python 爬虫之 urllib库
文章更新于:2020-03-02
注:代码来自老师授课用样例。
一、初识 urllib 库
在 python2.x 版本,urllib 与urllib2 是两个库,在 python3.x 版本,二者合一为 urllib。
二、实践 urllib 库
1、爬取页面并输出
'''
初识urllib库,如何使用urllib库爬取一个网页
1、导入urllib.request模块
2、使用urllib.request.urlopen()方法打开并爬取一个网页
3、使用response.read()读取网页内容,并以utf-8格式进行转码
'''
import urllib.request # 导入urllib.request库
response = urllib.request.urlopen("http://httpbin.org") #爬取'http://httpbin.org'网页
print(response.read().decode('utf-8')) # 打印以'utf-8'转码后的爬取结果
'''
urlopen方法,该方法有三个常用参数
urllib.request.urlopen(url,data,timeout)
url表示需要打开的网址;
data表示访问网址时需要传送的数据,一般在使用POST请求时使用;
timeout是设置网站的访问超时时间。
'''
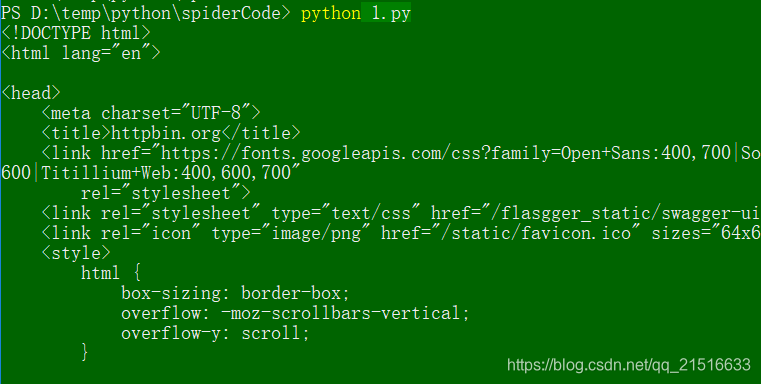
代码执行结果如下:
2、post数据提交
'''
使用urllib库中的POST方法获取网页
'''
import urllib.parse # urllib.parse 为url解析模块
import urllib.request
# urlencode的参数是字典,他可以将key-value这样的键值对转换成需要的格式
data = bytes(urllib.parse.urlencode({'word':'hello'}),encoding ='utf-8')
print(data)
response = urllib.request.urlopen('http://httpbin.org/post',data = data)
print(response.read().decode('utf-8'))
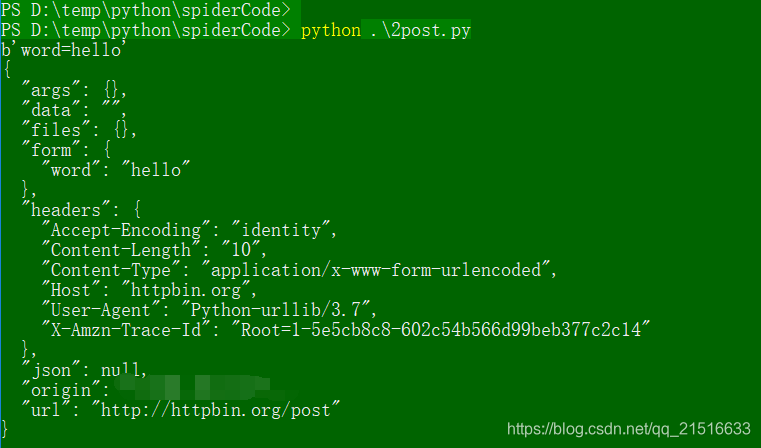
代码执行结果如下:
3、将爬取结果保存为文件
# 将爬取的网页保存为本地文件
import urllib.request
response = urllib.request.urlopen("http://httpbin.org")
data = response.read()
filehandle = open('D:/1.html',"wb") # 通过open()函数以wb(二进制写入)的方式打开文件
filehandle.write(data)
filehandle.close
'''
代码中首先通过open()函数以wb(二进制写入)的方式打开文件,
打开后再将其赋值给变量filehandle,
然后再用write()方法将爬取的data数据写入打开的文件中,
写入完成后使用close()方法关闭该文件,使其不能再进行读写操作,程序到此结束。
'''
'''
# 还可以使用urllib.request中的urlretrieve()方法直接将对应信息写入本地文件,具体代码如下
import urllib.request
filename = urllib.request.urlretrieve("http://httpbin.org",
filename = "D:/1.html")
'''
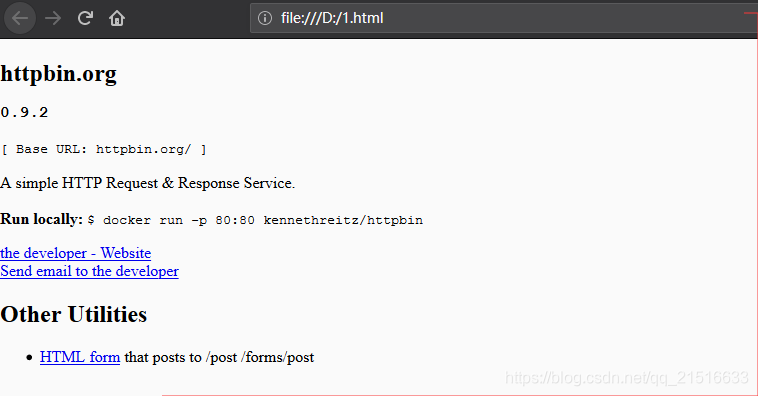
代码执行结果:

文件打开如图:
4、打印爬取结果的信息
# 获取网页信息、状态码、地址
import urllib.request
file = urllib.request.urlopen("http://httpbin.org")
print(file.info()) # 网页信息
print(file.getcode()) # 返回状态码 返回200表示响应正确
print(file.geturl()) # 返回URL
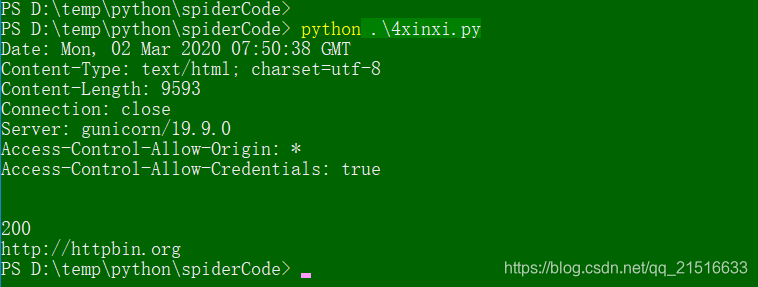
代码执行结果如图:
5、为爬虫设置超时时间
# 设置超时时间
# 在爬取网页时正确设置timeout的值,可以避免超时异常。格式为:urllib.request.urlopen("url",timeout=default)
import urllib.request
for i in range(1,10):
try:
file = urllib.request.urlopen("http://www.zhihu.com",
timeout=0.3) # 打开网页超时设置为3秒
data = file.read()
print(len(data)) # 打印爬取内容的长度
except Exception as e: # 捕捉异常
print("异常了……"+str(e))
代码执行结果如下:
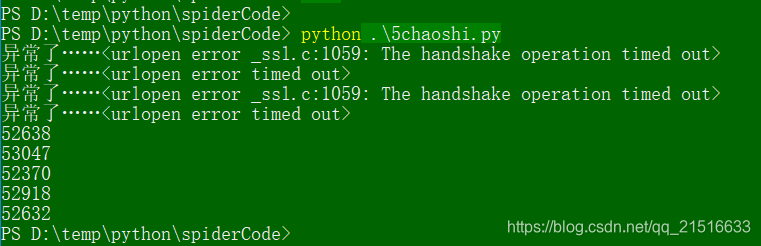
6、带参数爬取
'''
在浏览器输入网址www.codingke.com,可以打开扣丁学堂首页
然后在打开的页面检索关键词php,可以发现URL发生了变化,变成http://www.codingke.com/search/course?keywords=php。
这里keywords=php刚好是需要查询的信息,因此字段keywords对应的值就是用户检索的关键词。
由此可见,在扣丁学堂查询一个关键词时,会使用GET请求,其中关键字段是keywords,查询格式就是http://www.codingke.com/search/course?keywords=关键词。
若要实现用爬虫自动地在扣丁学堂上查询关键词是php的结果,并保存到本地文件,示例代码如下
'''
import urllib.request
keywd='php'
url='http://www.codingke.com/search/course?keywords='+keywd
req=urllib.request.Request(url)
data=urllib.request.urlopen(req).read()
fhandle=open("D:/php.html",'wb')
fhandle.write(data)
fhandle.close()
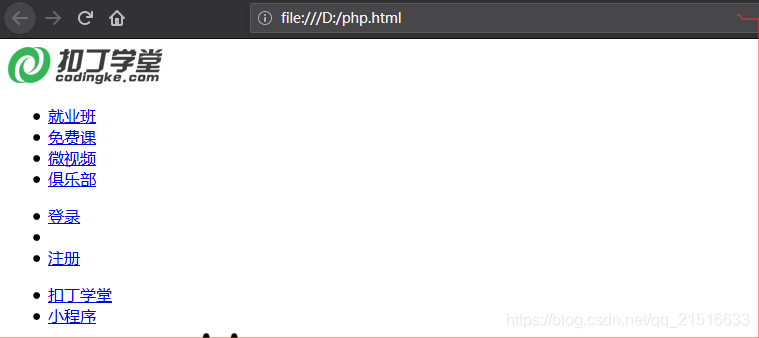
代码执行结果:
 文件打开如图:
文件打开如图:
7、带中文参数查询
'''
当要检索的关键词是中文时,
需要使用urllib.request.quote()对关键词部分进行编码,编码后重新构造完整URL
'''
import urllib.request
url = 'http://www.codingke.com/search/course?keywords='
keywd = '开发' # 使用中文查询
key_code = urllib.request.quote(keywd) # 对关键字编码
url_all = url+key_code # 字符串拼接
req = urllib.request.Request(url_all)
data = urllib.request.urlopen(req).read()
fhandle = open('D:/dev.html','wb')
fhandle.write(data)
fhandle.close()
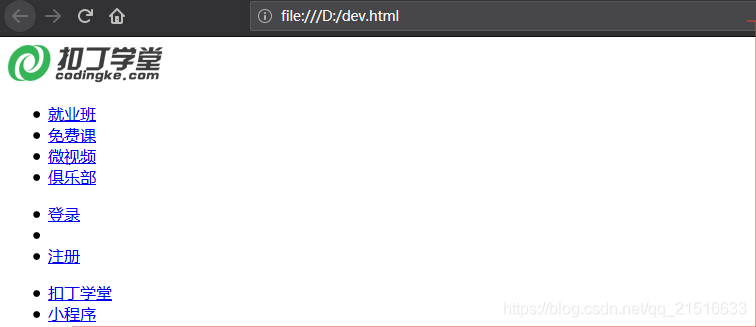
代码执行结果:
 文件打开如图:
文件打开如图:
8、使用代理
'''
# 设置代理服务
当使用同一个IP地址,频繁爬取网页时,网站服务器极有可能屏蔽这个IP地址。
在西刺网站中有很多免费代理服务器地址,其网址为http://www.xicidaili.com/
接下来通过一个示例示范使用代理IP进行爬取网页,比如地址为222.95.240.191,端口号为3000的代理IP
'''
import urllib
# 创建代理函数
def use_proxy(proxy_addr,url):
import urllib.request
# 代理服务器信息
proxy = urllib.request.ProxyHandler({'http':proxy_addr})
#创建opener对象
opener = urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
data = urllib.request.urlopen(url).read().decode('utf-8')
return data
proxy_addr = '222.95.240.191:3000'
data = use_proxy(proxy_addr,"http://www.1000phone.com")
print('网页数据长度是:',len(data))
'''
例中首先创建函数use_proxy(proxy_addr, url),该函数的功能是实现使用代理服务器爬取URL网页。
其中,第一个形参proxy_addr填写代理服务器的IP地址及端口,第二个参数url填写待爬取的网页地址。
通过urllib.request.ProxyHandler()方法来设置对应的代理服务器信息,
接着使用urllib.request.build_opener()方法创建一个自定义的opener对象,
该方法中第一个参数是代理服务器信息,第二个参数是类。
urllib.request.install_opener()创建全局默认的opener对象,
那么在使用urlopen()时也会使用本文安装的全局opener对象,
因此下面可以直接使用urllib.request.urlopen()打开对应网址爬取网页并读取,
紧接着赋值给变量data,最后将data的值返回给函数。
'''
代码执行结果如下:
执行失败,代理IP过期。
9、异常处理1
# 在程序运行中难免发生异常,对于异常的处理是编写程序时经常要考虑的问题。
'''
首先需要导入异常处理的模块——urllib.error模块
Python代码中处理异常需要使用try-except语句,
在try中执行主要代码,在except中捕获异常,并进行相应的异常处理。
产生URLError异常的原因一般包括网络无连接、连接不到指定服务器、服务器不存在等。
在确保使用的计算机正常联网的情况下,下面通过处理一个不存在的地址(http://www.xyxyxy.cn)来演示URLError类处理URLError异常的过程。
'''
# 使用异常处理模块处理URL不存在异常 3-6
import urllib.request
import urllib.error
try:
urllib.request.urlopen("http://www.a.b.c") # 爬取不存在的url
except urllib.error.URLError as e: # 主动捕捉异常
print(e.reason) # 输出异常原因
'''
例中请求了一个不存在的url地址,
该错误会引发except程序块执行,并通过urllib.error.URLError as e捕获异常信息e,
输出了错误的原因(e.reason),错误的原因为“getaddrinfo failed”,即获取地址信息失败。
'''
代码执行结果如下:

10、异常处理2
'''
在使用URLError处理异常时,还有一种包含状态码的异常。
下面通过在千锋官网网址(http://www.1000phone.com)后拼接一个“/1”的错误网址来演示使用URLError类处理该类错误的过程,具体如例所示。
'''
# 使用异常处理模块处理URL错误的异常 3-7
import urllib.request
import urllib.error
try:
urllib.request.urlopen("http://1000phone.com/1") # 爬取不存在的url
except urllib.error.URLError as e: # 主动捕捉异常
# print(e) # 打印异常信息
# print(dir(e)) # 查看e的属性以方法
print(e.code) # 输出异常状态码
print(e.reason) # 输出异常原因
'''
例中请求了一个错误的URL地址,输出状态码“404”,异常原因是“Not Found”。
之前提到,产生异常的原因有如下几种:
网络无连接。 连接不到指定服务器。 服务器无响应
在例中,404异常不属于上述三者,而是由于触发了HTTPError异常。
与URLError异常不同的是,HTTPError异常中一定含有状态码,而本例中之所以可以打印出状态码,是因为该异常属于HTTPError
'''
代码执行结果如下:

11、异常处理3
# 3-11 使用HTTPError类与URLError类处理异常
import urllib.error
import urllib.request
try:
urllib.request.urlopen("http://www.1000phone.cc")
except urllib.error.HTTPError as e : # 先用子类异常处理
print(e.code)
print(e.reason)
except urllib.error.URLError as e : # 再用父类异常处理
print(e.reason)
12、异常处理4
# 3-12 使用URLError处理HTTPError异常
import urllib.request
import urllib.error
try:
urllib.request.urlopen("http://www.1000phone.cc")
except urllib.error.URLError as e :
if hasattr(e,'code'): # 使用hasattr判断e中是否有code属性
print(e.code) # 打印状态码
print(e.reason)
13、异常处理
'''
在使用URLError处理异常时,还有一种包含状态码的异常。
下面通过在千锋官网网址(http://www.1000phone.com)后拼接一个“/1”的错误网址来演示使用URLError类处理该类错误的过程,具体如例所示。
'''
# 使用异常处理模块处理URL错误的异常 3-7
import urllib.request
import urllib.error
try:
urllib.request.urlopen("http://1000phone.com/1") # 爬取不存在的url
except urllib.error.URLError as e: # 主动捕捉异常
# print(e) # 打印异常信息
# print(dir(e)) # 查看e的属性以方法
print(e.code) # 输出异常状态码
print(e.reason) # 输出异常原因
'''
例中请求了一个错误的URL地址,输出状态码“404”,异常原因是“Not Found”。
之前提到,产生异常的原因有如下几种:
网络无连接。 连接不到指定服务器。 服务器无响应
在例中,404异常不属于上述三者,而是由于触发了HTTPError异常。
与URLError异常不同的是,HTTPError异常中一定含有状态码,而本例中之所以可以打印出状态码,是因为该异常属于HTTPError
'''
三、Enjoy!
python 爬虫之 urllib库的更多相关文章
- python爬虫之urllib库(三)
python爬虫之urllib库(三) urllib库 访问网页都是通过HTTP协议进行的,而HTTP协议是一种无状态的协议,即记不住来者何人.举个栗子,天猫上买东西,需要先登录天猫账号进入主页,再去 ...
- python爬虫之urllib库(二)
python爬虫之urllib库(二) urllib库 超时设置 网页长时间无法响应的,系统会判断网页超时,无法打开网页.对于爬虫而言,我们作为网页的访问者,不能一直等着服务器给我们返回错误信息,耗费 ...
- python爬虫之urllib库(一)
python爬虫之urllib库(一) urllib库 urllib库是python提供的一种用于操作URL的模块,python2中是urllib和urllib2两个库文件,python3中整合在了u ...
- python爬虫之urllib库介绍
一.urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib. ...
- Python 爬虫之urllib库的使用
urllib库 urllib库是Python中一个最基本的网络请求库.可以模拟浏览器的行为,向指定的服务器发送一个请求,并可以保存服务器返回的数据. urlopen函数: 在Python3的urlli ...
- python爬虫入门urllib库的使用
urllib库的使用,非常简单. import urllib2 response = urllib2.urlopen("http://www.baidu.com") print r ...
- python爬虫之urllib库
请求库 urllib urllib主要分为几个部分 urllib.request 发送请求urllib.error 处理请求过程中出现的异常urllib.parse 处理urlurllib.robot ...
- Python爬虫系列-Urllib库详解
Urllib库详解 Python内置的Http请求库: * urllib.request 请求模块 * urllib.error 异常处理模块 * urllib.parse url解析模块 * url ...
- python爬虫03 Urllib库
Urllib 这可是 python 内置的库 在 Python 这个内置的 Urllib 库中 有这么 4 个模块 request request模块是我们用的比较多的 就是用它来发起请求 所以我 ...
随机推荐
- Redis(9)——史上最强【集群】入门实践教程
一.Redis 集群概述 Redis 主从复制 到 目前 为止,我们所学习的 Redis 都是 单机版 的,这也就意味着一旦我们所依赖的 Redis 服务宕机了,我们的主流程也会受到一定的影响,这当然 ...
- 利用mnist数据集进行深度神经网络
初始神经网络 这里要解决的问题是,将手写数字的灰度图像(28 像素 x28 像素)划分到 10 个类别中(0~9).我们将使用 MINST 数据集,它是机器学习领域的一个经典数据集,其历史几乎和这个领 ...
- 一、create-react-app的安装及使用
一.安装create-react-app 1.在全局环境中安装create-react-app npm install -g create-react-app 2.在您所需要的目录(盘)下生成一个项目 ...
- 量化学习 | Tushare 基本面选股 (二)
量化投资比较重要的是策略,可是你得先选个好股,价值投资需要认同他的价值,值得投资的股票才有投资的机会,现在简单介绍一下基于基本面的选股,其实我现实生活中也有炒股,都是经验之说的选股原则. 首先从tus ...
- JavaScript零宽字符
什么是零宽字符 一种不可打印的Unicode字符, 在浏览器等环境不可见, 但是真是存在, 获取字符串长度时也会占位置, 表示某一种控制功能的字符. 常见的零宽字符有哪些 零宽空格(zero-widt ...
- 阿里淘宝的S1级别bug,到底是谁的锅?
3月25日,阿里的淘宝APP在IOS系统上出现BUG: 在打开淘宝APP以后,用户就会收到系统弹窗通知:“您使用的程序是测试/内测版本,将于当地时间2020-03-28到期,到期后将无法使用,请尽快下 ...
- python3正则提取字符串里的中文
# -*- coding: utf-8 -*- import re #过滤掉除了中文以外的字符 str = "hello,world!!%[545]你好234世界..." str ...
- CentOS 7.3下安装MySql
1.下载mysql源安装包 wget http://dev.mysql.com/get/mysql57-community-release-el7-8.noarch.rpm 2.安装mysql源 ...
- Redis缓存设计与性能优化
Redis我们一般是用作缓存,扛并发:或者用于某些特定的业务场景,比如前面说到redis各种数据类型的使用场景以及redis的哨兵和集群模式. 这里主要整理了下redis用作缓存,存在的一些问题,以及 ...
- 【C++】Strassen算法代码
本文仅代码,无理论解释 实话实说,我觉得这个算法在C系列的语言下,简直垃圾到爆炸--毕竟是一群完全不懂程序数学家对着纸弄出来的,看起来好像非常的有用,实际上耗时是非常爆炸的. 但是<算法导论&g ...