(转) Sqoop使用实例讲解
原博客地址:http://blog.csdn.net/evankaka
摘要:本文主要讲了笔者在使用sqoop过程中的一些实例
一、概述与基本原理
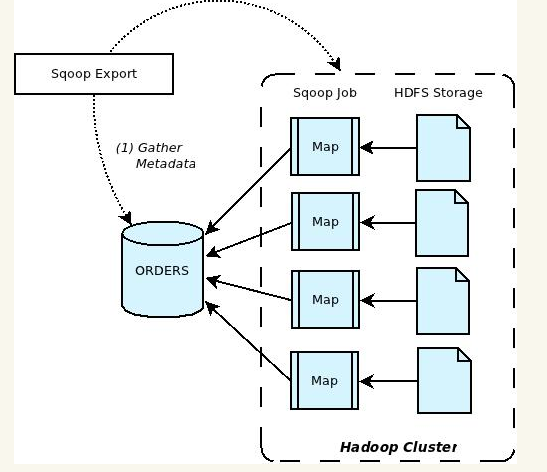
Apache Sqoop(SQL-to-Hadoop) 项目旨在协助 RDBMS 与 Hadoop 之间进行高效的大数据交流。用户可以在 Sqoop 的帮助下,轻松地把关系型数据库的数据导入到 Hadoop 与其相关的系统 (如Hbase和Hive)中;同时也可以把数据从 Hadoop 系统里抽取并导出到关系型数据库里。因此,可以说Sqoop就是一个桥梁,连接了关系型数据库与Hadoop。qoop中一大亮点就是可以通过hadoop的mapreduce把数据从关系型数据库中导入数据到HDFS。Sqoop架构非常简单,其整合了Hive、Hbase和Oozie,通过map-reduce任务来传输数据,从而提供并发特性和容错。Sqoop的基本工作流程如下图所示:
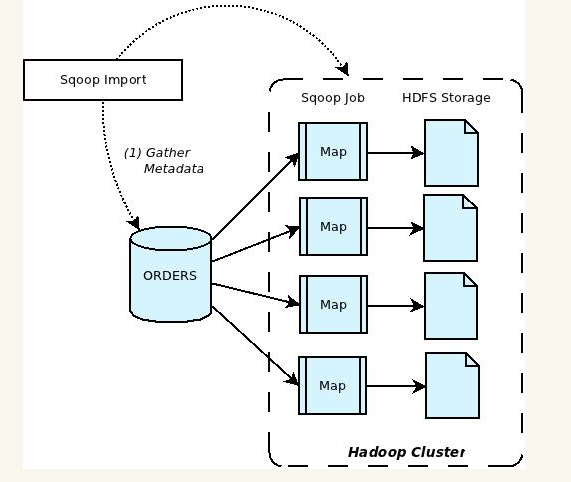
Sqoop在import时,需要制定split-by参数。Sqoop根据不同的split-by参数值来进行切分,然后将切分出来的区域分配到不同map中。每个map中再处理数据库中获取的一行一行的值,写入到HDFS中(由此也可知,导入导出的事务是以Mapper任务为单位)。同时split-by根据不同的参数类型有不同的切分方法,如比较简单的int型,Sqoop会取最大和最小split-by字段值,然后根据传入的num-mappers来确定划分几个区域。 比如select max(split_by),min(split-by) from得到的max(split-by)和min(split-by)分别为1000和1,而num-mappers为2的话,则会分成两个区域(1,500)和(501-100),同时也会分成2个sql给2个map去进行导入操作,分别为select XXX from table where split-by>=1 and split-by<500和select XXX from table where split-by>=501 and split-by<=1000。最后每个map各自获取各自SQL中的数据进行导入工作。
二、使用实例
接下来将以实例来说明如何使用
1、创建表
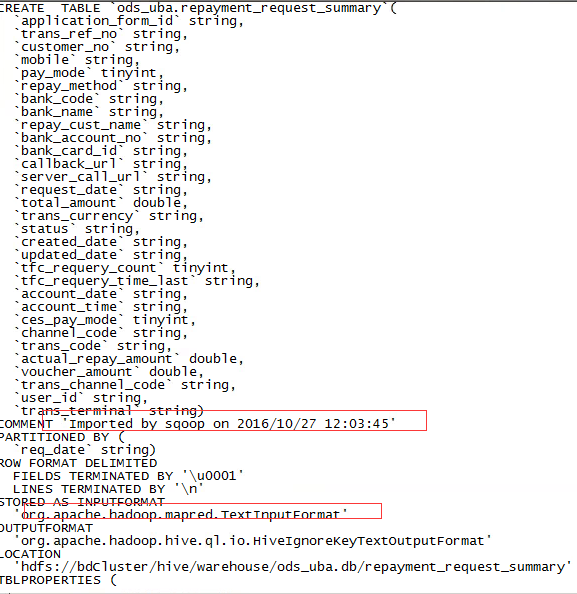
sqoop可以将MySQL表或其它关系型数据库的表结构自动映射到Hive表。映射后的表结构为textfile格式。先来看一个脚本
#!/bin/sh
. ~/.bashrc host='xx.xx.xx.xx'
database='cescore'
user='xxxx'
password='xxxx'
mysqlTable='yyyyyyy'
hiveDB='ods_uba'
hiveTable='yyyyyy' sqoop create-hive-table \
--connect jdbc:mysql://${host}:3306/${database} --username ${user} --password ${password} \
--table ${mysqlTable} \
--hive-table ${hiveDB}.${hiveTable} \
--hive-overwrite --hive-partition-key req_date \ rm *.java
--connect 指明连接的类型,基本所有的关系型数据库都可以
--table 指明要源表的表名
--hive-table 指明要创建的Hive表名
--hive-overwrite 指明是否覆盖插入(将原来的分区数据全删除,再插入)
--hive-partition-key 指明分区的字段
我们可以到Hive去查看对应的表结构:
2、从mysql导数据到Hive
sqoop可以将数据从关系型数据库导到Hive或Hive导到关系型数据库,先来看一个从mydql导数据到Hive的实例,示例脚本如下
先来看一个脚本
#!/bin/sh
. ~/.bashrc host='xx.xx.xx.xx'
database='xxxcc'
user='xxxx'
password='xxxx'
mysqlTable='sys_approve_reject_code'
hiveDB='ods_uba'
hiveTable='sys_approve_reject_code'
tmpDir='/user/hive/warehouse/ods_uba.db/'${hiveTable} sqoop import --connect jdbc:mysql://${host}:3306/${database} --username ${user} --password ${password} \
--query "select * from "${database}"."${mysqlTable}" where 1 = 1 and \$CONDITIONS" \
--hive-import --hive-table ${hiveDB}.${hiveTable} --target-dir ${tmpDir} --delete-target-dir --split-by approve_reject_code \
--hive-overwrite \
--null-string '\\N' --null-non-string '\\N'
一般情况下,如果Hive里的表不存在,也可以不用执行第一步的创建表的步骤,因为一般导数时,它如果发现hive表不存在,会自己帮你创建表,Hive表的数据结构就和mysql的一样。不过,这样要注意一个点,如果Hive表是你自己通过Hive的交互命令行建立起来的,并且存储格式设置为orc,那么使用sqoop导数据到这个表时是可以导入成功,但是会发现无法查询出来,或者查询乱码。只能设置成textfile才可以。
上面的sql是将表全量导入到Hive中,不进行分区操作,每次导数都会将原来的数据删除,因为这是一张字典表,所以需要这么做。来看看各字段的含义
--query 指明查询的sql语句,注意主里加了一个 and \$conditions ,这是必需的,如果有带where条件的话
--hive-table 指明目标表名
--target-dir 指明目标表的hdfs路径
--delete-target-dir 删除目标hfds路径数据
--split-by 指明shuffle的字段,一般是取主键
--hive-overwrite 先删除旧数据,再重新插入
--null-string --对null字符串和处理,映射成hive里的null
--null-non-string --对null非字符串和处理,映射成hive里的null
3、从phoenix导数据到Hive
下面再来看一个比较复杂的脚本,这里将从phoenix导数据,并将一天的数据分成24份
#!/bin/sh
. ~/.bashrc #导数据,注意要传入一个yyyy-mm-dd类型参数
synData(){
echo "您要统计数据的日期为:$statisDate"
#生成每小时的查询条件
for i in `seq `
do
num=$(echo $i)
doSqoop $statisDate $num
done
} #sqoop导数据
doSqoop(){
echo "输入日期:$statisDate,输入序列号:$num"
timeZone=$(printf "%02d\n" $(expr "$num" - ""))
partitionTime=$(echo "$statisDate-$timeZone")
evtNOPre=$(echo $partitionTime | sed 's/\-//g')
echo "分区字段:$partitionTime"
where_qry=$(echo "evt_no like '$evtNOPre%'")
echo $where_qry hiveDB='ods_uba'
hiveTable='evt_log'
tmpDir='/user/hive/warehouse/ods_uba.db/'${hiveTable} sqoop import -D mapreduce.map.memory.mb= --driver org.apache.phoenix.jdbc.PhoenixDriver \
--connect jdbc:phoenix:xxxxxxxx \
--query "select * from uba.evt_log where $where_qry and \$CONDITIONS" \
--hive-import --hive-table ${hiveDB}.${hiveTable} --target-dir ${tmpDir} --delete-target-dir --split-by evt_no \
--hive-overwrite --hive-partition-key partition_time --hive-partition-value ${partitionTime} \
--null-string '\\N' --null-non-string '\\N'
rm *.java } #统计日期默认取昨天
diffday=
statisDate=`date +"%Y-%m-%d" -d "-"${diffday}"day"`
#首先判断是否有输入日期,以及输入日期是否合法,如果合法,取输入的日期。不合法报错,输入日期为空,取昨天
if [ $# -eq ]; then
echo "您没有输入参数"
synData $statisDate
elif [ $# -eq ]; then
echo "您输入参数为: $1 "
statisDate=$
if [ ${#statisDate} -eq ];then
synData $statisDate
else
echo "您输入日期不合法,请输入yyyy-mm-dd类型参数"
fi
else
echo "您输入参数多于一个,请不要输入或只输入一个yyyy-mm-dd类型参数"
fi
-D mapreduce.map.memory.mb=3072,这是一个非常有用的参数,一般如果数据量非常大,在抽数据时有可能报内存不足,这时可以通过调高这个参数。
--driver 这里指明了使用的驱动类型,注意要将对应的驱动连接包放到sqoop对应的lib目录下,要不会报错
--hive-partition-key 指明分区字段
--hive-partition-value 指明分区值
这里因为是每天抽数,所以按天进行分区,因为还将每天分成了24个小时,理论上讲设置成两个分区字段会好点,但是sqoop只支持设置一个分区字段,所以这里的分区字段会被设计成yyyy-mm-dd-hh的类型
4、从mysql到hbse
sqoop import --connect jdbc:mysql://localhost/acmedb \
--table ORDERS --username test --password **** \
--hbase-create-table --hbase-table ORDERS --column-family mysql
--hbase-create-table: 指明使用sqoop创建hbse表
--hbase-table: hbase表
--column-family: --指明列族,将所有的mysql的列都放在这个列族下面
(转) Sqoop使用实例讲解的更多相关文章
- float实例讲解
float实例讲解 float是个强大的属性,在实际前端开发过程中,人们经常拿它来进行布局,但有时,使用的不好,也麻烦多多啊. 比如,现在我们要实现一个两列布局,左边的列,宽度固定:右边的列,宽度自动 ...
- S3C2440上RTC时钟驱动开发实例讲解(转载)
嵌入式Linux之我行,主要讲述和总结了本人在学习嵌入式linux中的每个步骤.一为总结经验,二希望能给想入门嵌入式Linux的朋友提供方便.如有错误之处,谢请指正. 共享资源,欢迎转载:http:/ ...
- 实例讲解Oracle数据库设置默认表空间问题
实例讲解Oracle数据库设置默认表空间问题 实例讲解Oracle数据库设置默认表空间问题,阅读实例讲解Oracle数据库设置默认表空间问题,DBA们经常会遇到一个这样令人头疼的问题:不知道谁在O ...
- 基于tcpdump实例讲解TCP/IP协议
前言 虽然网络编程的socket大家很多都会操作,但是很多还是不熟悉socket编程中,底层TCP/IP协议的交互过程,本文会一个简单的客户端程序和服务端程序的交互过程,使用tcpdump抓包,实例讲 ...
- makefile基础实例讲解 分类: C/C++ 2015-03-16 10:11 66人阅读 评论(0) 收藏
一.makefile简介 定义:makefile定义了软件开发过程中,项目工程编译链.接接的方法和规则. 产生:由IDE自动生成或者开发者手动书写. 作用:Unix(MAC OS.Solars)和Li ...
- 实例讲解Linux系统中硬链接与软链接的创建
导读 Linux链接分两种,一种被称为硬链接(Hard Link),另一种被称为符号链接(Symbolic Link).默认情况下,ln命令产生硬链接.硬链接与软链接的区别从根本上要从Inode节点说 ...
- spring事务传播机制实例讲解
http://kingj.iteye.com/blog/1680350 spring事务传播机制实例讲解 博客分类: spring java历险 天温习spring的事务处理机制,总结 ...
- 实例讲解MySQL联合查询
好了终于贴完了MySQL联合查询的内容了,加上上一篇一共2篇,都是我转载的,实例讲解MySQL联合查询.那下面就具体讲讲简单的JOIN的用法了.首先我们假设有2个表A和B,他们的表结构和字段分别为: ...
- Html代码seo优化最佳布局实例讲解
搜索引擎对html代码是非常优化的,所以html的优化是做好推广的第一步.一个符合seo规则的代码大体如下界面所示. 1.<!–木庄网络博客–> 这个东西是些页面注释的,可以在这里加我的& ...
随机推荐
- mysql数据库 BETWEEN 语法的用法和边界值解析
between用法: 用于where表达式中,选取两个值之间的数据,如: SELECT id FROM user WHERE id BETWEEN value1 AND value2; 当betwee ...
- UVA11294 Wedding
嘟嘟嘟 大佬们都说这是2-SAT入门题,然而对于刚学2_SAT的本菜鸡来说半天才理解…… 题面:新娘和新郎不能坐在同一侧,妻子和丈夫不能坐在同一侧,有**关系的两个人必须至少一个坐在新娘一侧,问方案. ...
- 使用ToDateTime方法转换日期显示格式
实现效果: 知识运用: Convert类的ToDateTime方法:(将字符串转化为DateTime对象) public static DateTime ToDateTime(string value ...
- c#类的练习
类部分练习题 - dijiaxing1234的博客 - CSDN博客 https://blog.csdn.net/dijiaxing1234/article/details/81230811 真好啊
- VK Cup 2012 Round 1 D. Distance in Tree (树形dp)
题目:http://codeforces.com/problemset/problem/161/D 题意:给你一棵树,问你两点之间的距离正好等于k的有多少个 思路:这个题目的内存限制首先大一倍,他有5 ...
- mac下配置Node.js开发环境、express安装、创建项目
mac下配置Node.js开发环境.express安装.创建项目 一.node.js的安装 去官网下载对应的平台版本就可以了,https://nodejs.org 二.express安装 sudo n ...
- 梯度下降(HGL)
线性回归:是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法. 对于一般训练集: 参数系统为: 线性模型为: 损 ...
- mybatis学习记录四——输入、输出映射
6 输入映射 通过parameterType指定输入参数的类型,类型可以是简单类型.hashmap.pojo的包装类型. 6.1.1 需求 完成用户信息的综合查询,需要传入查询条件很 ...
- Android学习笔记_16_添加多个Activity、参数传递、请求码和结果码使用
一.添加新的Activity步骤: 第一步:新建一个继承Activity的类,如:NewActivity public class NewActivity extends Activity { @Ov ...
- 【办公】Microsoft Office 2016 专业增强版下载及永久激活-亲测分享
Win7 x64,安装 Office 2016. 1. 下载 Office 2016,用迅雷网上下载飞快.(这里分享我的下载链接,2.39G用迅雷分分钟就下好了) 2. 按 此博客 ,安装激活工具. ...