052.Kubernetes集群管理-故障排错指南
一 故障指南
1.1 常见问题排障
- 查看Kubernetes对象的当前运行时信息,特别是与对象关联的Event事件。这些事件记录了相关主题、发生时间、最近发生时间、发生次数及事件原因等,对排查故障非常有价值。此外,通过查看对象的运行时数据,还可以发现参数错误、关联错误、状态异常等明显问题。由于在Kubernetes中多种对象相互关联,因此这一步可能会涉及多个相关对象的排查问题。
- 对于服务、容器方面的问题,可能需要深入容器内部进行故障诊断,此时可以通过查看容器的运行日志来定位具体问题。
- 对于某些复杂问题,例如Pod调度这种全局性的问题,可能需要结合集群中每个节点上的Kubernetes服务日志来排查。比如搜集Master上的kube-apiserver、kube-schedule、kube-controler-manager服务日志,以及各个Node上的kubelet、kube-proxy服务日志,通过综合判断各种信息,就能找到问题的成因并解决问题。
二 常见措施
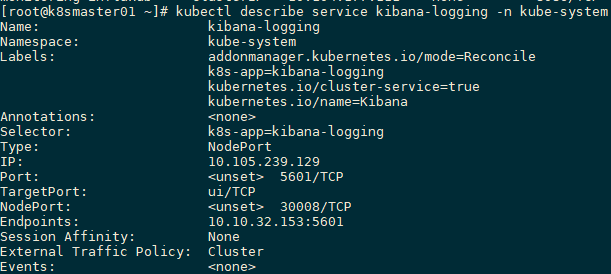
2.1 查看Event

- 没有可用的Node以供调度。
- 开启了资源配额管理, 但在当前调度的目标节点上资源不足。
- 镜像下载失败。
2.2 查看日志
2.3 查看Kubernetes服务日志

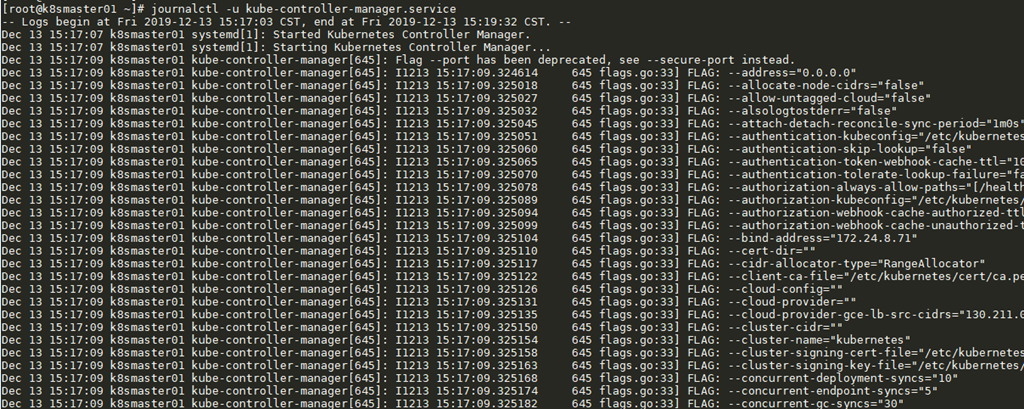
- --logtostderr=false:不输出到stderr。
- --log-dir=/var/log/kubernetes:日志的存放目录。
- --alsologtostderr=false:将其设置为true时,表示将日志同时输出到文件和stderr。
- --v=0:glog的日志级别。
- --vmodule=gfs*=2,test*=4:glog基于模块的详细日志级别。
- kube-controller-manager.ERROR;
- kube-controller-manager.INFO;
- kube-controller-manager.WARNING;
- kube-controller-manager.kubernetesmaster.unknownuser.log.ERROR.20150930-173939.9847;
- kube-controller-manager.kubernetesmaster.unknownuser.log.INFO.20150930-173939.9847;
- kube-controller-manager.kubernetesmaster.unknownuser.log.WARNING.20150930-173939.9847。
2.4 Kubernetes异常排查思路
三 常见Kubernetes问题
3.1 无法pull镜像
- 如果服务器可以访问Internet,并且不希望使用HTTPS的安全机制来访问gcr.io,则可以在Docker Daemon的启动参数中加上--insecure-registry gcr.io,来表示可以匿名下载。
- 如果Kubernetes集群在内网环境中无法访问gcr.io网站,则可以先通过一台能够访问gcr.io的机器下载pause镜像,将pause镜像导出后,再导入内网的Docker私有镜像库,并在kubelet的启动参数中加上--pod_infra_container_image,配置为:--pod_infra_container_image=<docker_registry_ip>:<port>/pause:3.1,之后重新创建redis-master即可正确启动Pod。
3.2 一直RESTARTS
3.3 通过服务名无法访问
- 查看Service的后端Endpoint是否正常
- Service的LabelSelector与Pod的Label不匹配;
- 后端Pod一直没有达到Ready状态(通过kubectlgetpods进一步查看Pod的状态);
- Service的targetPort端口号与Pod的containerPort不一致等。
- 查看Service的名称能否被正确解析为ClusterIP地址
- 查看kube-proxy的转发规则是否正确
052.Kubernetes集群管理-故障排错指南的更多相关文章
- 美团点评Kubernetes集群管理实践
背景 作为国内领先的生活服务平台,美团点评很多业务都具有非常显著.规律的”高峰“和”低谷“特征.尤其遇到节假日或促销活动,流量还会在短时间内出现爆发式的增长.这对集群中心的资源弹性和可用性有非常高的要 ...
- 基于Python+Django的Kubernetes集群管理平台
➠更多技术干货请戳:听云博客 时至今日,接触kubernetes也有一段时间了,而我们的大部分业务也已经稳定地运行在不同规模的kubernetes集群上,不得不说,无论是从应用部署.迭代,还是从资源调 ...
- 快速部署Kubernetes集群管理
这篇文章介绍了如何快速部署一套Kubernetes集群,下面就快速开始吧! 准备工作 //关闭防火墙 systemctl stop firewalld.service systemctl disabl ...
- kubernetes集群管理常用命令一
系列目录 我们把集群管理命令分为两个部分,第一部分介绍一些简单的,但是可能是非常常用的命令以及一些平时可能没有碰到的技巧.第二部分将综合前面介绍的工具通过示例来讲解一些更为复杂的命令. 列出集群中所有 ...
- 049.Kubernetes集群管理-集群监控Metrics
一 集群监控 1.1 Metrics Kubernetes的早期版本依靠Heapster来实现完整的性能数据采集和监控功能,Kubernetes从1.8版本开始,性能数据开始以Metrics API的 ...
- Kubernetes集群管理工具kubectl命令技巧大全
一. kubectl概述 Kubectl是用于控制Kubernetes集群的命令行工具,通过kubectl能够对集群本身进行管理,并能够在集群上进行容器化应用的安装部署. kubectl命令的语法如下 ...
- kubernetes集群管理之通过jq来截取属性
系列目录 首先要声明,这里的jq并不是批前端框架里的jquery,而是一个处理json的命令行工具. jq工具相比yq,它更加成熟,功能也更加强大,主要表现在以下几个方面 支持递归查找(我点对我们平时 ...
- kubernetes集群管理命令(三)
系列目录 前面两节我们由浅入深介绍了不少kubernetes管理比较常用的命令.本节我们通过案例讲解一些需要更为复杂的操作才能完成的命令. 选择一个deployment下的所有pod 前面讲到过,ku ...
- kubernetes集群管理命令(二)
系列目录 上一节我们介绍了一些基本的命令,这一节我们介绍一些更为复杂的命令. pod排序 使用kubectl get pod获取pod资源默认是以名称排序的,有些时候我们可能希望按其它顺序排序.比如说 ...
随机推荐
- vue-element-admin 模板 登录页面 post请求通过django的csrf认证,处理304错误
经过一天的研究,终于把 vue-admin-template 模板的 post 请求 和django的api 弄通了 没有了那该死的304报错了 直接贴代码: 在main.js中 我直接给设置了一个 ...
- Android 版的多合一Office应用也正式向iOS开放了
导读 在 Android 版的多合一 Office 应用「偷跑」不久后(官方证实上线时间比计划要早),为 iOS 准备的版本现在终于也结束 beta 测试正式上线了. 和只提供「有限」平板支持的 An ...
- 关于.NET中的控制反转及AutoFac的简单说明
目录 1.控制反转 1.1 什么是依赖? 1.2 什么是控制反转? 1.3 什么是依赖注入? 1.4 简单总结 2.控制反转容器 2.1 IOC容器说明 2.2 使用AutoFac的简介示例 3 使用 ...
- Python数据基本类型3
-*- coding:utf-8 -*-字典 键值对数据 dict dic = {'键':'值'}存储数据 字典的查找快一些不可哈希的,就是可变的数据 可变的数据不能哈希 不可变的数据能哈希 pyth ...
- 洛谷P1000超级马里奥的神奇解法
话说上过洛谷的都知道,有一道经典例题P1000超级马里奥,这一题,可以说是非常简单非常经典,但是就算如此,还是可以人才辈出,我是个比较循规蹈矩的人(雾),所以我的代码就比较平常,也就是直接输出了所要求 ...
- Spark入门(五)--Spark的reduce和reduceByKey
reduce和reduceByKey的区别 reduce和reduceByKey是spark中使用地非常频繁的,在字数统计中,可以看到reduceByKey的经典使用.那么reduce和reduceB ...
- Python深度学习 deep learning with Python
内容简介 本书由Keras之父.现任Google人工智能研究员的弗朗索瓦•肖莱(François Chollet)执笔,详尽介绍了用Python和Keras进行深度学习的探索实践,涉及计算机视觉.自然 ...
- vue相关的前端UI库
1,element-ui 这个笔者用的最多,但是官网不知道咋回事.打不开,难道被黑了?! 地址(http://element-ui.cn/#/zh-CN/component/installation) ...
- Burpsuite被动扫描流量转发插件:Passive Scan Client
编译成品:链接: https://pan.baidu.com/s/1E0vsPGgPgB9bXCW-8Yl1gw 提取码: 49eq Passive Scan Client Burpsuite被动扫描 ...
- Mac brew命令的使用
mac 终端程序管理工具 能让你更快速的安装你想要的工具.而不用考虑大量的依赖. 安装brew复制下面的命令,终端执行 官网Homebrew /usr/bin/ruby -e "$(cur ...