Apache Hive 简介及安装
简介
Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件 映射为一张数据库表,并提供类 SQL 查询功能。
本质是将 SQL 转换为 MapReduce 程序。
主要用途:用来做离线数据分析,比直接用 MapReduce 开发效率更高。Hive 利用 HDFS 存储数据,利用 MapReduce 查询分析数据。
数据库和数据仓库的区别在于:
- 数据库是面向事务的设计,数据仓库是面向主题设计的。
- 数据库一般存储业务数据,数据仓库存储的一般是历史数据。
- 数据库设计是尽量避免冗余,一般针对某一业务应用进行设计,比如一张简单的 User 表,记录用户名、密码等简单数据即可,符合业务应用,但是不符合分析。数据仓库在设计是有意引入冗余,依照分析需求,分析维度、分析指标进行设计。
- 数据库是为捕获数据而设计,数据仓库是为分析数据而设计。
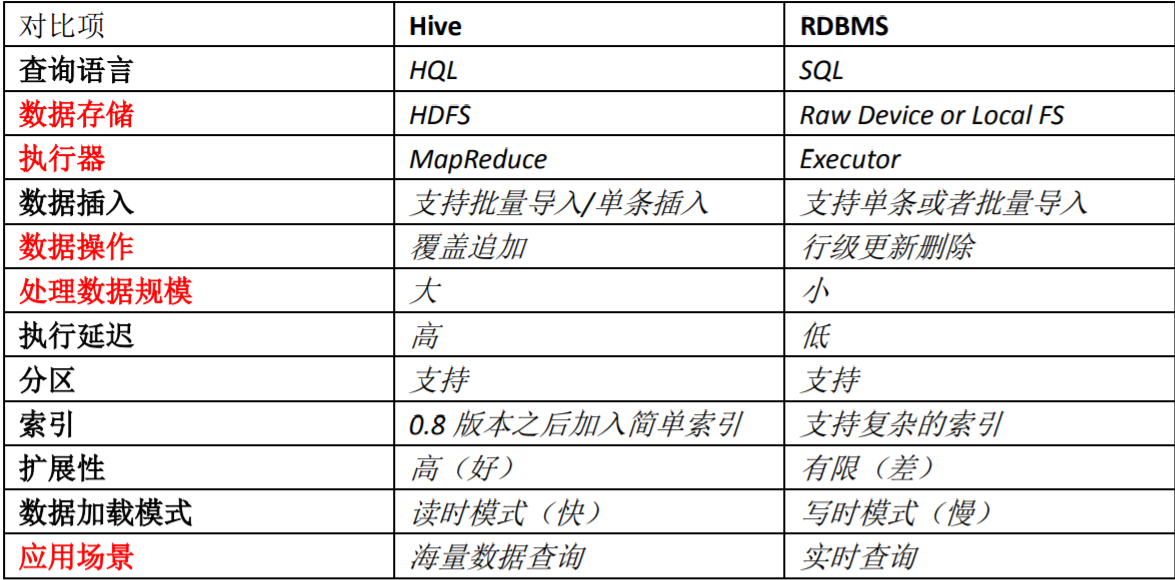
Hive优缺点
优点:
- 可扩展性,横向扩展,Hive 可以自由的扩展集群的规模,一般情况下不需要重启服务 横向扩展:通过分担压力的方式扩展集群的规模 纵向扩展:一台服务器cpu i7-6700k 4核心8线程,8核心16线程,内存64G => 128G
- 延展性,Hive 支持自定义函数,用户可以根据自己的需求来实现自己的函数
- 良好的容错性,可以保障即使有节点出现问题,SQL 语句仍可完成执行
缺点:
- Hive 不支持记录级别的增删改操作,但是用户可以通过查询生成新表或者将查询结 果导入到文件中(当前选择的 hive-2.3.2 的版本支持记录级别的插入操作)
- Hive 的查询延时很严重,因为 MapReduce Job 的启动过程消耗很长时间,所以不能 用在交互查询系统中。
- Hive 不支持事务(因为不没有增删改,所以主要用来做 OLAP(联机分析处理),而 不是 OLTP(联机事务处理),这就是数据处理的两大级别)。
Hive架构
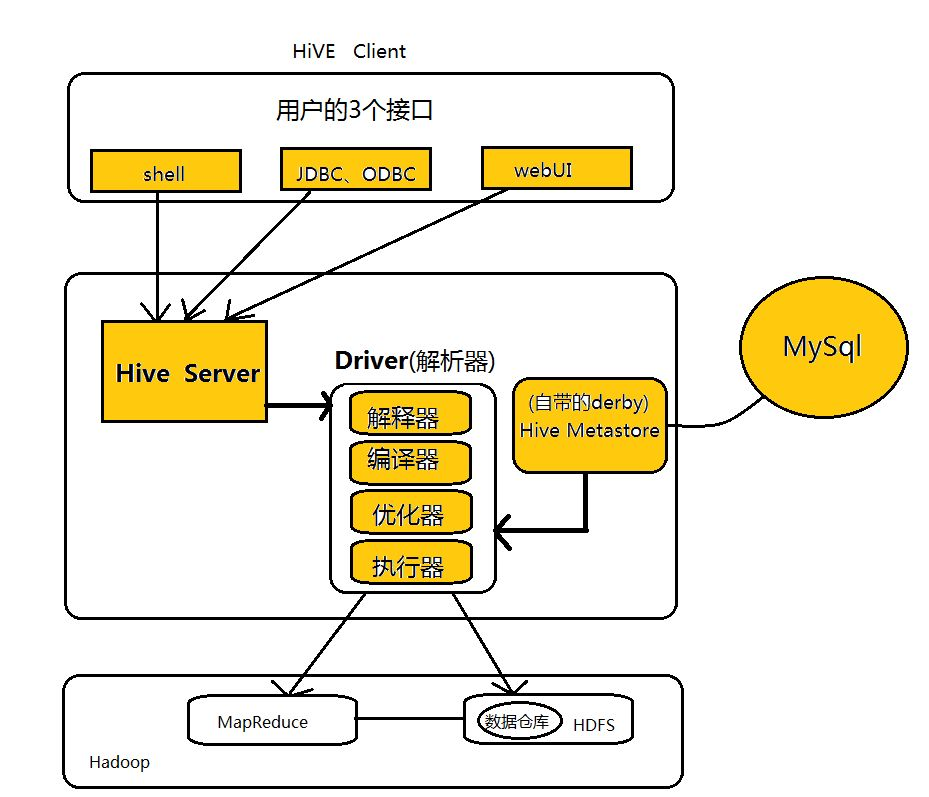
hive client我们一般用shell,hive metastore 我们一般配置成mysql。
Hive数据模型
Hive 中所有的数据都存储在 HDFS 中,没有专门的数据存储格式
在创建表时指定数据中的分隔符,Hive 就可以映射成功,解析数据。
Hive 中包含以下数据模型:
- db :在 hdfs 中表现为 hive.metastore.warehouse.dir 目录下一个文件夹
- table :在 hdfs 中表现所属 db 目录下一个文件夹
- external table :数据存放位置可以在 HDFS 任意指定路径
- partition :在 hdfs 中表现为 table 目录下的子目录
- bucket :在 hdfs 中表现为同一个表目录下根据 hash 散列之后的多个文件
- view:与传统数据库类似,只读,基于基本表创建
Hive安装部署
1,Hive 安装前需要安装好 JDK 和 Hadoop。配置好环境变量。
2,上传安装文件 apache-hive-x.x.x-bin.tar.gz,并解压。
3,配置HIVE_HOME环境变量
vi /export/servers/hive/conf/hive-env.sh 配置其中的HADOOP_HOME
export HADOOP_HOME=/export/servers/hadoop-2.7.4
4,配置元数据库信息,在conf文件夹内新添加hive-site.xml文件(分别配置mysql的位置,mysql的Driver,mysql的账号和密码)
vi hive-site.xml <configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.44.31:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property> <property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property> <property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property> <property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>password to use against metastore database</description>
</property>
</configuration>
5,把mysql-connector-java-5.1.32.jar上传到 Hive的lib文件夹中
6,启动hive,我们一般把Hive当做服务启动
启动Hive
bin/hiveserver2 启动成功后,可以在别的节点上用beeline去连接
[root@bigdata-02 bin]# ./beeline
Beeline version 1.2.1 by Apache Hive
beeline> ! connect jdbc:hive2://bigdata-01:10000
Connecting to jdbc:hive2://bigdata-01:10000
Enter username for jdbc:hive2://bigdata-01:10000: root
Enter password for jdbc:hive2://bigdata-01:10000: ******
Connected to: Apache Hive (version 1.2.1)
Driver: Hive JDBC (version 1.2.1)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Apache Hive 简介及安装的更多相关文章
- 【转】 hive简介,安装 配置常见问题和例子
原文来自: http://blog.csdn.net/zhumin726/article/details/8027802 1 HIVE概述 Hive是基于Hadoop的一个数据仓库工具,可以将结构化 ...
- Apache Kafka简介与安装(二)
Kafka在Windows环境上安装与运行 简介 Apache kafka 是一个分布式的基于push-subscribe的消息系统,它具备快速.可扩展.可持久化的特点.它现在是Apache旗下的一个 ...
- HIVE简介及安装
一.简介 百度百科HIVE定义: hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运 ...
- Apache Kafka简介与安装(一)
介绍 Kafka是一个分布式的.可分区的.可复制的消息系统.它提供了普通消息系统的功能,但具有自己独特的设计. 首先让我们看几个基本的消息系统术语: Kafka将消息以topic为单位进行归纳. 将向 ...
- Apache Flume简介及安装部署
概述 Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的软件. Flume 的核心是把数据从数据源(source)收集过来,再将收集到的数据送到指定的目 ...
- Apache Hive处理数据示例
继上一篇文章介绍如何使用Pig处理HDFS上的数据,本文将介绍使用Apache Hive进行数据查询和处理. Apache Hive简介 首先Hive是一款数据仓库软件 使用HiveQL来结构化和查询 ...
- Apache Hive 安装文档
简介: Apache hive 是基于 Hadoop 的一个开源的数据仓库工具,可以将结构化的数据文件映射为一张数据库表, 并提供简单的sql查询功能,将 SQL 语句转换为 MapReduce 任务 ...
- 数据仓库Hive(一)——hive简介,产生,安装
1.Hive简介 数据仓库 解释器.编译器.优化器等 运行时,元数据存储在关系型数据库里面 1.1数据库和数据仓库的区别 数据库需要立即返回结果,数据仓库不需要 数据仓库能收纳各种数据源,而数据库只能 ...
- Netty学习——Apache Thrift 简介和下载安装
Netty学习——Apache Thrift 简介和下载安装 Apache Thrift 简介 本来由Facebook开发,捐献给了Apache,成了Apache的一个重要项目 可伸缩的,跨语言的服务 ...
随机推荐
- HAWQ取代传统数仓实践(十一)——维度表技术之维度合并
有一种合并维度的情况,就是本来属性相同的维度,因为某种原因被设计成重复的维度属性.例如,在销售订单示例中,随着数据仓库中维度的增加,我们会发现有些通用的数据存在于多个维度中.客户维度的客户地址相关信息 ...
- Java 实现--时间片轮转 RR 进程调度算法
时间片轮转(Round-Robin)调度算法是操作系统一种比较公平的进程调度的方式,这种方式使得就绪队列上的所有进程在每次轮转时都可以运行相同的一个时间片. 基本原理 算法实现原理是,按进程到达顺序( ...
- 阿里云,腾讯云,等等的云 Ubuntu14.04升级16.04
16.04有很多好处.在此不说了 这几天来回折腾了各种的云,然后发现国内的都没有16.04 但是ubuntu可以直接在线升级 在此记下来升级的过程 不管是腾讯云也好 阿里云也好,或者别的什么云,只要是 ...
- 基于UDP协议编程
基于udp套接字 udp是无链接的,先启动哪一端都不会报错. UDP(user datagram protocol,用户数据报协议)是无连接的,面向消息的,提供高效率服务.不会使用块的合并优化算法,, ...
- Java进阶知识点5:服务端高并发的基石 - NIO与Reactor模式以及AIO与Proactor模式
一.背景 要提升服务器的并发处理能力,通常有两大方向的思路. 1.系统架构层面.比如负载均衡.多级缓存.单元化部署等等. 2.单节点优化层面.比如修复代码级别的性能Bug.JVM参数调优.IO优化等等 ...
- java 线程基础学习
今天趁空闲时间看了点线程方面的知识 首先看的是volatile关键字,按照我之前书上看到的一点知识,自己的理解是,volatile关键字会阻止编译优化,因为cpu每次读取数据是并不是从高速缓存中读取, ...
- Centos7下命令笔记-ls
ls命令大概是linux下最常用的命令之一,ls是list的缩写.因为linux目录或者文件记录的信息实在太多,所以默认ls只显示非隐藏的目录以及文件名.ls直接执行不加参数时显示本目录下的档案名. ...
- 一起来看CORE源码(一) ConcurrentDictionary
先贴源码地址 https://github.com/dotnet/corefx/blob/master/src/System.Collections.Concurrent/src/System/Col ...
- String类的一些常规方法
String类 String类常用方法: ①length(): length() 长度 方法** 对比:数组.length 属性** 一般情况下,一个数字,一个字母,一个汉 ...
- Python 中,字符串"连接"效率最高的方式是?一定出乎你的意料
网上很多文章人云亦云,字符串连接应该使用「join」方法而不要用「+」操作.说前者效率更高,它以更少的代价创建新字符串,如果用「+」连接多个字符串,每连接一次,就要为字符串分配一次内存,效率显得有点低 ...