LightGBM的算法介绍
LightGBM算法的特别之处
LightGBM算法在模型的训练速度和内存方面都有相应的优化。
基于树模型的boosting算法,很多算法比如(xgboost 的默认设置)都是用预排序(pre-sorting)算法进行特征的选择和分裂。
- 首先,对所有特征按数值进行预排序。
- 其次,在每次的样本分割时,用O(# data)的代价找到每个特征的最优分割点。
- 最后,找到最后的特征以及分割点,将数据分裂成左右两个子节点。
优缺点:
这种pre-sorting算法能够准确找到分裂点,但是在空间和时间上有很大的开销。
i. 由于需要对特征进行预排序并且需要保存排序后的索引值(为了后续快速的计算分裂点),因此内存需要训练数据的两倍。
ii. 在遍历每一个分割点的时候,都需要进行分裂增益的计算,消耗的代价大。
LightGBM采用Histogram算法,其思想是将连续的浮点特征离散成k个离散值,并构造宽度为k的Histogram。然后遍历训练数据,统计每个离散值在直方图中的累计统计量。在进行特征选择时,只需要根据直方图的离散值,遍历寻找最优的分割点。
Histogram 算法的优缺点:
- Histogram算法并不是完美的。由于特征被离散化后,找到的并不是很精确的分割点,所以会对结果产生影响。但在实际的数据集上表明,离散化的分裂点对最终的精度影响并不大,甚至会好一些。原因在于decision tree本身就是一个弱学习器,采用Histogram算法会起到正则化的效果,有效地防止模型的过拟合。
- 时间上的开销由原来的O(#data * #features)降到O(k * #features)。由于离散化,#bin远小于#data,因此时间上有很大的提升。
- Histogram算法还可以进一步加速。一个叶子节点的Histogram可以直接由父节点的Histogram和兄弟节点的Histogram做差得到。一般情况下,构造Histogram需要遍历该叶子上的所有数据,通过该方法,只需要遍历Histogram的k个捅。速度提升了一倍。
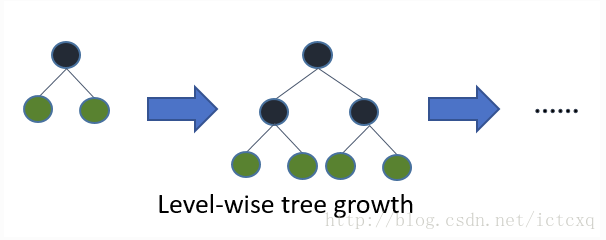
LightGBM的leaf-wise的生长策略
它摒弃了现在大部分GBDT使用的按层生长(level-wise)的决策树生长策略,使用带有深度限制的按叶子生长(leaf-wise)的策略。level-wise过一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型复杂度,不容易过拟合。但实际上level-wise是一种低效的算法,因为它不加区分的对待同一层的叶子,带来了很多没必要的开销,因为实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。
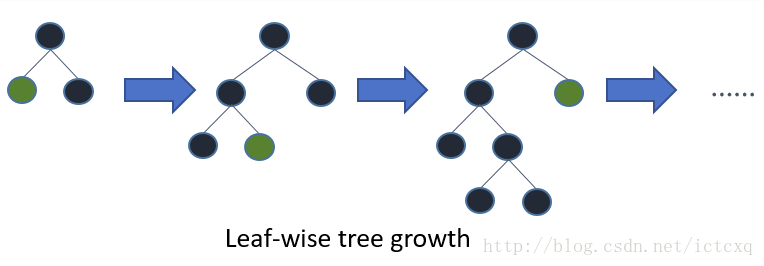
Leaf-wise则是一种更为高效的策略,每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。因此同Level-wise相比,在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度。Leaf-wise的缺点是可能会长出比较深的决策树,产生过拟合。因此LightGBM在Leaf-wise之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合。
LightGBM支持类别特征
实际上大多数机器学习工具都无法直接支持类别特征,一般需要把类别特征,转化one-hotting特征,降低了空间和时间的效率。而类别特征的使用是在实践中很常用的。基于这个考虑,LightGBM优化了对类别特征的支持,可以直接输入类别特征,不需要额外的0/1展开。并在决策树算法上增加了类别特征的决策规则。

以上是LightGBM算法的特别之处,除此之外LightGBM还具有高校并行的特点。下一篇文章将介绍LightGBM的特征并行(Feature Parallel)和数据并行(Data Parallel),以及相较于传统的并行方法的优点。
LightGBM的算法介绍的更多相关文章
- 【原创】机器学习之PageRank算法应用与C#实现(1)算法介绍
考虑到知识的复杂性,连续性,将本算法及应用分为3篇文章,请关注,将在本月逐步发表. 1.机器学习之PageRank算法应用与C#实现(1)算法介绍 2.机器学习之PageRank算法应用与C#实现(2 ...
- KNN算法介绍
KNN算法全名为k-Nearest Neighbor,就是K最近邻的意思. 算法描述 KNN是一种分类算法,其基本思想是采用测量不同特征值之间的距离方法进行分类. 算法过程如下: 1.准备样本数据集( ...
- ISP基本框架及算法介绍
什么是ISP,他的工作原理是怎样的? ISP是Image Signal Processor的缩写,全称是影像处理器.在相机成像的整个环节中,它负责接收感光元件(Sensor)的原始信号数据,可以理解为 ...
- Python之常见算法介绍
一.算法介绍 1. 算法是什么 算法是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机制.也就是说,能够对一定规范的输入,在有限时间内获得所要求的输 ...
- RETE算法介绍
RETE算法介绍一. rete概述Rete算法是一种前向规则快速匹配算法,其匹配速度与规则数目无关.Rete是拉丁文,对应英文是net,也就是网络.Rete算法通过形成一个rete网络进行模式匹配,利 ...
- H2O中的随机森林算法介绍及其项目实战(python实现)
H2O中的随机森林算法介绍及其项目实战(python实现) 包的引入:from h2o.estimators.random_forest import H2ORandomForestEstimator ...
- STL 算法介绍
STL 算法介绍 算法概述 算法部分主要由头文件<algorithm>,<numeric>和<functional>组成. <algorithm ...
- Levenshtein字符串距离算法介绍
Levenshtein字符串距离算法介绍 文/开发部 Dimmacro KMP完全匹配算法和 Levenshtein相似度匹配算法是模糊查找匹配字符串中最经典的算法,配合近期技术栏目关于算法的探讨,上 ...
- 机器学习概念之特征选择(Feature selection)之RFormula算法介绍
不多说,直接上干货! RFormula算法介绍: RFormula通过R模型公式来选择列.支持R操作中的部分操作,包括‘~’, ‘.’, ‘:’, ‘+’以及‘-‘,基本操作如下: 1. ~分隔目标和 ...
随机推荐
- WebApiConfig设置返回json并且对于get,post可以重名
webapi2默认返回的是xml格式的,并且一个控制器中的方法名不能重名,列如:一个get,一个post这个也是不允许的,这些我们都可以进行设置. 下面设置:返回json格式,并且一个控制器中的方法可 ...
- 使用classList来实现两个按钮样式的切换
classList属性的方法:add();remove();toggle(); 描述,在一些页面我们需要使用两个按钮来回切换,如图: 我们要使用到add()和remove()方法 html部分: &l ...
- Mbatis错误信息整理
***每存在一对接口和xml文件,必须在xml文件中定义好mapper标签及namespace ***每对接口必须和xml文件名必须一致 <mapper>标签中的names ...
- jquery表单属性筛选元素
$(":button") 选择所有按钮元素类型为按钮的元素. 等于$('input[type="button"]') $(":checkbox&quo ...
- [HAOI2007]上升序列(最长上升子序列)
题目描述 对于一个给定的 S=\{a_1,a_2,a_3,…,a_n\}S={a1,a2,a3,…,an} ,若有 P=\{a_{x_1},a_{x_2},a_{x_3},…,a_{x_m}\ ...
- php mysql 计算经纬之间距离 范围内筛选
<?php /** * 根据经纬度和半径计算出范围 * @param string $lat 纬度 * @param String $lng 经度 * @param float $radius ...
- 爬虫——Selenium与PhantomJS
Selenium Selenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的,类型像我们玩游戏用的按键精灵,可以按指定的命令自动操作,不同的是Selenium可以直接运行在浏览器上, ...
- web前端逻辑计算,血的教训
在web前端进行页面开发的过程中,难免的遇到逻辑问题,这不是什么大问题,既然走上IT条黑道,那小伙伴们的逻辑推理能力及逻辑计算能力是不会有太大问题的. 然而,有的逻辑计算,就算你逻辑计算能力超强,也不 ...
- jQuery最重要的知识点
1.各种常见的选择器.2.对于属性的操作.[重点] 2.1)获取或设置属性的值: prop(); 2.2 ) 添加.删除.切换样式: addClass/removeClass/toggleClass ...
- C#中在WebClient中使用post发送数据实现方法
很多时候,我们需要使用C#中的WebClient 来收发数据,WebClient 类提供向 URI 标识的任何本地.Intranet 或 Internet 资源发送数据以及从这些资源接收数据的公共方法 ...