关于过拟合、局部最小值、以及Poor Generalization的思考
Poor Generalization
这可能是实际中遇到的最多问题。
比如FC网络为什么效果比CNN差那么多啊,是不是陷入局部最小值啊?是不是过拟合啊?是不是欠拟合啊?
在操场跑步的时候,又从SVM角度思考了一下,我认为Poor Generalization属于过拟合范畴。
与我的论文 [深度神经网络在面部情感分析系统中的应用与改良] 的观点一致。
SVM
ImageNet 2012上出现了一个经典虐杀场景。见[知乎专栏]
里面有一段这么说道:
|
当时,大多数的研究小组还都在用传统computer vision算法的时候,多伦多大学的Hinton祭出deep net这样一个大杀器。差距是这样的: 第一名Deepnet的错误率是0.16422 |
除了Hinton组是用CNN之外,第二第三都是经典的SIFT+SVM的分离模型。
按照某些民科的观点,SVM是宇宙无敌的模型,结构风险最小化,全局最小值,那么为什么要绑个SIFT?
众所周知,SIFT是CV里最优良的Hand-Made特征,为什么需要这样的特征?
因为它是一种Encoding,复杂的图像经过它的Encoding之后,有一些很明显的性质(比如各种不变性)就会暴露出来。
经过Encoding的数据,分类起来是非常容易的。这也是模式识别的经典模式:先特征提取、再分类识别。
|
Question:如果用裸SVM跑ImageNet会怎么样?
My Answer:SVM的支持向量集会十分庞大。比如有10000个数据,那么就会有10000个支持向量。
|
SVM不同于NN的一个关键点就是,它的支持向量是动态的,虽然它等效于NN的隐层神经元,但是它服从结构风险最小化。
结构风险最小化会根据数据,动态算出需求最少的神经元(或者说是隐变量[Latent Variable])。
如果SVM本身很难去切分Hard数据,那么很显然支持向量会增多,因为[Train Criterion] 会认为这是明显的欠拟合。
欠拟合情况下,增加隐变量,增大VC维,是不违背结构风险最小化的。
极限最坏情况就是,对每个点,拟合一个值,这样会导致最后的VC维无比庞大,但仍然满足结构风险最小化。图示如下:
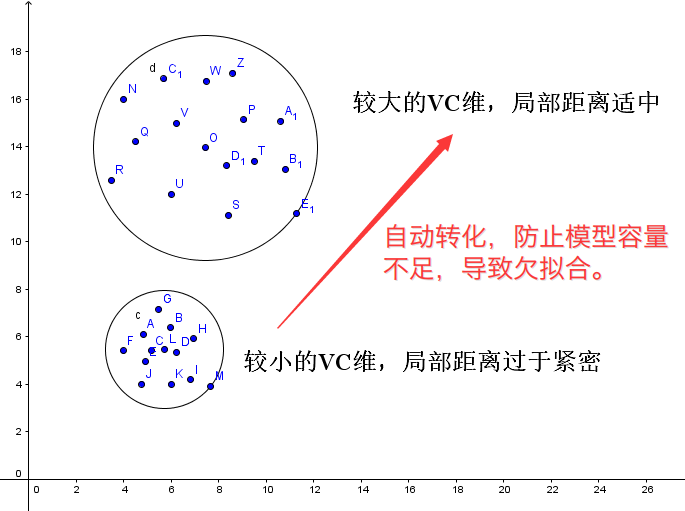
之所以要调大VC维,是因为数据太紧密。
如果吃不下一个数据,那么找局部距离的时候,就会总是产生错误的结果。
尽管已经很大了,但是仍然需要更大,最好是每个点各占一个维度,这样100%不会分错。
这会导致另外一个情况发生:过拟合,以及维数灾难:
|
维数灾难:
在Test Phase,由于参数空间十分庞大,测试数据只要与训练数据有稍微变化,很容易发生误判。
原因是训练数据在参数空间里拟合得过于离散,在做最近局部距离评估时,各个维度上,误差尺度很大。测试数据的轻微变化就能造成毁灭级误判,学习的参数毫无鲁棒性。
|
不过,由于现代SVM的[Train Criterion] 一般含有L2 Regularier,所以可以尽力压制拟合的敏感度。
如果L2系数大点,对于大量分错的点,会全部视为噪声扔掉,把过拟合压成欠拟合。
如果L2系数小点,对于大量分错的点,会当成宝去拟合,虽然不至于维数灾难,过拟合也会很严重。
当然,一般L2的系数都不会压得太狠,所以过拟合可能性应当大于欠拟合。
我曾经碰到一个例子,我的导师拿了科大讯飞语音引擎转化的数据来训练SVM。
Train Error很美,Test Error惨不忍睹,他当时和我说,SVM过拟合好严重,让我换个模型试试。
后来我换了CNN和FC,效果也差不多。
从Bayesian Learning观点来讲,Model本身拥有的Prior并不能摸清训练数据Distribution。
这时候,无论你是SVM还是CNN,都是回天无力的,必然造成Poor Generalization。
不是说,你搞个大数据就行了,你的大数据有多大,PB级?根本不够。
单纯的拟合来模拟智能,倒更像是是一个NPC问题,搜遍全部可能的样本就好了。
悲剧的是,世界上都没有一片树叶是完全相同的,美国的PB级树叶的图像数据库可能根本无法解决中国的树叶问题。
也不是说,你随便套个模型就了事了,更有甚者,连SVM、NN都不用,认为机器学习只要LR就行了。
“LR即可解决湾区数据问题”,不得不说,无论是传播这种思维、还是接受这种思维的人,都是时代的悲哀。
NN
再来看一个NN的例子,我在[深度神经网络以及Pre-Training的理解]一文的最后,用了一个神奇的表格:
[FC]
| 负似然函数 | 1.69 | 1.55 | 1.49 | 1.44 | 1.32 | 1.25 | 1.16 | 1.07 | 1.05 | 1.00 |
| 验证集错误率 | 55% | 53% | 52% | 51% | 49% | 48% |
49% |
49% | 49% | 49% |
[CNN]
| 负似然函数 | 1.87 | 1.45 | 1.25 | 1.15 | 1.05 | 0.98 | 0.94 | 0.89 | 0.7 | 0.63 |
| 验证集错误率 | 55% | 50% | 44% | 43% | 38% | 37% |
35% |
34% | 32% | 31% |
当初只是想说明:FC网络的Generalization能力真是比CNN差太多。
但现在回顾一下,其实还有有趣的地方。
I、先看FC的Epoch情况,可以看到,后期的Train Likelihood进度缓慢,甚至基本不动。
此时并不能准确判断,到底是欠拟合还是陷入到局部最小值。
但,我们有一点可以肯定,增大FC网络的规模,应该是可以让Train Likelihood变低的。
起码在这点上,应该与SVM做一个同步,就算是过拟合,也要让Train Likelihood更好看。
II、相同Train Likelihood下,CNN的Test Error要低很多。
如果将两个模型看成是等效的规模(实际上CNN的规模要比FC低很多),此时FC网络可以直接被判为过拟合的。
这点需要转换参照物的坐标系,将CNN看作是静止的,将FC网络看作是运动的,那么FC网络Test Error就呈倒退状态。
与过拟合的情况非常类似。
综合(I)(II),个人认为,从相对运动角度,Poor Generalization也可以看作是一种过拟合。
(II)本身就很糟了,如果遇到(I)的情况,那么盲目扩张网络只会变本加厉。
这是为什么SVM过拟合非常可怕的原因,[知乎:为什么svm不会过拟合?]
关于过拟合、局部最小值、以及Poor Generalization的思考的更多相关文章
- 【noip模拟】局部最小值
TimeLimit: 1000ms MemoryLimit: 256MB Description 有一个n行m列的整数矩阵,其中1到n×m之间的每个整数恰好出现一次.如果一 ...
- 【题解】CQOI2012局部最小值
上课讲的一道题,感觉也挺厉害的~正解是容斥 + 状压dp.首先我们容易发现一共可能的局部最小值数量是十分有限的,最多也只有 \(8\) 个.所以我们可以考虑状压. 建立出状态 \(f[i][j]\) ...
- [BZOJ2669][CQOI2012]局部最小值(容斥+状压DP)
发现最多有8个限制位置,可以以此为基础DP和容斥. $f_{i,j}=f_{i-1,j}\times (cnt_j-i+1)+\sum_{k\subset j} f_{i-1,k}$ $cnt_j$表 ...
- [nowCoder] 局部最小值位置
定义局部最小的概念.arr长度为1时,arr[0]是局部最小.arr的长度为N(N>1)时,如果arr[0]<arr[1],那么arr[0]是局部最小:如果arr[N-1]<arr[ ...
- 从Bayesian角度浅析Batch Normalization
前置阅读:http://blog.csdn.net/happynear/article/details/44238541——Batch Norm阅读笔记与实现 前置阅读:http://www.zhih ...
- 16 On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima 1609.04836v1
Nitish Shirish Keskar, Dheevatsa Mudigere, Jorge Nocedal, Mikhail Smelyanskiy, Ping Tak Peter Tang N ...
- PRML读书后记(一): 拟合学习
高斯分布·拟合 1.1 优美的高斯分布 中心极限定理[P79]证明均匀分布和二项分布在数据量 $N\rightarrow \infty$ 时,都会演化近似为高斯分布. 作为最晚发现的概率分布,可以假设 ...
- Scipy教程 - 优化和拟合库scipy.optimize
http://blog.csdn.net/pipisorry/article/details/51106570 最优化函数库Optimization 优化是找到最小值或等式的数值解的问题.scipy. ...
- Mathematica 中 Minimize函数无法找到全局最小值时的解决方法
一直使用Minimize来找到指定约束下的函数的最小值,最近发现在一个非线性函数中使用Minimize无法提供一个"全局"最小值(使用Mathematica只是用来验证算法的,所以 ...
随机推荐
- php htmlentities函数的问题
看到在细说php第二版教程中的函数htmlentities 例子,实际实验没有效果 $str = "一个 'quote' 是<b>bold</b>";ech ...
- pyquery的问题
在使用pyquery时发现一些问题, 1.爬取的html中如果有较多的错误时,不能很好的补全. 2.如果要获取某个class中的内容时,如果内容太多不能取完整!只能取一部分. 这个在现在的最新版本中还 ...
- PHP图像裁剪为任意大小的图像,图像不变形,不留下空白
<?php /** * 说明:函数功能是把一个图像裁剪为任意大小的图像,图像不变形 * 参数说明:输入 需要处理图片的 文件名,生成新图片的保存文件名,生成新图片的宽,生成新图片的高 */ fu ...
- ReactiveCocoa源码拆分解析(三)
(整个关于ReactiveCocoa的代码工程可以在https://github.com/qianhongqiang/QHQReactive下载) 这一章节主要讨论信号的“冷”与“热” 在RAC的世界 ...
- iphone的click导致div变黑
-webkit-tap-highlight-color这个属性只用于iOS (iPhone和iPad).当你点击一个链接或者通过Javascript定义的可点击元素的时候,它就会出现一个半透明的灰色背 ...
- 页面localStorage用作数据缓存的简易封装
最近做了一些前端控件的封装,需要用到数据本地存储,开始采用cookie,发现很容易就超过了cookie的容量限制,于是改用localStorage,但localStorage过于简单,没有任何管理和限 ...
- AC自动机
AC自动机,全称Aho-Corasick自动机.如果没记错的话好像就是前缀自动机. 其实AC自动机就是KMP上树的产物.理解了KMP,那AC自动机应该也是很好理解的. 与KMP类似,AC自动机也是扔一 ...
- AngularJS ui-router (嵌套路由)
http://www.oschina.net/translate/angularjs-ui-router-nested-routes AngularJS ui-router (嵌套路由) 英文原文:A ...
- appium 处理动态控件
环境怎么搭建,参考:http://www.cnblogs.com/tobecrazy/p/4562199.html 知乎Android客户端登陆:http://www.cnblogs.com/tobe ...
- Firefox下载自动保存
profile.setPreference("browser.download.folderList", 2); profile.setPreference("brows ...