SQL夯实基础(一):inner join、outer join和cross join的区别
一、数据构建
先建表,再说话
create database Test
use Test
create table A
(
AID int identity(1,1) primary key,
name nvarchar(50),
age int
)
create table B
(
BID int identity(1,1) primary key,
name nvarchar(50),
gender int
)
创建完之后,插入数据
insert A(name,age)values('张三',35)
insert A(name,age)values('李四',25)
insert A(name,age)values('XXX',35)
insert A(name,age)values('YYY',35)

insert B(name,gender)values('张三',1)
insert B(name,gender)values('李四',1)
insert B(name,gender)values('AAA',2)
insert B(name,gender)values('BBB',2)
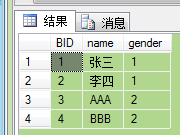
现在建完两张表,Table A,Table B其各有四条记录,其中有两条记录name是相同的:
二、对比测试
缺省情况下是inner join(也就是你直接输入join),开发中使用的left join和right join属于outer join,另外outer join还包括full join.下面我通过图标让大家认识它们的区别。
这里使用了JOIN…ON子句,用户自己指定一个可以消除笛卡尔积的关联条件。
1.INNER JOIN 产生的结果是AB的交集
SELECT * FROM A INNER JOIN B ON A.name = B.name

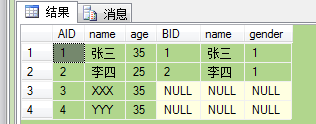
2.LEFT [OUTER] JOIN 产生表A的完全集,而B表中匹配的则有值,没有匹配的则以null值取代。
SELECT * FROM A LEFT OUTER JOIN B ON A.name = B.name
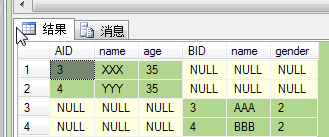
3.RIGHT [OUTER] JOIN 产生表B的完全集,而A表中匹配的则有值,没有匹配的则以null值取代。
SELECT * FROM A RIGHT OUTER JOIN B ON A.name = B.name

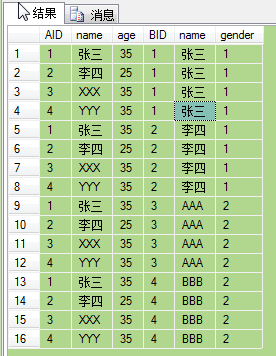
4.FULL [OUTER] JOIN 产生A和B的并集。对于没有匹配的记录,则会以null做为值。
SELECT * FROM A FULL OUTER JOIN B ON A.name = B.name

你可以通过is NULL将没有匹配的值找出来:
SELECT * FROM A FULL OUTER JOIN B ON A.name = B.name
WHERE A.id IS null OR B.id IS null
5.CROSS JOIN(交叉连接):用于产生笛卡尔积
把表A和表B的数据进行一个N*M的组合,即笛卡尔积。如本例会产生4*4=16条记录,在开发过程中我们肯定是要过滤数据,所以这种很少用。
SELECT * FROM A CROSS JOIN B
相信大家对inner join、outer join和cross join的区别一目了然了。
补充一点:按照sql标准CROSS JOIN是笛卡尔积。但对于mysql来说,CROSS JOIN 相当于 INNER JOIN。
三、Outer Join 的执行过程
总的来说,outer join 的执行过程分为4步
1、先对两个表执行交叉连接(笛卡尔积)
2、应用on筛选器
3、添加外部行
4、应用where筛选器
第一步,对两个表执行交叉连接,结果如下,这一步会产生36条记录(此图显示不全)
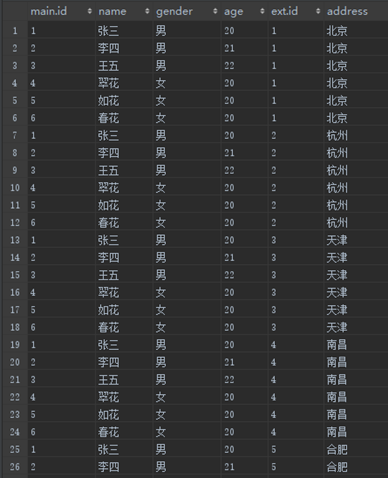
第二步,应用on筛选器。筛选器中有两个条件,main.id = ext.id and address<> '杭州',符合要求的记录如下。
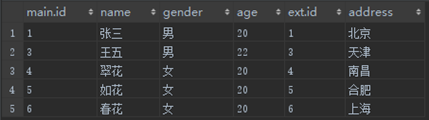
这似乎正是我们期望中查询的结果,然而在接下来的步骤中这个结果会被打乱。
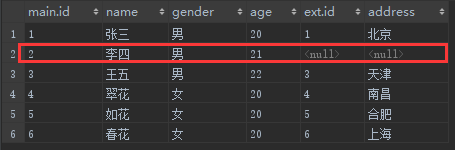
第三步,添加外部行。outer join有一个特点就是以一侧的表为基,假如另一侧的表没有符合on筛选条件的记录,则以null替代。在这次的查询中,这一步的作用就是将那条原本应该被过滤掉的记录给添加了回来

是不是不种画蛇添足的感觉, 结果就成了这样
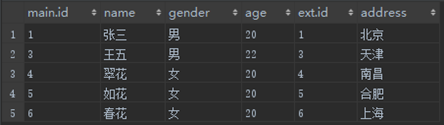
第四步,应用where筛选器
在这条问题sql中,因为没有where筛选器,所以上一步的结果就是最终的结果了。
而对于那条地址筛选在where条件中的sql,这一步便起到了作用,将所有地址不属于杭州的记录筛选了出来
通过上面的讲解,已经能反应出在outer join中的筛选条件在on中和where中的区别,开发人员如能详细了解之中差别,能规避很多在编写sql过程中出现的莫名其妙的错误。
SQL夯实基础(一):inner join、outer join和cross join的区别的更多相关文章
- SQL夯实基础(九)MySQL联接查询算法
书接上文<SQL夯实基础(八):联接运算符算法归类>. 这里先解释下EXPLAIN 结果中,第一行出现的表就是驱动表(Important!). 对驱动表可以直接排序,对非驱动表(的字段排序 ...
- SQL夯实基础(八):联接运算符算法归类
今天主要介绍三个常用联接运算符算法:合并联接(Merge join),哈希联接(Hash Join)和嵌套循环联接(Nested Loop Join).(mysql至8.0版本,都只支持Nested ...
- SQL夯实基础(六):MqSql Explain
关系型数据库中,互联网相关行业使用最多的无疑是mysql,虽然我们C# Developer很多用的都是sql server ,但是学习一些mysql方面的知识也是必要的,他山之石么. 先上一个expl ...
- SQL夯实基础(四):子查询及sql优化案例
首先我们先明确一下sql语句的执行顺序,如下有前至后执行: (1)from (2) on (3) join (4) where (5)group by (6) avg,sum... (7 ...
- SQL夯实基础(三):聚合函数详解
一.GROUP BY Having 聊聚合函数,首先肯定要弄清楚group by 和having 的用法. SELECT id, COUNT(course) as numcourse, AVG(sc ...
- SQL夯实基础(二):连接操作中使用on与where筛选的差异
一.on筛选和where筛选 在连接查询语法中,另人迷惑首当其冲的就要属on筛选和where筛选的区别了,如果在我们编写查询的时候, 筛选条件的放置不管是在on后面还是where后面, 查出来的结果总 ...
- SQL夯实基础(五):索引的数据结构
数据量达到十万级别以上的时候,索引的设置就显得异常重要,而如何才能更好的建立索引,需要了解索引的结构等基础知识.本文我们就来讨论索引的结构. 二叉搜索树:binary search tree 1.所有 ...
- 夯实基础:彻底搞清楚Cookie 和 Session 关系和区别(转)
原文地址:http://www.sohu.com/a/281228178_120047080 网络请求中的cookie与set-Cookie的交互模式和作用:https://my.oschina.ne ...
- SQL中笛卡尔积-cross join的用法
在数学中,笛卡尔乘积是指两个集合X和Y的笛卡尓积(Cartesian product),又称直积,表示为X × Y,第一个对象是X的成员而第二个对象是Y的所有可能有序对的其中一个成员 假设集合A={a ...
随机推荐
- select + range + insertNode+offset
self. cmd.range.selectNodeContents(p[0]) 建立选区 self.cmd.select() 选中选区 self.cmd.selection([forceRe ...
- Python学习进程(3)Python基本数据类型
本节介绍在Python语法中不同的变量数据类型. (1)基本数据类型: >>> a=10; >>> b=10.0; >>> c=T ...
- Django 路由、模板和模型系统
一.路由系统 URL配置(URLconf)就像Django 所支撑网站的目录.它的本质是URL模式以及要为该URL模式调用的视图函数之间的映射表:你就是以这种方式告诉Django,对于这个URL调用这 ...
- php数组函数-array_push()
array_push()函数将一个或多个元素插入数组的末尾(入栈). 提示:可以添加一个或者多个值. 注:即使您的数组有字符串键名,您所添加的元素将是数字键名. array_push(array,va ...
- 20165101刘天野 2017-2018-2 《Java程序设计》第5周学习总结
#20165101刘天野 2017-2018-2 <Java程序设计>第5周学习总结 教材学习内容总结 第七章:内部类与异常类 内部类(nested classes),面向对象程序设计中, ...
- mongoDB中批量修改字段
// 为每一个文章文档新增一个image_count字段,用于记录此文章包含的图片个数 db['test.articles'].find({'title':'wfc test'}).forEach( ...
- centos iscsi 配置
首先是服务器的设置:[root@localhost 桌面]# yum install scsi-target-* -y 安装服务 配置yum的方法太简单了,我就不写了[root@local ...
- BZOJ-1396: 识别子串
后缀自动机+线段树 先建出\(sam\),统计一遍每个点的\(right\)集合大小\(siz\),对于\(siz=1\)的点\(x\),他所代表的子串只会出现一次,设\(y=fa[x]\),则这个点 ...
- 关于Json如何转换成对象及获值问题!
var result = eval('('+result+')'); result为Json 转换成var result对象,可以 if(result.success){ window.locatio ...
- java深入探究11-基础加强
1. ? extends String:String 子类;? super String:String 父类 2.反射->参数化类型表示 ParameteredType:参数化类型表示,就是获得 ...