从性能的角度谈SQL Server聚集索引键的选择
简介
在SQL Server中,数据是按页进行存放的。而为表加上聚集索引后,SQL Server对于数据的查找就是按照聚集索引的列作为关键字进行了。因此对于聚集索引的选择对性能的影响就变得十分重要了。本文从旨在从性能的角度来谈聚集索引的选择,但这仅仅是从性能方面考虑。对于有特殊业务要求的表,则需要按实际情况进行选择。
聚集索引所在的列或列的组合最好是唯一的
这个原因需要从数据的存放原理来谈。在SQL Server中,数据的存放方式并不是以行(Row)为单位,而是以页为单位。因此,在查找数据时,SQL Server查找的最小单位实际上是页。也就是说即使你只查找一行很小的数据,SQL Server也会将整个页查找出来,放到缓冲池中。
每一个页的大小是8K。每个页都会有一个对于SQL Server来说的物理地址。这个地址的写法是 文件号:页号(理解文件号需要你对文件和文件组有所了解).比如第一个文件的第50页。则页号为1:50。当表没有聚集索引时,表中的数据页是以堆(Heap)进行存放的,在页的基础上,SQL Server通过一个额外的行号来唯一确定每一行,这也就是传说中的RID。RID是文件号:页号:行号来进行表示的,假设这一行在前面所说的页中的第5行,则RID表示为1:50:5,如图1所示。
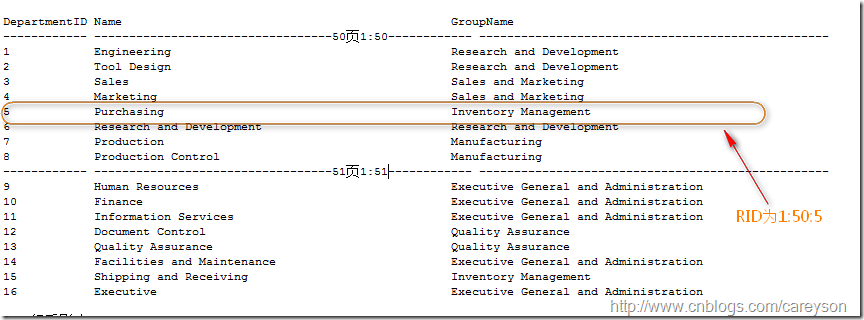
图1.RID的示例
从RID的概念来看,RID不仅仅是SQL Server唯一确定每一行的依据,也是存放行的存放位置。当页通过堆(Heap)进行组织时,页很少进行移动。
而当表上建立聚集索引时,表中的页按照B树进行组织。此时,SQL Server寻找行不再是按RID进行查找,转而使用了关键字,也就是聚集索引的列作为关键字进行查找。假设图1的表中,我们设置DepartmentID列作为聚集索引列。则B树的非叶子节点的行中只包含了DepartmentID和指向下一层节点的书签(BookMark)。
而当我们创建的聚集索引的值不唯一时,SQL Server则无法仅仅通过聚集索引列(也就是关键字)唯一确定一行。此时,为了实现对每一行的唯一区分,则需要SQL Server为相同值的聚集索引列生成一个额外的标识信息进行区分,这也就是所谓的uniquifiers。而使用了uniquifier后,对性能产生的影响分为如下两部分:
- SQL Server必须在插入或者更新时对现在数据进行判断是否和现有的键重复,如果重复,则需要生成uniquifier,这个是一笔额外开销。
- 因为需要对相同值的键添加额外的uniquifier来区分,因此键的大小被额外的增加了。因此无论是叶子节点和非叶子节点,都需要更多的页进行存储。从而还影响到了非聚集索引,使得非聚集索引的书签列变大,从而使得非聚集索引也需要更多的页进行存储。
下面我们进行测试,创建一个测试表,创建聚集索引。插入10万条测试数据,其中每2条一重复,如图2所示。
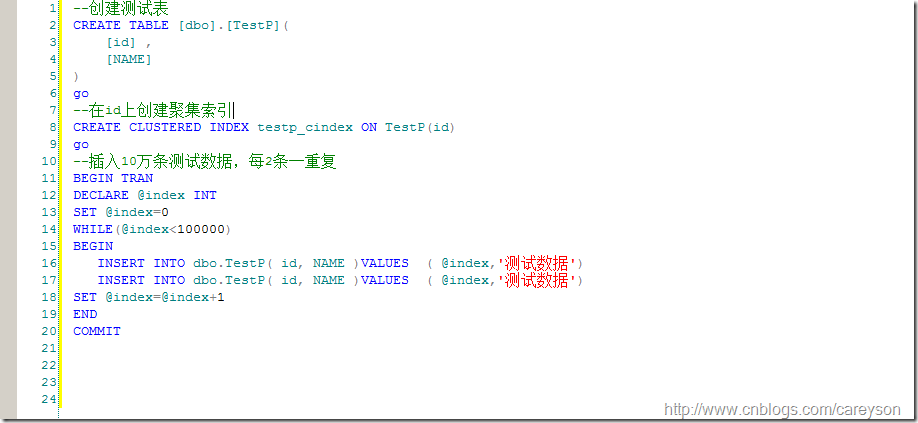
图2.插入数据的测试代码
此时,我们来查看这个表所占的页数,如图3所示。
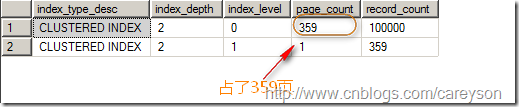
图3.插入重复键后10万数据占了359页
我们再次插入10万不重复的数据,如图4所示。

图4.插入10万不重复的建的代码
此时,所占页数缩减为335页,如图5所示。
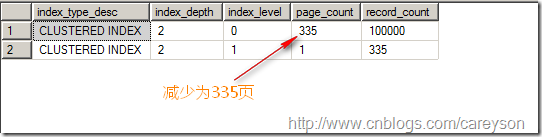
图5.插入不重复键后缩减为335页
因此,推荐聚集索引所在列使用唯一键。
最好使用窄列或窄列组合作为聚集索引列
这个道理和上面减少页的原理一样,窄列使得键的大小变小。使得聚集索引的非叶子节点减少,而非聚集索引的书签变小,从而叶子节点页变得更少。最终提高了性能。
使用值很少变动的列或列的组合作为聚集索引列
在前面我们知道。当为表创建聚集索引后。SQL Server按照键查找行。因为在B数中,数据是有序的,所以当聚集索引键发生改变时,不仅仅需要改变值本身,还需要改变这个键所在行的位置(RID),因此有可能使得行从一页移动到另一页。从而达到有序。因此会带来如下问题:
- 行从一页移动到另一页,这个操作是需要开销的,不仅如此,这个操作还可能影响到其他行,使得其他行也需要移动位置,有可能产生分页
- 行在页之间的移动会产生索引碎片
- 键的改变会影响到非聚集索引,使得非聚集索引的书签也需要改变,这又是一笔额外的开销
这也就是为什么很多表创建一列与数据本身无关的列作为主键比如AdventureWorks数据库中的Person.Address表,使用AddressID这个和数据本身无关的列作为聚集索引列,如图6所示。而使用AddressLine1作为主键的话,员工地址的变动则可能造成上面列表的问题。
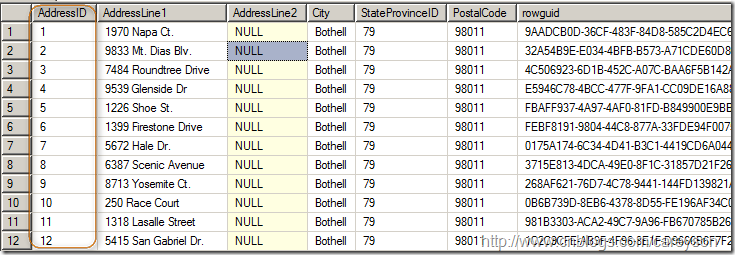
图6.创建和数据本身无关的一列作为聚集索引列
最好使用自增列作为聚集索引列
这个建议也同样推荐创建一个和数据本身无关的自增列作为聚集索引列。我们知道,如果新添加进来的数据如果聚集索引列需要插入当前有序的B树中,则需要移动其它的行来给新插入的行腾出位置。因此可能会造成分页和索引碎片。同样的,还会造成修改非聚集索引的额外负担。而使用自增列,新行的插入则会大大的减少分页和碎片。
最近我碰到过一个情况。一个表每隔几个月性能就奇慢无比,初步查看是由于有大量的索引碎片。可是每隔几个月重建一次索引让我无比厌烦。最终我发现,问题是由于当时设计数据库的人员将聚集索引建在了GUID上,而GUID是随机生成的,则可能插入到表的任何位置,从而大大增加了碎片的数量。因此造成上面这种情况。
总结
本文简单介绍了SQL Server存储的原理和应该规避的几种聚集索引建立情况,但这仅仅是从性能的角度来谈聚集索引的选择。对于聚集索引的选择,还是需要全面的考虑进行决定。
从性能的角度谈SQL Server聚集索引键的选择的更多相关文章
- 浅谈sql server聚集索引与非聚集索引
今天同事的服务程序在执行批量插入数据操作时,会超时失败,代码debug了几遍一点问题都没有,SQL单条插入也可以正常录入数据,调试了一上午还是很迷茫,场面一度很尴尬,最后还是发现了问题的根本,原来是另 ...
- Sql Server 聚集索引扫描 Scan Direction的两种方式------FORWARD 和 BACKWARD
最近发现一个分页查询存储过程中的的一个SQL语句,当聚集索引列的排序方式不同的时候,效率差别达到数十倍,让我感到非常吃惊 由此引发出来分页查询的情况下对大表做Clustered Scan的时候, 不同 ...
- SQL Server - 聚集索引 <第六篇>
聚集索引的叶子页存储的就是表的数据.因此,表行物理上按照聚集索引列排序,因为表数据只能有一种物理顺序,所以一个表只能有一个聚集索引. 当我们创建主键约束时,如果不存在聚集索引并且该索引没有被明确指定为 ...
- SQL SERVER 聚集索引 非聚集索引 区别
转自http://blog.csdn.net/single_wolf_wolf/article/details/52915862 一.理解索引的结构 索引在数据库中的作用类似于目录在书籍中的作用,用来 ...
- SQL server 聚集索引与主键的区别
主键是一个约束(constraint),他依附在一个索引上,这个索引可以是聚集索引,也可以是非聚集索引. 所以在一个(或一组)字段上有主键,只能说明他上面有个索引,但不一定就是聚集索引. 例如下面: ...
- Sql Server聚集索引创建
create CLUSTERED index IX_ZhuiZIDList_ZID on ZhuiZIDList (ZID)
- c#Winform程序调用app.config文件配置数据库连接字符串 SQL Server文章目录 浅谈SQL Server中统计对于查询的影响 有关索引的DMV SQL Server中的执行引擎入门 【译】表变量和临时表的比较 对于表列数据类型选择的一点思考 SQL Server复制入门(一)----复制简介 操作系统中的进程与线程
c#Winform程序调用app.config文件配置数据库连接字符串 你新建winform项目的时候,会有一个app.config的配置文件,写在里面的<connectionStrings n ...
- 但从谈论性能点SQL Server选择聚集索引键
简单介绍 在SQL Server中,数据是按页进行存放的.而为表加上聚集索引后,SQL Server对于数据的查找就是依照聚集索引的列作为keyword进行了. 因此对于聚集索引的选择对性能的影响就变 ...
- 再谈SQL Server中日志的的作用
简介 之前我已经写了一个关于SQL Server日志的简单系列文章.本篇文章会进一步挖掘日志背后的一些概念,原理以及作用.如果您没有看过我之前的文章,请参阅: 浅谈SQL Server ...
随机推荐
- 新提交审核app保留检查更新入口将被拒绝
3月起要求关闭所有App内的检查更新功能,苹果App Store将向用户自动提示更新,新提交审核版本如果保留检查更新入口审核时将被拒绝,请各产品团队重点关注. 10.6 - Apple and our ...
- <2013 07 31> 没有必然的理由
<2013 07 31> 没有必然的理由 没有必然的理由 人类从野蛮走向文明 也可能,从野蛮走向更野蛮 没有必然的理由 人群从疯狂走向理智 也可能,从疯狂走向更疯狂 没有必然的理由 你我从 ...
- python系列六:Python3元组tuple
'''元组与列表类似,不同之处在于元组的元素不能修改.元组使用小括号,列表使用方括号.''''''uple元素不可变有一种特殊情况,当元素是可变对象时.对象内部属性是可以修改的!tuple的不可变限制 ...
- BaseServlet 介绍
1. BaseServlet 的作用 让一个Servlet可以处理多种不同的请求,不同的请求调用Servlet的不同方法. 2. 实现原理 客户端发送请求时, 必须多给出一个参数, 用来说明要调用的方 ...
- javafx 普通弹框提示
new Alert(Alert.AlertType.NONE, "xxx不存在", new ButtonType[]{ButtonType.CLOSE}).show();
- spring security原理
spring security通过一系列过滤器实现其功能,入口过滤器如下(web.xml): <filter> <filter-name>springSecurityFilte ...
- MySQL中有关icp mrr和bka的特性
文辉考我的问题,有关这三个的特性,如果在面试过程中,个人见解可以答以下 icp MyQL数据库会在取出索引的同时,判断是否进行WHERE条件过滤,也就是把WHERE的部分过滤操作放在存储引擎层,在某些 ...
- nodejs post请求
const http = require('http'); const querystring = require('querystring'); const postData = querystri ...
- 脉冲神经网络及有监督学习算法Tempotron
接下来一段时间开启脉冲神经网络模型的探索之旅.脉冲神经网络有更强的生物学基础,尽可能地模拟生物神经元之间的连接和通信方式.其潜在能力较强,值得踏进一步探索. 构建脉冲神经网络模型,至少需要考虑三点:1 ...
- Django的Model继承abstract,proxy,managed。。。
Django 中的 model 继承和 Python 中的类继承非常相似,只不过你要选择具体的实现方式:让父 model 拥有独立的数据库:还是让父 model 只包含基本的公共信息,而这些信息只能由 ...