Hadoop(23)-Yarn资源调度器
Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而MapReduce等运算程序则相当于运行于操作系统之上的应用程序
1. Yarn工作机制
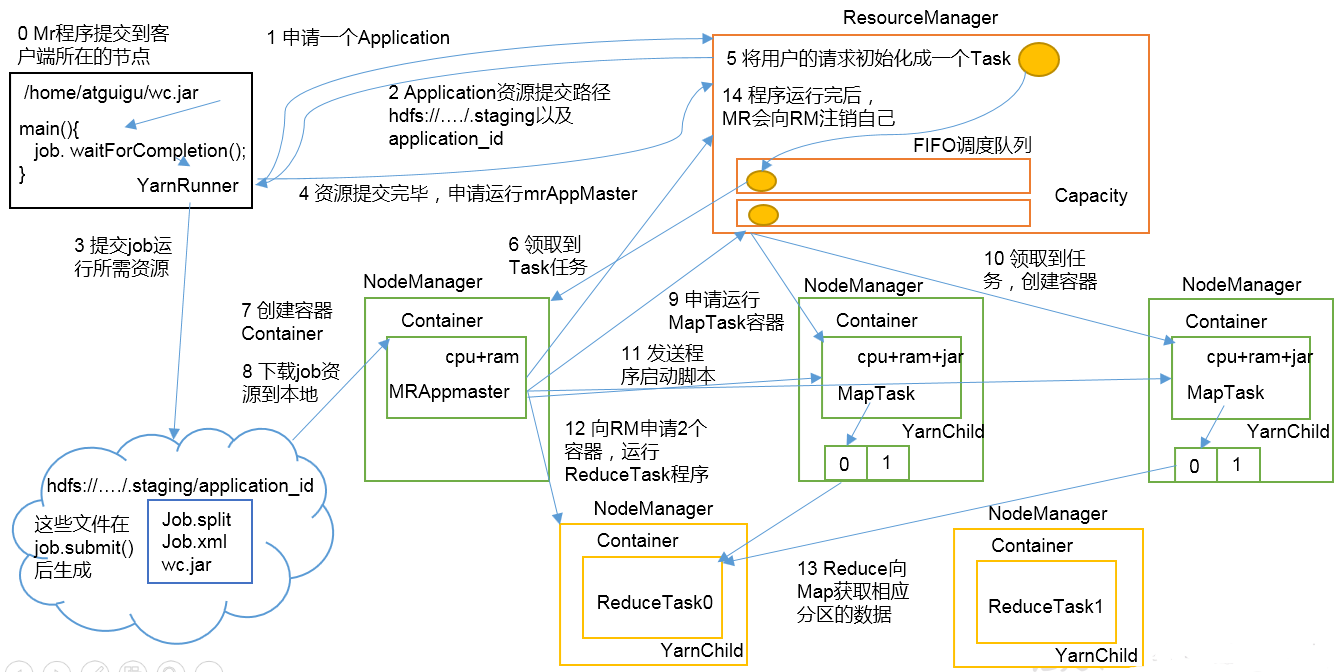
机制详解
第1步:Client调用job.waitForCompletion方法,向整个集群提交MapReduce作业。
第2步:Client向RM申请一个作业id。
第3步:RM给Client返回该job资源的提交路径和作业id。
第4步:Client提交jar包、切片信息和配置文件到指定的资源提交路径。
第5步:Client提交完资源后,向RM申请运行MrAppMaster。
第6步:当RM收到Client的请求后,将该job添加到容量调度器中。
第7步:某一个空闲的NM领取到该Job。
第8步:该NM创建Container,并产生MRAppmaster。
第9步:下载Client提交的资源到本地。
第10步:MrAppMaster向RM申请运行多个MapTask任务资源。
第11步:RM将运行MapTask任务分配给另外两个NodeManager,另两个NodeManager分别领取任务并创建容器。
第12步:MR向两个接收到任务的NodeManager发送程序启动脚本,这两个NodeManager分别启动MapTask,MapTask对数据分区排序。
第13步:MrAppMaster等待所有MapTask运行完毕后,向RM申请容器,运行ReduceTask。
第14步:ReduceTask向MapTask获取相应分区的数据。
第15步:程序运行完毕后,MR会向RM申请注销自己。
YARN中的任务将其进度和状态(包括counter)返回给应用管理器, 客户端每秒(通过mapreduce.client.progressmonitor.pollinterval设置)向应用管理器请求进度更新, 展示给用户。
除了向应用管理器请求作业进度外, 客户端每5秒都会通过调用waitForCompletion()来检查作业是否完成。时间间隔可以通过mapreduce.client.completion.pollinterval来设置。作业完成之后, 应用管理器和Container会清理工作状态。作业的信息会被作业历史服务器存储以备之后用户核查。
机制详解(通俗版)
1) 甲方爸爸整理出了需求文档
2) 询问PM是否可以排期开发
3) PM让甲方爸爸把需求文档发到邮箱里
4) 甲方爸爸发送邮件,并告知PM已发送
5) PM将需求进行排期
6) 小王刚开发完一个项目,正好有空,PM让他接手这个项目
7) 8) 小王调整一下心态,打开需求文档,预估一下,向PM申请,需要两个人手来开发
9) PM接受小王的人员申请,放入到人员排期序列中,等待两个倒霉蛋
10) 小张和小杨,两个倒霉蛋完成上一个项目,正好空闲,PM变让他俩进小王的小项目组
11) 小王把具体的模块分工告诉小张和小杨,小张小杨吭哧吭哧开始干活,然后上传代码,然后解放
12) 小王拿到中期结果看一看,认为还需要两个人进行收尾,于是向PM申请人手
13) PM将两个空闲的人员调给小王使用,进行最后的项目收尾工作,最后项目完成,向甲方爸爸汇报结果
14) 甲方爸爸很满意,这个项目就算告一段落,小王卸任.
2.资源调度器
Hadoop作业调度器主要有三种:FIFO、Capacity Scheduler和Fair Scheduler。Hadoop2.7.2默认的资源调度器是Capacity Scheduler
具体设置详见:yarn-default.xml文件
<property>
<description>The class to use as the resource scheduler.</description>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
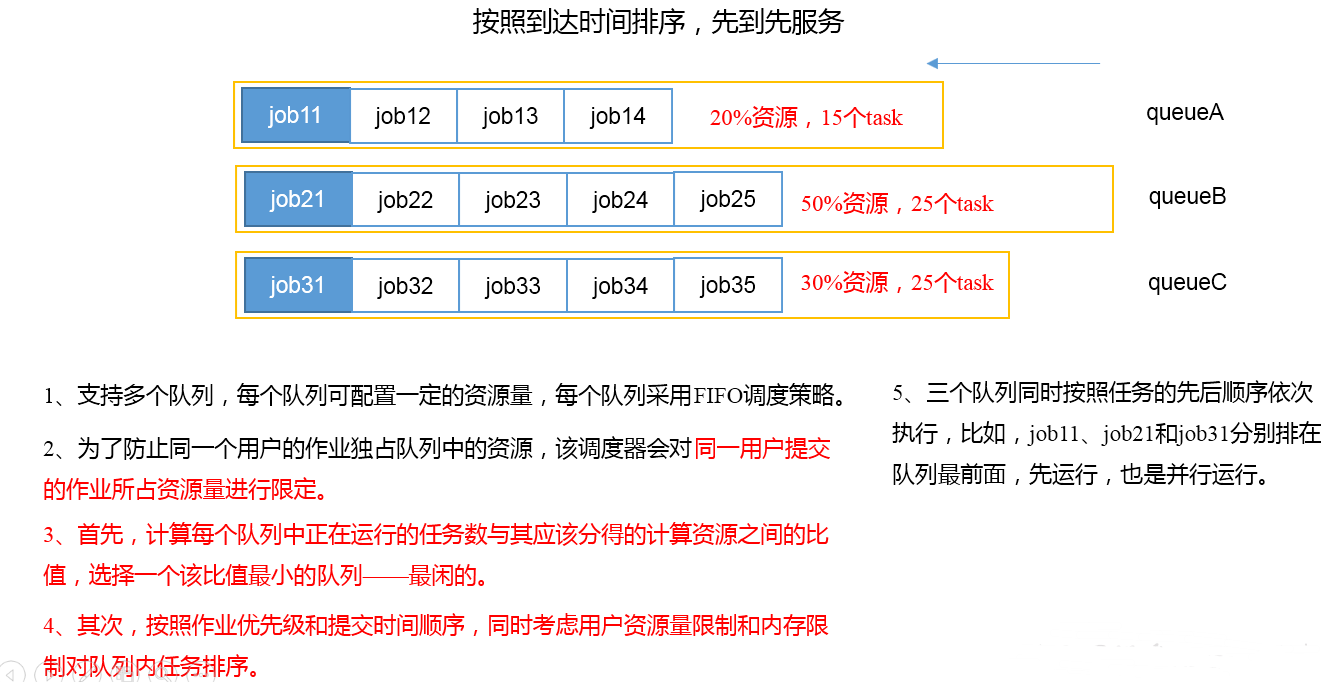
1)FIFO先进先出调度器

2) Capacity Scheduler容量调度器
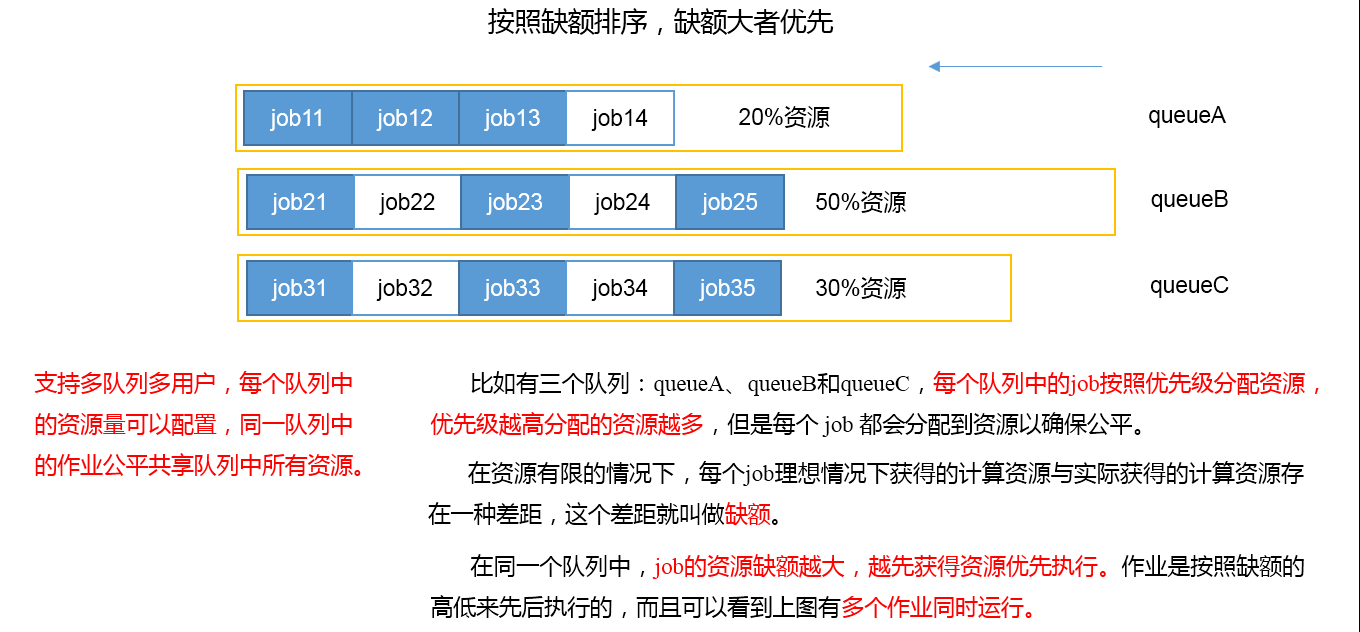
3)Fair Scheduler公平调度器
3.任务的推测执行
1) 作业完成时间取决于最慢的任务完成时间
一个作业由若干个Map任务和Reduce任务构成。因硬件老化、软件Bug等,某些任务可能运行非常慢。
思考:系统中有99%的Map任务都完成了,只有少数几个Map老是进度很慢,完不成,怎么办?
2) 推测执行机制
发现拖后腿的任务,比如某个任务运行速度远慢于任务平均速度。为拖后腿任务启动一个备份任务,同时运行。谁先运行完,则采用谁的结果。
3) 执行推测任务的前提条件
每个Task只能有一个备份任务
当前Job已完成的Task必须不小于0.05(5%)
开启推测执行参数设置。mapred-site.xml文件中默认是打开的。
<property>
<name>mapreduce.map.speculative</name>
<value>true</value>
<description>If true, then multiple instances of some map tasks may be executed in parallel.</description>
</property> <property>
<name>mapreduce.reduce.speculative</name>
<value>true</value>
<description>If true, then multiple instances of some reduce tasks may be executed in parallel.</description>
</property>
4) 不能启用推测执行机制情况
任务间存在严重的负载倾斜;
特殊任务,比如任务向数据库中写数据。
5) 推测执行算法原理

Hadoop(23)-Yarn资源调度器的更多相关文章
- YARN资源调度器
YARN资源调度器 转载请注明出处:http://www.cnblogs.com/BYRans/ 概述 集群资源是非常有限的,在多用户.多任务环境下,需要有一个协调者,来保证在有限资源或业务约束下有序 ...
- hadoop之 Yarn 调度器Scheduler详解
概述 集群资源是非常有限的,在多用户.多任务环境下,需要有一个协调者,来保证在有限资源或业务约束下有序调度任务,YARN资源调度器就是这个协调者. YARN调度器有多种实现,自带的调度器为Capaci ...
- Yarn 资源调度器
1. 概述 YARN 是一个资源调度平台,负责为运算程序提供服务器运算资源: YARN 由ResourceManager,NodeManager, ApplicationMaster 和 Contai ...
- Hadoop资源调度器
hadoop调度器的作用是将系统中空闲的资源按一定策略分配给作业.调度器是一个可插拔的模块,用户可以根据自己的实际应用要求设计调度器.Hadoop中常见的调度器有三种,分别为: 1.基于队列的FIFO ...
- hadoop,yarn和vcpu资源配置
Hadoop YARN同时支持内存和CPU两种资源的调度(默认只支持内存,如果想进一步调度CPU,需要自己进行一些配置),本文将介绍YARN是如何对这些资源进行调度和隔离的. 在YARN中,资源管理 ...
- Hadoop、Yarn和vcpu资源的配置
转载自:https://www.cnblogs.com/S-tec-songjian/p/5740691.html Hadoop YARN同时支持内存和CPU两种资源的调度(默认只支持内存,如果想进 ...
- hadoop之 YARN配置参数剖析—RM与NM相关参数
参数均需要在yarn-site.xml中配置: 1. ResourceManager相关配置参数 (1) yarn.resourcemanager.address 参数解释:ResourceManag ...
- YARN调度器(Scheduler)详解
理想情况下,我们应用对Yarn资源的请求应该立刻得到满足,但现实情况资源往往是有限的,特别是在一个很繁忙的集群,一个应用资源的请求经常需要等待一段时间才能的到相应的资源.在Yarn中,负责给应用分配资 ...
- 资源管理与调度系统-YARN的资源调度器
资源管理与调度系统-YARN的资源调度器 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 资源调度器是Hadoop YARN中最核心的组件之一,它是ResourceManager中的 ...
随机推荐
- Android 笔记之 R 文件
Android笔记之R文件 h2{ color: #4abcde; } a{ color: blue; text-decoration: none; } a:hover{ color: red; te ...
- 三大集合框架之map
Map 是一种把键对象和值对象映射的集合,它的每一个元素都包含一对键对象和值对象. Map没有继承于Collection接口 从Map集合中检索元素时,只要给出键对象,就会返回对应的值对象. Map是 ...
- solidity语言8
输入参数 pragma solidity ^0.4.16; contract Simple { function taker(uint _a, uint _b) public pure { // do ...
- mybatis中sql语句查询操作
动态sql where if where可以自动处理第一个and. <!-- 根据id查询用户信息 --> <!-- public User findUserById(int id) ...
- 对 Canal (增量数据订阅与消费)的理解
概述 canal是阿里巴巴旗下的一款开源项目,纯Java开发.基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了MySQL(也支持mariaDB). 起源:早期,阿里巴巴B2B公司 ...
- Pandas使用详细教程(个人自我总结版)
Pandas 是我最喜爱的库之一.通过带有标签的列和索引,Pandas 使我们可以以一种所有人都能理解的方式来处理数据.它可以让我们毫不费力地从诸如 csv 类型的文件中导入数据.我们可以用它快速地对 ...
- 【BZOJ3495】PA2010 Riddle
题目大意 有\(n\)个城镇被分成了\(k\)个郡,有\(m\)条连接城镇的无向边.要求给每个郡选择一个城镇作为首都,满足每条边至少有一个端点是首都. 题目分析 每条边至少有一个端点是首都,每个郡至多 ...
- Netbackup用于技术支持的问题报告(报障模版)
在与支持部门联系以报告问题之前,请填写以下信息. 日期: _________________________记录以下产品.平台和设备信息:■ 产品及其版本级别.■ 服务器硬件类型和操作系统级别.■ 客 ...
- mybatis学习记录二——mybatis开发dao的方法
4.1 SqlSession使用范围 4.1.1 SqlSessionFactoryBuilder 通过SqlSessionFactoryBuilder创建会话工厂SqlSession ...
- Javascript中==和===的区别
一.JavaScript"=="的作用 1.当==两边的内容是字符串时,则比较字符串的内容是否相等. 2.当==两边的内容是数字时,则比较数字的大小是否相等. 3.当==两边的内 ...