Flink on yarn以及实现jobManager 高可用(HA)
on yarn:https://ci.apache.org/projects/flink/flink-docs-release-1.8/ops/deployment/yarn_setup.html
flink on yarn两种方式
第一种方式:yarn session 模式,在yarn上启动一个长期运行的flink集群
使用 yarn session 模式,我们需要先启动一个 yarn-session 会话,相当于启动了一个 yarn 任务,这个任务所占用的资源不会变化,并且一直运行。我们在使用 flink run 向这个 session 任务提交作业时,如果 session 的资源不足,那么任务会等待,直到其他资源释放。当这个 yarn-session 被杀死时,所有任务都会停止。
把yarn和hdfs相关配置文件拷贝到flink配置目录下,或者直接指定yarn和hdfs配置文件对应的路径
export HADOOP_CONF_DIR=/root/flink-1.8.2/conf
cd flink-1.8./
./bin/yarn-session.sh -jm 1024m -tm 4096m -s
-jm:jobmanager的内存,-tm:每个taskmanager的内存,-s:the number of processing slots per Task Manager
日志如下
[root@master01 flink-1.8.]# ./bin/yarn-session.sh -jm 1024m -tm 4096m -s
-- ::, INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.rpc.address, master01.hadoop.xxx.cn
-- ::, INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.rpc.port,
-- ::, INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.heap.size, 1024m
-- ::, INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: taskmanager.heap.size, 1024m
-- ::, INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: taskmanager.numberOfTaskSlots,
-- ::, INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: parallelism.default,
-- ::, INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - Found Yarn properties file under /tmp/.yarn-properties-root.
-- ::, INFO org.apache.flink.runtime.security.modules.HadoopModule - Hadoop user set to root (auth:SIMPLE)
-- ::, INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at master01.hadoop.xxx.cn/xxx.xx.x.xxx:
-- ::, INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Cluster specification: ClusterSpecification{masterMemoryMB=, taskManagerMemoryMB=, numberTaskManagers=, slotsPerTaskManager=}
-- ::, WARN org.apache.hadoop.util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
-- ::, WARN org.apache.flink.yarn.AbstractYarnClusterDescriptor - The configuration directory ('/root/flink-1.8.2/conf') contains both LOG4J and Logback configuration files. Please delete or rename one of them.
-- ::, INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Submitting application master application_1570496850779_0463
-- ::, INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1570496850779_0463
-- ::, INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Waiting for the cluster to be allocated
-- ::, INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Deploying cluster, current state ACCEPTED
-- ::, INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - YARN application has been deployed successfully.
-- ::, INFO org.apache.flink.runtime.rest.RestClient - Rest client endpoint started.
Flink JobManager is now running on worker03.hadoop.xxx.cn:38055 with leader id ----.
JobManager Web Interface: http://worker03.hadoop.xxx.cn:38055
查看web界面可以直接到yarn界面查看,也可以通过日志中给出的jobmanager界面查看

提交任务测试,提交任务使用./bin/flink
cd flink-1.8./
./bin/flink run ./examples/batch/WordCount.jar
日志如下:
[root@master01 flink-1.8.]# ./bin/flink run ./examples/batch/WordCount.jar
-- ::, INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - Found Yarn properties file under /tmp/.yarn-properties-root.
-- ::, INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - Found Yarn properties file under /tmp/.yarn-properties-root.
-- ::, INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - YARN properties set default parallelism to
-- ::, INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - YARN properties set default parallelism to
YARN properties set default parallelism to
-- ::, INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at master01.hadoop.xxx.cn/xxx.xx.x.211:
-- ::, INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
-- ::, INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
-- ::, INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Found application JobManager host name 'worker02.hadoop.xxx.cn' and port '' from supplied application id 'application_1570496850779_0467'
Starting execution of program
Executing WordCount example with default input data set.
Use --input to specify file input.
Printing result to stdout. Use --output to specify output path.
(a,)
(action,)
(after,)
(against,)
(all,)
......
问题:在提交flink任务时候,flink是怎么找到对应的集群呢?
看日志高亮部分,查看/tmp/.yarn-properties-root文件内容
[root@master01 flink-1.8.]# more /tmp/.yarn-properties-root
#Generated YARN properties file
#Tue Dec :: CST
parallelism=
dynamicPropertiesString=
applicationID=application_1570496850779_0467
这个applicationID不就是我们提交到yarn上flink集群对应的id嘛。
到flink web ui查看任务记录

此外,在启动on yarn flink集群时候可以使用-d or --detached实现类似后台运行的形式执行,此方式下,如果想停止集群,使用yarn application -kill <appId>
第二种方式:Run a single Flink job on YARN
上面第一种方式是在yarn上启动一个flink集群,然后提交任务时候向这个集群提交。此外,也可以在yarn上直接执行一个flink任务,有点类似spark-submit的感觉。
[root@master01 flink-1.8.]# ./bin/flink run -m yarn-cluster ./examples/batch/WordCount.jar
日志:
-- ::, INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at master01.hadoop.xxx.cn/xxx.xx.x.xxx:
-- ::, INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
-- ::, INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
-- ::, INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Cluster specification: ClusterSpecification{masterMemoryMB=, taskManagerMemoryMB=, numberTaskManagers=, slotsPerTaskManager=}
-- ::, WARN org.apache.flink.yarn.AbstractYarnClusterDescriptor - The configuration directory ('/root/flink-1.8.2/conf') contains both LOG4J and Logback configuration files. Please delete or rename one of them.
-- ::, INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Submitting application master application_1570496850779_0470
-- ::, INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1570496850779_0470
-- ::, INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Waiting for the cluster to be allocated
-- ::, INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Deploying cluster, current state ACCEPTED
-- ::, INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - YARN application has been deployed successfully.
Starting execution of program
Executing WordCount example with default input data set.
Use --input to specify file input.
Printing result to stdout. Use --output to specify output path.
(a,)
(action,)
(after,)
(against,)
......
可以看到,第一件事是连接yarn的resourcemanager。
./bin/flink run 命令解析:
run [OPTIONS] <jar-file> <arguments>
"run" 操作参数:
-c,--class <classname> 如果没有在jar包中指定入口类,则需要在这里通过这个参数指定
-m,--jobmanager <host:port> 指定需要连接的jobmanager(主节点)地址,使用这个参数可以指定一个不同于配置文件中的jobmanager
-p,--parallelism <parallelism> 指定程序的并行度。可以覆盖配置文件中的默认值。
默认查找当前yarn集群中已有的yarn-session信息中的jobmanager【/tmp/.yarn-properties-root】:
./bin/flink run ./examples/batch/WordCount.jar -input hdfs://hostname:port/hello.txt -output hdfs://hostname:port/result1
连接指定host和port的jobmanager:
./bin/flink run -m hadoop100: ./examples/batch/WordCount.jar -input hdfs://hostname:port/hello.txt -output hdfs://hostname:port/result1
启动一个新的yarn-session:
./bin/flink run -m yarn-cluster -yn ./examples/batch/WordCount.jar -input hdfs://hostname:port/hello.txt -output hdfs://hostname:port/result1
注意:yarn session命令行的选项也可以使用./bin/flink 工具获得。它们都有一个y或者yarn的前缀
例如:./bin/flink run -m yarn-cluster -yn ./examples/batch/WordCount.jar
Flink on yarn的内部实现
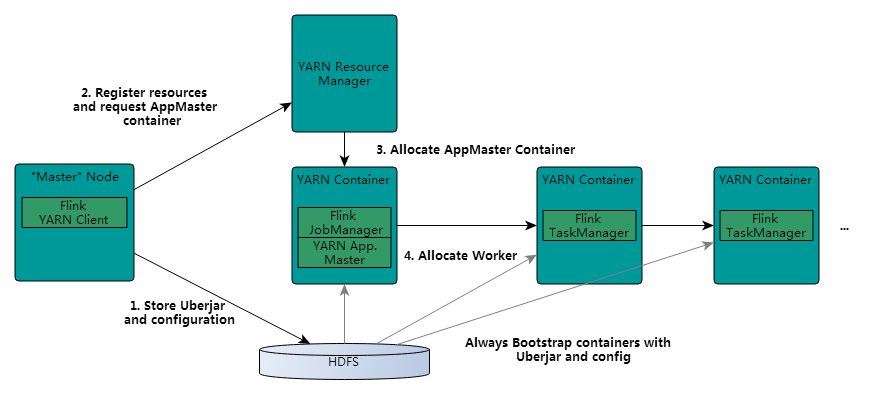
既然是on yarn,那必然需要知道yarn以及hdfs的相关配置,获取相关配置流程如下:
1,先检查有没有设置 YARN_CONF_DIR, HADOOP_CONF_DIR or HADOOP_CONF_PATH环境变量,如果其中之一设置了的话,那就通过此方式读取环境信息。
2,如果第一部分没有设置任何内容,那么客户端会去找HADOOP_HOME环境变量,然后访问$HADOOP_HOME/etc/hadoop路径下的配置文件。
当flink在提交一个任务时,客户端首先会检查资源是否可用(内存和cpu),然后上传flink jar包到hdfs。
然后客户端申请container启动applicationMaster,被选中的nodeManager初始化container,比如下载相关文件,然后启动applicationMaster。
JobManager和AM在同一个container中运行。AM也就知道JobManager的地址。然后为taskManager生成一个新的Flink配置文件(以便它们可以连接到JobManager)。文件也被上传到HDFS。此外,AM container还提供Flink的web接口。(yarn分配的所有端口都是临时端口。并且允许用户并行执行多个Flink任务)
之后,AM开始为Flink的taskManager分配container,后者将从HDFS下载jar包和修改后的配置文件。即可接收job然后执行
HA
因为单点故障的存在(single point of failure (SPOF))所以要做HA,实现HA又分flink standalone模式和on yarn模式
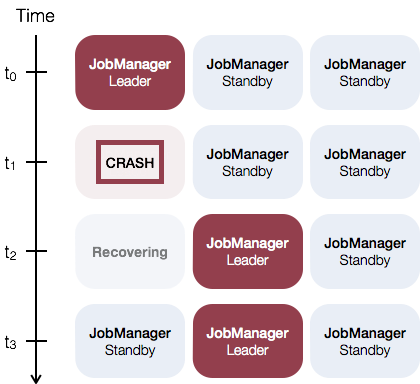
flink standalone模式下的HA
运行多个jobManager,其中一个为leader,其他为standby,通过zookeeper实现故障切换。如下图:
相关配置:
1.在conf/masters文件中添加多个jobManager主机和端口号,我这里环境如下
[root@master01 conf]# more masters
master01.hadoop.xxx.cn:
worker03.hadoop.xxx.cn:
2.修改conf/flink-conf.yaml文件,主要是指定通过zookeeper来实现HA
(我这里已有运行正常的cdh集群)
high-availability: zookeeper
high-availability.storageDir: hdfs:///flink/ha/
high-availability.zookeeper.quorum: master01.hadoop.xxx.cn:,worker01.hadoop.xxx.cn:,worker03.hadoop.xxx.cn:
此外,zookeeper是在/flink目录下存储对应的元数据(类似hbase),并且zk存储的并不是真正做recovery的元数据,数据其实是存储在hdfs上的,zk存储的只是指向hdfs路径的一个标识。
3.发flink包到各个节点
4.执行bin/start-cluster.sh
看wei界面
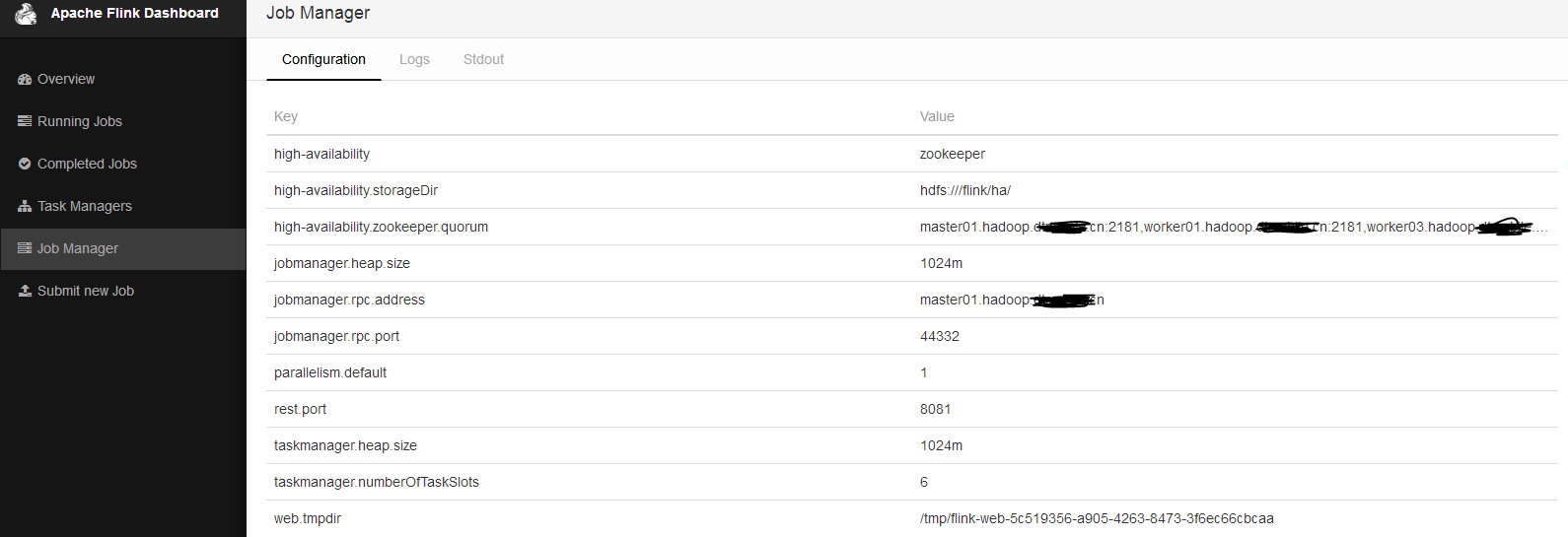
可以看到已经启用HA以及使用的zk集群,目前leader为master01节点。zk目录结构存储如下:
[zk: localhost:(CONNECTED) ] ls /
[flink, hive_zookeeper_namespace_hive, zookeeper, solr]
[zk: localhost:(CONNECTED) ] ls /flink
[default]
[zk: localhost:(CONNECTED) ] ls /flink/default
[jobgraphs, leader, leaderlatch]
kill掉master01节点的jobManager进程看能否实现切换,进程如下:
StandaloneSessionClusterEntrypoint
再访问web界面,如下:

Flink on yarn HA实现
基本上就是靠yarn本身失败重试的机制来重新启动jobManager(applicationMaster),具体看官网介绍:
https://ci.apache.org/projects/flink/flink-docs-release-1.10/ops/jobmanager_high_availability.html#yarn-cluster-high-availability
Flink on yarn以及实现jobManager 高可用(HA)的更多相关文章
- hadoop在zookeeper上的高可用HA
(参考文章:https://www.linuxprobe.com/hadoop-high-available.html) 一.技术背景 影响HDFS集群不可用主要包括以下两种情况:一是NameNode ...
- hadoop学习笔记(七):hadoop2.x的高可用HA(high avaliable)和联邦F(Federation)
Hadoop介绍——HA与联邦 0.1682019.06.04 13:30:55字数 820阅读 138 Hadoop 1.0中HDFS和MapReduce在高可用.扩展性等方面存在问题: –HDFS ...
- corosync+pacemaker实现高可用(HA)集群
corosync+pacemaker实现高可用(HA)集群(一) 重要概念 在准备部署HA集群前,需要对其涉及的大量的概念有一个初步的了解,这样在实际部署配置时,才不至于不知所云 资源.服务与 ...
- Corosync+Pacemaker+DRBD+MySQL 实现高可用(HA)的MySQL集群
大纲一.前言二.环境准备三.Corosync 安装与配置四.Pacemaker 安装与配置五.DRBD 安装与配置六.MySQL 安装与配置七.crmsh 资源管理 推荐阅读: Linux 高可用(H ...
- 浅谈web应用的负载均衡、集群、高可用(HA)解决方案(转)
1.熟悉几个组件 1.1.apache —— 它是Apache软件基金会的一个开放源代码的跨平台的网页服务器,属于老牌的web服务器了,支持基于Ip或者域名的虚拟主机,支持代理服务器,支持安 ...
- Hadoop 高可用(HA)的自动容灾配置
参考链接 Hadoop 完全分布式安装 ZooKeeper 集群的安装部署 0. 说明 在 Hadoop 完全分布式安装 & ZooKeeper 集群的安装部署的基础之上进行 Hadoop 高 ...
- 【高可用HA】Nginx (1) —— Mac下配置Nginx Http负载均衡(Load Balancer)之101实例
[高可用HA]Nginx (1) -- Mac下配置Nginx Http负载均衡(Load Balancer)之101实例 nginx版本: nginx-1.9.8 参考来源: nginx.org [ ...
- 浅谈web应用的负载均衡、集群、高可用(HA)解决方案
http://aokunsang.iteye.com/blog/2053719 声明:以下仅为个人的一些总结和随写,如有不对之处,还请看到的网友指出,以免误导. (详细的配置方案请google,这 ...
- web应用的负载均衡、集群、高可用(HA)解决方案
看看别人的文章: 1.熟悉几个组件 1.1.apache —— 它是Apache软件基金会的一个开放源代码的跨平台的网页服务器,属于老牌的web服务器了,支持基于Ip或者域名的虚拟主机,支持代 ...
随机推荐
- PHP常用的一些优化技巧
PHP常用的一些优化技巧 点击联系老杨 ecshop模板 php 优化技巧 老杨ecshop ecshop二次开发 2013-03-29 0 做为最流行的WEB语言, PHP他的突出优势就是其速度与效 ...
- 哈希表,Java中的hashCode
哈希表: 将我们所需的键通过哈希函数转换索引,然后存储在一个数组中. 哈希表是时间和空间之间的平衡,体现空间换时间的算法思想(联想到预加载,缓存等,有时候多存储,预处理缓存一些东西,带来时间复杂度的改 ...
- C. Maximum Median 二分
C. Maximum Median 题意: 给定一个数组,可每次可以选择一个数加1,共执行k次,问执行k次操作之后这个数组的中位数最大是多少? 题解:首先对n个数进行排序,我们只对大于中位数a[n/2 ...
- eclipse 编辑窗口不见了(打开左边的java、xml文件,中间不会显示代码)
参考:https://blog.csdn.net/u012062810/article/details/46729779
- SpringBoot之Feign调用方式比较
一:事发原因 两个东家都使用SpringCloud,巴拉巴拉用上了Spring全家桶,从eureka到ribbon,从ribbon到feign,从feign到hystrix,然后在使用feign的时候 ...
- Mybatis-问题总结
1.在mybatis里面注释语句的时候,一定用 <!- -需要注释的内容–>.用快捷键注释一行代码显示是/**/,但是实际执行起来报错.
- CSS元素和文本垂直居中
div居中 1.使用绝对定位和负外边距让块级元素垂直居中 要点:必须提前知道被居中块级元素的尺寸,否则无法准确实现垂直居中. <div id="box"> <di ...
- java 之word转html
jar包 链接: https://pan.baidu.com/s/13o2CZTwM-Igx6wcoyEu_ug 密码: n95q package com.bistu.service; import ...
- (转)spring mvc 中文乱码问题解决
在eclipse环境里,页面传输数据的时候通常用ISO-8859-1这个字符集可以用 str = new String(str.getBytes("ISO-8859-1"), &q ...
- docker 日志清理
首先确认 docker 使用的存储引擎 docker info 如果使用 Logging Driver: json-file, 那么日志默认在 /var/lib/docker/contains/xxx ...