HDUOJ题目HTML的爬取
HDUOJ题目HTML的爬取
封装好的exe/app的GitHub地址:https://github.com/Rhythmicc/HDUHTML 按照系统选择即可。
其实没什么难度,先爬下来一个题目的html,然后正则匹配一波塞个标签上去就好了。
下图运行效果:
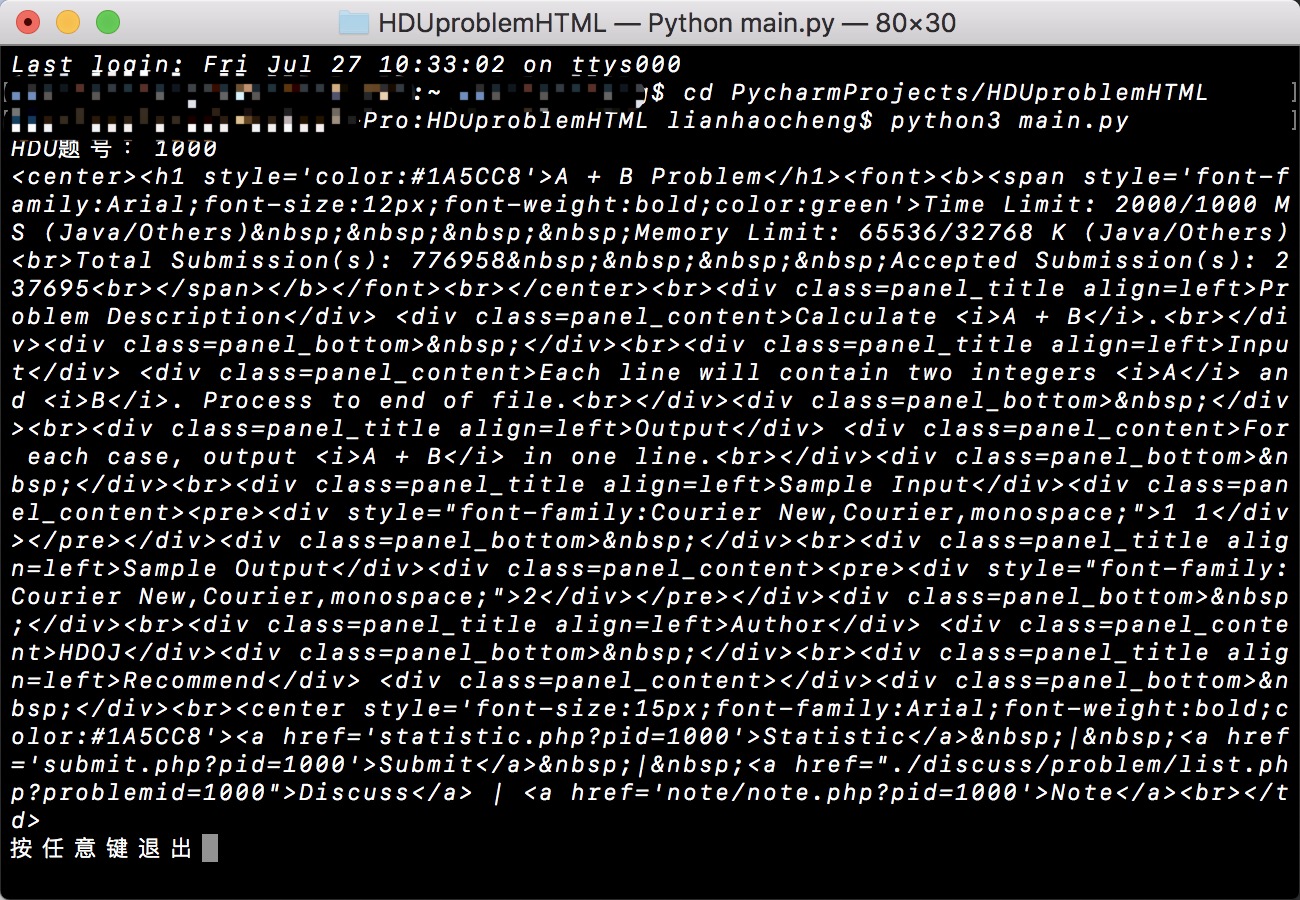
下面是爬取下的HTML运行效果:
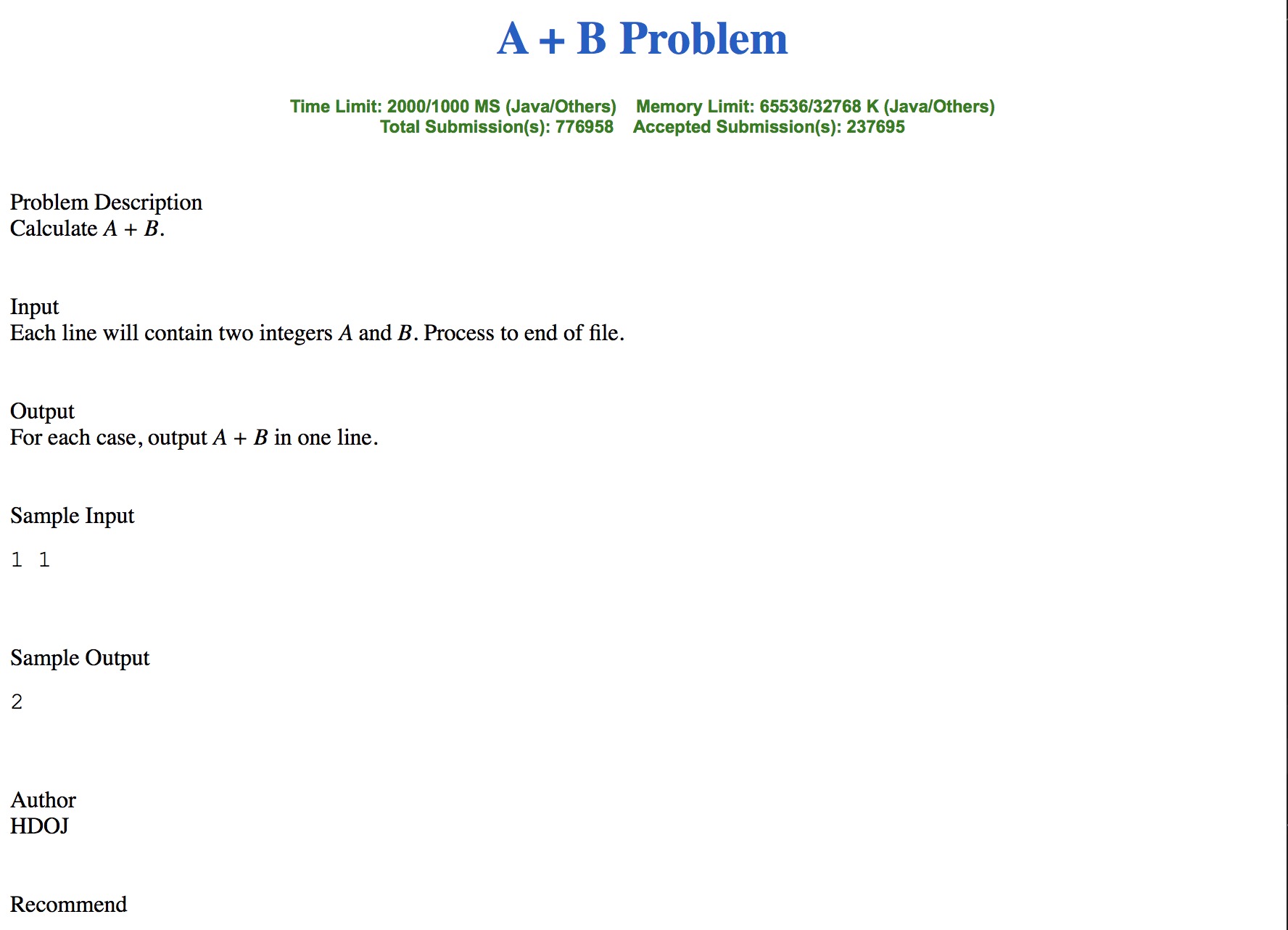
源码:
import re
import requests
from requests.exceptions import RequestException url = "http://acm.hdu.edu.cn/showproblem.php?pid=" + input("HDU题号:")
headers = {
'User-Agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/11.1.2 Safari/605.1.15"} def get_one_page(url, headers):
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
response.encoding = 'utf-8'
return response.text
return None
except RequestException:
return None html = get_one_page(url, headers=headers)
tmp=re.findall('<tr><td align=center>(.*?)</tr>',html,re.S)[0]
ans=re.findall('<h1 (.*?)<br><div class=panel_title(.*)',tmp,re.S)[0]
print('<center><h1 '+ans[0]+'</center><br><div class=panel_title'+ans[1])
ask=input('按任意键退出')
求求你们放过我的博客吧,转载要注明出处呀。。
HDUOJ题目HTML的爬取的更多相关文章
- 爬取杭电oj所有题目
杭电oj并没有反爬 所以直接爬就好了 直接贴源码(参数可改,循环次数可改,存储路径可改) import requests from bs4 import BeautifulSoup import ti ...
- [python爬虫] Selenium定向爬取海量精美图片及搜索引擎杂谈
我自认为这是自己写过博客中一篇比较优秀的文章,同时也是在深夜凌晨2点满怀着激情和愉悦之心完成的.首先通过这篇文章,你能学到以下几点: 1.可以了解Python简单爬取图片的一些思路和方法 ...
- 【图文详解】scrapy安装与真的快速上手——爬取豆瓣9分榜单
写在开头 现在scrapy的安装教程都明显过时了,随便一搜都是要你安装一大堆的依赖,什么装python(如果别人连python都没装,为什么要学scrapy….)wisted, zope interf ...
- Python爬取CSDN博客文章
0 url :http://blog.csdn.net/youyou1543724847/article/details/52818339Redis一点基础的东西目录 1.基础底层数据结构 2.win ...
- Python编写网页爬虫爬取oj上的代码信息
OJ升级,代码可能会丢失. 所以要事先备份. 一開始傻傻的复制粘贴, 后来实在不能忍, 得益于大潇的启示和聪神的原始代码, 网页爬虫走起! 已经有段时间没看Python, 这次网页爬虫的原始代码是 p ...
- 爬取软考试题系列之ip自动代理
马上5月份有个软件专业等级考试,以下简称软考,为了更好的复习备考,我打算抓取www.rkpass.com网上的软考试题. 以上为背景. 很久没有更新博客园的博客了,所以之前的代码没有及时的贴出来,咱们 ...
- 利用python的爬虫技术爬取百度贴吧的帖子
在爬取糗事百科的段子后,我又在知乎上找了一个爬取百度贴吧帖子的实例,为了巩固提升已掌握的爬虫知识,于是我打算自己也做一个. 实现目标:1,爬取楼主所发的帖子 2,显示所爬去的楼层以及帖子题目 3,将爬 ...
- 使用scrapy爬取豆瓣上面《战狼2》影评
这几天一直在学习scrapy框架,刚好学到了CrawlSpider和Rule的搭配使用,就想着要搞点事情练练手!!! 信息提取 算了,由于爬虫运行了好几次,太过分了,被封IP了,就不具体分析了,附上& ...
- Python3实现QQ机器人自动爬取百度文库的搜索结果并发送给好友(主要是爬虫)
一.效果如下: 二.运行环境: win10系统:python3:PyCharm 三.QQ机器人用的是qqbot模块 用pip安装命令是: pip install qqbot (前提需要有request ...
随机推荐
- C++的一些小操作、常用库及函数(持续更新)
1. 强制保留n位小数(位数不足则强制补零) 头文件: #include <iomanip> 在输出前: cout<<setprecision(n); 也有不用头文件的方式,在 ...
- 理解First Chance和Second Chance避免单步调试
原文链接地址:http://blog.csdn.net/Donjuan/article/details/3859160 在现在C++.Java..Net代码大行其道的时候,很多代码错误(Bug)都是通 ...
- android脱壳之DexExtractor原理分析
导语: 上一篇我们分析android脱壳使用对dvmDexFileOpenPartial下断点的原理,使用这种方法脱壳的有2个缺点: 1. 需要动态调试 2. 对抗反调试方案 为了提高工作效率, ...
- POJ 1050 To the Max 二维最大子段和
To the MaxTime Limit: 1000MS Memory Limit: 10000KTotal Submissions: 52281 Accepted: 27633Description ...
- tcp/ip网络协议学习
链路层介绍 网络层协议的数据单元是 IP 数据报 ,而数据链路层的工作就是把网络层交下来的 IP 数据报 封装为 帧(frame)发送到链路上,以及把接收到的帧中的数据取出并上交给网络层. 以太网 以 ...
- es6+最佳入门实践(9)
9.Iterator和for...of 9.1.Iterator是什么? Iterator又叫做迭代器,它是一种接口,为各种不同的数据结构提供统一的访问机制.这里说的接口可以形象的理解为USB接口,有 ...
- Java并发(6)- CountDownLatch、Semaphore与AQS
引言 上一篇文章中详细分析了基于AQS的ReentrantLock原理,ReentrantLock通过AQS中的state变量0和1之间的转换代表了独占锁.那么可以思考一下,当state变量大于1时代 ...
- spring+jersey+c3p0构建restful webservice(数据源采用c3p0)
项目下载地址: http://files.cnblogs.com/files/walk-the-Line/payment.zip
- codeforces 111D
题目链接 D. Petya and Coloring time limit per test 5 seconds memory limit per test 256 megabytes input s ...
- python并发进程
1 引言 2 创建进程 2.1 通过定义函数的方式创建进程 2.2 通过定义类的方式创建进程 3 Process中常用属性和方法 3.1 守护进程:daemon 3.2 进程终结于存活检查:termi ...