adaboost 基于错误提升分类器
引自(机器学习实战)
简单概念
Adaboost是一种弱学习算法到强学习算法,这里的弱和强学习算法,指的当然都是分类器,首先我们需要简单介绍几个概念。
1:弱学习器:在二分情况下弱分类器的错误率会低于50%。其实任意的分类器都可以做为弱分类器,比如之前介绍的KNN、决策树、Naïve Bayes、logiostic回归和SVM都可以。这里我们采用的弱分类器是单层决策树,它是一个单节点的决策树。它是adaboost中最流行的弱分类器,当然并非唯一可用的弱分类器。即从特征中选择一个特征来进行分类,该特征能使错误率达到最低,注意这里的错误率是加权错误率,为错分样本(1)与该样本的权重的乘积之和(不明白看后面代码)。
更为严格点的定义:
2:强学习器:识别准确率很高并能在多项式时间内完成的学习算法
3:集成方法:就是将不同的分类器组合在一起,这种组合的结果就是集成方法或者称为元算法。它可以是不同算法的集成,也可以是同一算法在不同设置下的集成,还可以是数据集的不同部分分配给不同分类器后的集成。
4:通常的集成方法有bagging方法和boosting方法,adaboost是boosting的代表算法,他们的区别在于:bagging方法(bootstrapaggregating),中文为自举汇聚法,是从原始数据集重选择(有放回,可以重复)得到S个新数据集的一种技术,每个新数据集样本数目与原数据集样本数目相等,这样就可以得到S个分类器,再对这S个分类器进行叠加,他们的权重都相等(当然这里S个分类器采用的分类算法不一样的话,可以考虑使用投票),这样就可以得到一个强学习器。
而boosting方法是通过集中关注被已有分类器错分的那些数据来获得新的分类器,boosting算法中分类的权重并不相等,每个权重代表的是其对应分类器在上一轮迭代中的成功度。这里不是太明白的话,看完后面adaboost算法就会明白这句话的含义。
5:adaboost算法:机器学习实战这本书上的描述和论文中的描述是一致的,见下面(前两幅是书中描述,后一副是论文中描述)。
adaboost运行过程如下:训练数据中的每一个样本,赋予其一个权重,这些权重构成了向量D,一开始,这些权重都初始化成相等值。
首先在训练数据中训练出一个弱分类器并计算改分类器的错误率,然后在同一数据集上再次训练弱分类器。在分类器的第二次训练当中
,将会重新调整每个样本的权重,其中第一次分对的样本的权重将会降低,而第一次分错的样本权重将会提高。为了从所有弱分类器中
得到最终的分类结果,adaboost为每个分类器都分配一个权重值alpha,这些alpha值都是基于每个弱分类器的错误率进行计算的。
其中错误率定义为

alpha计算公式
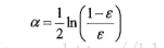



问题:上题中的alpha为什么是这个公式呢?解释为:-----再看没看懂!!

(1)基于单层决策树构建弱分类器
def loadSimDat():
dataMat = matrix([[1, 2.1],
[2.0, 1.1],
[1.3, 1.0],
[1.0, 1.0],
[2.0, 1.0]])
classLabels = [1.0, 1.0, -1.0, -1.0, 1.0]
return dataMat, classLabels # 单层决策树生成函数
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):#just classify the data
retArray = ones((shape(dataMatrix)[0],1))
if threshIneq == 'lt':
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0
return retArray def buildStump(dataArr, classLabels, D):
dataMatrix = mat(dataArr); labelMat = mat(classLabels).T
m,n = shape(dataMatrix)
numSteps = 10.0; bestStump = {}; bestClassEst = mat(zeros((m,1)))
minError = inf
for i in range(n):
rangeMin = dataMatrix[:,i].min(); rangeMax = dataMatrix[:,i].max();
stepSize = (rangeMax - rangeMin)/numSteps
for j in range(-1, int(numSteps)+1):
for inequal in ['lt','gt']:
threshVal = (rangeMin + float(j)*stepSize)
predictedVals = stumpClassify(dataMatrix, i, threshVal, inequal)
errArr = mat(ones((m,1)))
errArr[predictedVals == labelMat] = 0
weightedError = D.T * errArr #这里的error是错误向量errArr和权重向量D的相应元素相乘得到的即加权错误率
#print "split: dim %d, thresh %.2f, thresh inequal: %s, the weighted error is %.3f" %(i, threshVal, inequal, weightedError)
if weightedError < minError:
minError = weightedError
bestClassEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump, minError, bestClassEst

注意这里有三层循环构建了单层决策树,最外层循环为遍历特征,次外层循环为遍历的步长,最内层为是否大于或小于阀值。构建的最小错误率为加权错误率,这就是为什么增加分错样本的权重,因为分错样本的权重增加了,下次如果继续分错,加权错误率会很大,这就不满足算法最小化加权错误率了。此外,加权错误率在每次迭代过程中一定是逐次降低的。。
(2)完整的adaboost算法
def adaBoostTrainDS(dataArr, classLabels, numIt = 40):
weakClassArr = []
m = shape(dataArr)[0]
D = mat(ones((m,1))/m)
aggClassEst = mat(zeros((m,1)))
for i in range(numIt):
bestStump, error, classEst = buildStump(dataArr, classLabels, D)
# print "D:", D.T
alpha = float(0.5 * log((1.0 - error)/max(error, 1e-16))) #确保在没有错误时不会发生除零溢出
bestStump['alpha'] = alpha
weakClassArr.append(bestStump)
#print "classEst:", classEst.T
expon = multiply(-1 * alpha * mat(classLabels).T, classEst) #乘法用于区分是否正确或者错误样本
D = multiply(D, exp(expon))
D = D/D.sum() # 归一化用的
aggClassEst += alpha * classEst #累加变成强分类器
aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T, ones((m,1)))
errorRate = aggErrors.sum()/m
print "total error: ", errorRate, "\n"
if errorRate == 0.0: break
return weakClassArr, aggClassEst

注意代码中的一个技巧max(error,le-16)用于确保在没有错误时不会发生除零溢出。
(3) 测试算法:基于adaboost的分类
#adaboost分类函数
def adaClassify(datToClass, classifierArr):
dataMatrix = mat(datToClass)
m = shape(dataMatrix)[0]
aggClassEst = mat(zeros((m,1)))
for i in range(len(classifierArr)):
classEst = stumpClassify(dataMatrix, classifierArr[i]['dim'], classifierArr[i]['thresh'], classifierArr[i]['ineq'])
aggClassEst += classifierArr[i]['alpha']*classEst
print aggClassEst
return sign(aggClassEst)

此外如何理论上证明弱学习分类器可以通过线性叠加提升为强学习分类器,有两种证明方法:(1)通过误差上界,(2)通过adaboost的损失函数(指数损失函数)来证明。推导看以参看:http://blog.csdn.net/v_july_v/article/details/40718799, 其中我只看了误差上界的推导。
误差上界的结论表明,AdaBoost的训练误差是以指数速率下降的。另外,AdaBoost算法不需要事先知道下界γ,AdaBoost具有自适应性,它能适应弱分类器各自的训练误差率 。
只要保证弱分类器的错误率小于0.5,每次e^(2Mr^2))肯定是不断减小的
adaboost 基于错误提升分类器的更多相关文章
- 基于Haar特征的Adaboost级联人脸检测分类器
基于Haar特征的Adaboost级联人脸检测分类器基于Haar特征的Adaboost级联人脸检测分类器,简称haar分类器.通过这个算法的名字,我们可以看到这个算法其实包含了几个关键点:Haar特征 ...
- 照片美妆---基于Haar特征的Adaboost级联人脸检测分类器
原文:照片美妆---基于Haar特征的Adaboost级联人脸检测分类器 本文转载自张雨石http://blog.csdn.net/stdcoutzyx/article/details/3484223 ...
- 基于sklearn的分类器实战
已迁移到我新博客,阅读体验更佳基于sklearn的分类器实战 完整代码实现见github:click me 一.实验说明 1.1 任务描述 1.2 数据说明 一共有十个数据集,数据集中的数据属性有全部 ...
- SQL注入之Sqli-labs系列第十八关(基于错误的用户代理,头部POST注入)
开始挑战第十八关(Header Injection - Uagent field - Error based) 常见的HTTP注入点产生位置为[Referer].[X-Forwarded-For].[ ...
- 【sqli-labs】 less28 GET- Error based -All you Union&Select Belong to us -String -Single quote with parenthesis(GET型基于错误的去除了Union和Select的单引号带括号字符串型注入)
这个不是基于错误的吧,看源码可以知道错误并没有输出 那就使用;%00和order by试一下 http://192.168.136.128/sqli-labs-master/Less-28/?id=1 ...
- 【sqli-labs】 less17 POST - Update Query- Error Based - String (基于错误的更新查询POST注入)
这是一个重置密码界面,查看源码可以看到username作了防注入处理 逻辑是先通过用户名查出数据,在进行密码的update操作 所以要先知道用户名,实际情况中可以注册用户然后实行攻击,这里先用admi ...
- 机器学习(七)—Adaboost 和 梯度提升树GBDT
1.Adaboost算法原理,优缺点: 理论上任何学习器都可以用于Adaboost.但一般来说,使用最广泛的Adaboost弱学习器是决策树和神经网络.对于决策树,Adaboost分类用了CART分类 ...
- 使用 AdaBoost 元算法提高分类器性能
前言 有人认为 AdaBoost 是最好的监督学习的方式. 某种程度上因为它是元算法,也就是说它会是几种分类器的组合.这就好比对于一个问题能够咨询多个 "专家" 的意见了. 组合的 ...
- 第九篇:使用 AdaBoost 元算法提高分类器性能
前言 有人认为 AdaBoost 是最好的监督学习的方式. 某种程度上因为它是元算法,也就是说它会是几种分类器的组合.这就好比对于一个问题能够咨询多个 "专家" 的意见了. 组合的 ...
随机推荐
- js的执行和调试
JavaScript 是指在浏览器运行的脚本 脚本就是剧本,在指定场景,特定时间,规定角色的对白,动作,情绪的变化 并且js是同步的,单线程的执行脚本 同步异步 js的运行是同步的, 运行完第一行才会 ...
- java核心-多线程(8)- 并发原子类
使用锁能解决并发时线程安全性,但锁的代价比较大,而且降低性能.有些时候可以使用原子类(juc-atomic包中的原子类).还有一些其他的非加锁式并发处理方式,我写这篇文章来源于Java中有哪些 ...
- 012-PHP创建一个多维数组
<?php $Cities = array( //二维数组array() "华北地区"=>array( "北京市", "天津市" ...
- 接口补偿机制需求分析&方案设计
接口补偿机制需求分析&方案设计文章目录接口补偿机制需求分析&方案设计需求分析背景解决方案业务示例注意事项示例业务Controller实现重试信息类&数据处理入库接口重试的主要方 ...
- WFP之WFP简介
·过滤引擎是WFP的核心组成部分,过滤引擎分为两大层:用户态基础过滤引擎和内核态过滤引擎.基础过滤引擎会与内核过滤引擎交互.·内核态过滤引擎是整个过滤引擎的主体,内部分为多个分层,每分层都代表着网络协 ...
- JAVA - Intellij IDEA 中去掉mybatis Mapper.xml背景色
JAVA - Intellij IDEA 中去掉mybatis Mapper.xml背景色 1:现在公司中使用mybatis的频率非常高,一般都会用MBG来生成基础的代码文件.在intellij中查看 ...
- 理解依赖注入(DI - Dependency Injection)
系列教程 Spring 框架介绍 Spring 框架模块 Spring开发环境搭建(Eclipse) 创建一个简单的Spring应用 Spring 控制反转容器(Inversion of Contro ...
- 黑马oracle_day01:02.oracle的基本操作
01.oracle体系结构 02.oracle的基本操作 03.oracle的查询 04.oracle对象 05.oracle编程 02.oracle的基本操作 PLSQL中文乱码问题解决1.查看服务 ...
- 第十八篇 admin组件
admin组件 admin组件使用 admin源码解析 admin组件使用 Django 提供了基于 web 的管理工具. Django 自动管理工具是 django.contrib 的一部分.你可以 ...
- xml学习-语法规则
XML 指可扩展标记语言(eXtensible Markup Language).XML 被设计用来传输和存储数据. XML 语法规则 XML 文档必须有根元素 XML 必须包含根元素,它是所有其他元 ...