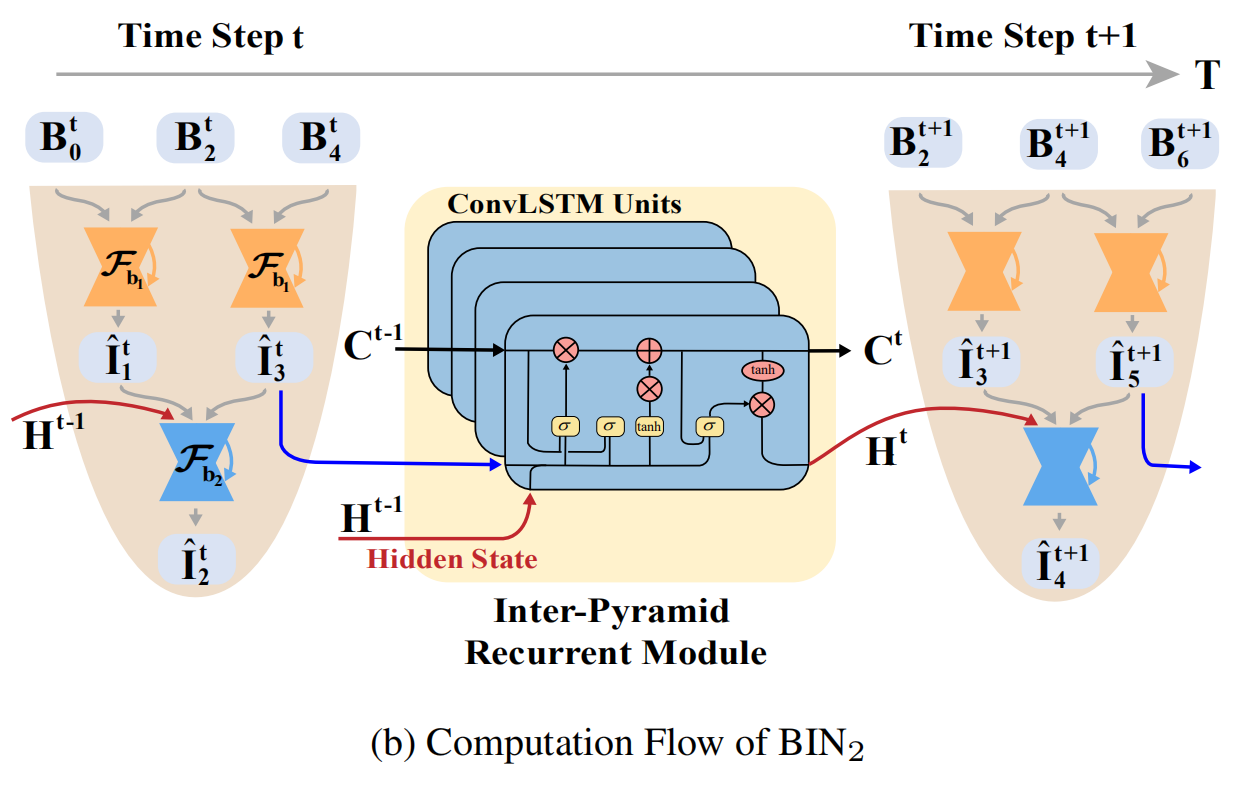
ConvLSTM构成的Inter-Pyramid Recurrent Module实际上就是为了传递时空上的信息,这里Time Step为2,\(B_2^{t}\) 与\(B_2^{t+1}\) 实际上是同一张输入,但是进入了两个不同的模块,整体step前进了一步,其中的ConvLSTM就是为了传递C和H的,其公式如下:
\[
\mathbf{H}^{t}, \mathbf{C}^{t}=\mathcal{F}_{\mathrm{c}}\left(\hat{\mathbf{I}}_{3}^{t}, \mathbf{H}^{t-1}, \mathbf{C}^{t-1}\right)
\]
损失函数非常的简单,这里不做过多的说明,分为了重构误差\(L_p\) (Pixel Reconstruction) 和 一致性误差\(L_c\) (Cycle Consistency) :
\[
\rho(x)=\sqrt{x^{2}+\epsilon^{2}}\\
\mathcal{L}_{p}=\frac{1}{T} \sum_{t=1}^{T} \sum_{n=1}^{2 M-1} \rho\left(\hat{\mathbf{I}}_{n}^{t}-\mathbf{G}_{n}^{t}\right)\\
\mathcal{L}_{c}=\frac{1}{T} \sum_{t=1}^{T} \sum_{n \in \Omega} \rho\left(\mathbf{I}_{n}^{t}-\hat{\mathbf{I}}_{n}^{t}\right)\\
\mathcal{L}=\mathcal{L}_{p}+\mathcal{L}_{c}\\
\]
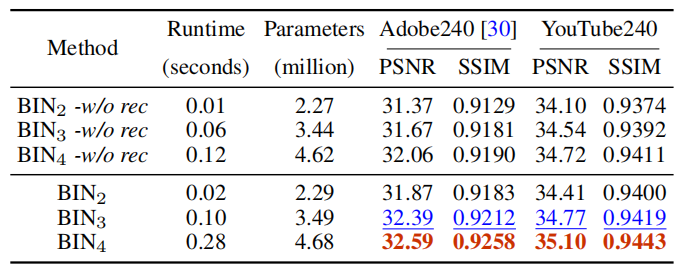
数据集用的是:Adobe240和YouTube240,可以看到论文的效果取了Scale=4的时候跟GT已经看不出太大的区别了。

而且Scale越大图片质量就越好:
CVPR 2020 三篇有趣的论文解读的更多相关文章
- itemKNN发展史----推荐系统的三篇重要的论文解读
itemKNN发展史----推荐系统的三篇重要的论文解读 本文用到的符号标识 1.Item-based CF 基本过程: 计算相似度矩阵 Cosine相似度 皮尔逊相似系数 参数聚合进行推荐 根据用户 ...
- CVPR 2020几篇论文内容点评:目标检测跟踪,人脸表情识别,姿态估计,实例分割等
CVPR 2020几篇论文内容点评:目标检测跟踪,人脸表情识别,姿态估计,实例分割等 CVPR 2020中选论文放榜后,最新开源项目合集也来了. 本届CPVR共接收6656篇论文,中选1470篇,&q ...
- 多篇开源CVPR 2020 语义分割论文
多篇开源CVPR 2020 语义分割论文 前言 1. DynamicRouting:针对语义分割的动态路径选择网络 Learning Dynamic Routing for Semantic Segm ...
- CVPR 2020目标跟踪多篇开源论文(上)
CVPR 2020目标跟踪多篇开源论文(上) 1. SiamBAN:面向目标跟踪的Siamese Box自适应网络 作者团队:华侨大学&中科院&哈工大&鹏城实验室&厦门 ...
- CVPR 2020目标跟踪多篇开源论文(下)
CVPR 2020目标跟踪多篇开源论文(下) 6. Cooling-Shrinking Attack: Blinding the Tracker with Imperceptible Noises 作 ...
- 自监督学习(Self-Supervised Learning)多篇论文解读(上)
自监督学习(Self-Supervised Learning)多篇论文解读(上) 前言 Supervised deep learning由于需要大量标注信息,同时之前大量的研究已经解决了许多问题.所以 ...
- zz2019年主动学习有哪些进展?答案在这三篇论文里
2019年主动学习有哪些进展?答案在这三篇论文里 目前推广应用的机器学习方法或模型主要解决分类问题,即给定一组数据(文本.图像.视频等),判断数据类别或将同类数据归类等,训练过程依赖于已标注类别的训练 ...
- CVPR 2020 全部论文 分类汇总和打包下载
CVPR 2020 共收录 1470篇文章,根据当前的公布情况,人工智能学社整理了以下约100篇,分享给读者. 代码开源情况:详见每篇注释,当前共15篇开源.(持续更新中,可关注了解). 算法主要领域 ...
- CVPR 2020论文收藏(转知乎:https://zhuanlan.zhihu.com/p/112337176)
CVPR 2020 共收录 1470篇文章,根据当前的公布情况,人工智能学社整理了以下约100篇,分享给读者. 代码开源情况:详见每篇注释,当前共15篇开源.(持续更新中,可关注了解). 算法主要领域 ...
随机推荐
- C++语言堆栈的详细讲解
本文主要向大家介绍了C++语言堆栈的详细讲解,通过具体的内容向大家展示,希望对大家学习C++语言有所帮助. 一.预备知识—程序的内存分配 一个由c/C++编译的程序占用的内存分为以下几个部分 1.栈区 ...
- Tarjan模板——求强连通分量
Tarjan求强连通分量的流程在这个博客讲的很清楚,再加上我也没理解透,这里就不写了. 缩点:将同一个连通块内的点视为同一个点. 扔一道模板题:codeVS2822爱在心中 第一问很显然就是求点数大于 ...
- perf4j+logback配置 非spring 可使用注解
最近项目打算使用perf4j进行性能监控,由于项目没有使用spring,而又不想对代码入侵过高,打算使用注解的方式进行接入.perf4j采用AspectJ库实现AOP. 具体接入方法如下: logba ...
- [LC] 238. Product of Array Except Self
Given an array nums of n integers where n > 1, return an array output such that output[i] is equ ...
- webstrom IDE 正则替换
ide:webstrom 其他IDE,可以自行测试. 目的. 将excel的table两列(一般是中文名,英文名,改为Javascript 对象) 从 场所内网IP地址 IP_ADDRESS 源外网I ...
- C语言学习笔记之获取文件长度
本文为原创文章,转载请标明出处 #include <stdio.h> #include <stdlib.h> int main() { FILE *inputFile; inp ...
- 吴裕雄--天生自然HTML学习笔记:HTML 属性
属性是 HTML 元素提供的附加信息. HTML 属性 HTML 元素可以设置属性 属性可以在元素中添加附加信息 属性一般描述于开始标签 属性总是以名称/值对的形式出现,比如:name="v ...
- Cenos配置Android集成化环境, 最终Centos libc库版本过低放弃
To honour the JVM settings for this build a new JVM will be forked. Please consider using the daemon ...
- java增强型for循环
http://blog.csdn.net/itmyhome1990/article/details/8797005
- 关于log4j中log4j.properties和log4j.xml的加载顺序
如果采用log4j输出日志,要对log4j加载配置文件的过程有所了解. log4j启动时,默认会寻找source folder下的log4j.xml配置文件,若没有,会寻找log4j.properti ...