Question 20171114 String的一些问题?
欢迎各位大神提问题及补充不足和警醒错误!
Question 20171113 Java中char为什么占用两个字节?
Java是使用Unicode编码的所以Java会将源代码以Unicode的方式编码成字节码文件,而Unicode编码规定任意一个字符占用的都是两字节,这也是为什么Java中char类型占用两字节的原因了.
Question 20171113 String的长度有限制吗?方法,类名,字段名称有限制吗?
我们在学习Java的时候很多时候会接触到容器的概念,那么String呢?其实我们可以将String也看作一个容器,既然是容器那么有限制吗?
我们知道String的底层是char[]那么我们实际上只要知道数组的长度限制即可,我们知道数组的长度为arr.length,返回值是int值,那么数组长度原则上最大值就是int的最大值了,但实际上的最大值,是要取决于JVM的内存的,下面我们就通过代码来实验一下:
/**
* 字符串的长度
*/
@Test
public void fun1(){
//当我们申请数组长度超出int最大值会出现异常,数组下标超出
// char[] ch1 = new char[Integer.MAX_VALUE+1];
// System.out.println(ch1.length);
//提示
// char[] ch2 = new char[Integer.MAX_VALUE];
// System.out.println(ch2.length);
char[] ch3 = new char[268435456];
System.out.println(ch3.length);
}
第一个会报索引溢出异常

第二个会爆出内存溢出异常
java.lang.OutOfMemoryError: Requested array size exceeds VM limit
方法,类名,字段名称限制问题
了解Class文件的同志大概会知道,Class文件中方法和字段等都需要引用CONSTANT_Utf8_info型常量来描述名称,所以CONSTANT_Utf8_info型常量的最大长度也就是Java中方法,字段名称的最大长度,而这里的最大长度就是length的最大值,即u2类型所能表达的最大值65535。所以Java程序中如果定义了超过64KB英文字符的变量或方法名,将会无法编译。
Question 20171113 字符串常量池和String.intern方法?
引言
什么都先不说,先看下面这个引入的例子:
- String str1 = new String("SEU")+ new String("Calvin");
- System.out.println(str1.intern() == str1);
- System.out.println(str1 == "SEUCalvin");
- true
- true
再将上面的例子加上一行代码:
String str2 = "SEUCalvin";//新加的一行代码,其余不变
String str1 = new String("SEU")+ new String("Calvin");
System.out.println(str1.intern() == str1);
System.out.println(str1 == "SEUCalvin");
- false
- false
是不是感觉莫名其妙,新定义的str2好像和str1没有半毛钱的关系,怎么会影响到有关str1的输出结果呢?其实这都是intern()方法搞的鬼!看完这篇文章,你就会明白。o(∩_∩)o
在JVM运行时数据区中的方法区有一个常量池,但是发现在JDK1.6以后常量池被放置在了堆空间,因此常量池位置的不同影响到了String的intern()方法的表现。
1.为什么要介绍intern()方法
intern()方法设计的初衷,就是重用String对象,以节省内存消耗。这么说可能有点抽象,那么就用例子来证明。
static final int MAX = 100000;
static final String[] arr = new String[MAX]; public static void main(String[] args) throws Exception {
//为长度为10的Integer数组随机赋值
Integer[] sample = new Integer[10];
Random random = new Random(1000);
for (int i = 0; i < sample.length; i++) {
sample[i] = random.nextInt();
}
//记录程序开始时间
long t = System.currentTimeMillis();
//使用/不使用intern方法为10万个String赋值,值来自于Integer数组的10个数
for (int i = 0; i < MAX; i++) {
arr[i] = new String(String.valueOf(sample[i % sample.length]));
//arr[i] = new String(String.valueOf(sample[i % sample.length])).intern();
}
System.out.println((System.currentTimeMillis() - t) + "ms");
System.gc();
}
这个例子也比较简单,就是为了证明使用intern()比不使用intern()消耗的内存更少。
- 先定义一个长度为10的Integer数组,并随机为其赋值,在通过for循环为长度为10万的String对象依次赋值,这些值都来自于Integer数组。两种情况分别运行,可通过Window ---> Preferences --> Java --> Installed JREs设置JVM启动参数为-agentlib:hprof=heap=dump,format=b,将程序运行完后的hprof置于工程目录下。再通过MAT插件查看该hprof文件。
两次实验结果如下:
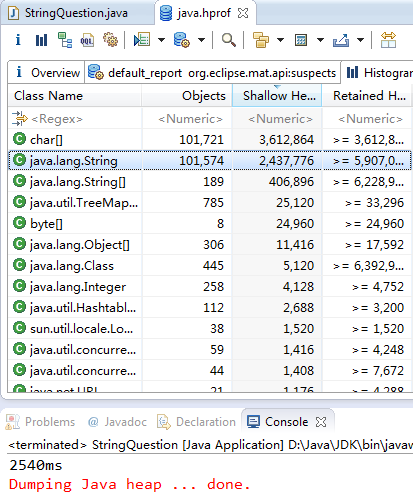
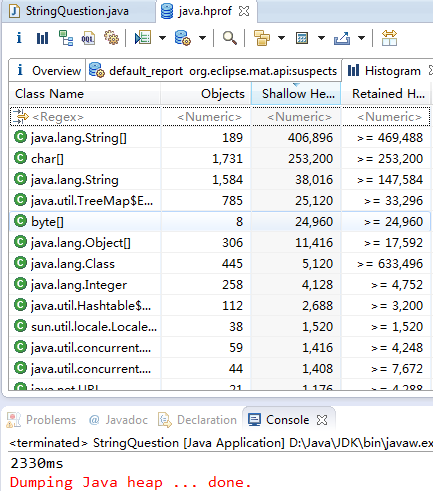
从运行结果来看,不使用intern()的情况下,程序生成了101574个String对象,而使用了intern()方法时,程序仅生成了1584个String对象。自然也证明了intern()节省内存的结论。
细心的同学会发现使用了intern()方法后程序运行时间有所增加。这是因为程序中每次都是用了new String后又进行intern()操作的耗时时间,但是不使用intern()占用内存空间导致GC的时间是要远远大于这点时间的。
2. 深入认识intern()方法
JDK1.7后,常量池被放入到堆空间中,这导致intern()函数的功能不同,具体怎么个不同法,且看看下面代码,这个例子是网上流传较广的一个例子,分析图也是直接粘贴过来的,这里我会用自己的理解去解释这个例子:
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);
- JDK1.6以及以下:false false
- JDK1.7以及以上:false true
再分别调整上面代码2.3行、7.8行的顺序:
- String s = new String("1");
- String s2 = "1";
- s.intern();
- System.out.println(s == s2);
- String s3 = new String("1") + new String("1");
- String s4 = "11";
- s3.intern();
- System.out.println(s3 == s4);
输出结果为:
- JDK1.6以及以下:false false
- JDK1.7以及以上:false false
下面依据上面代码对intern()方法进行分析:
2.1 JDK1.6
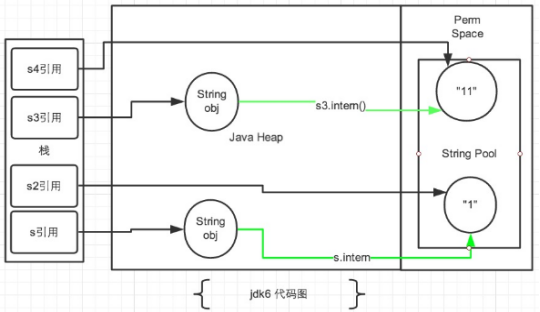
在JDK1.6中所有的输出结果都是 false,因为JDK1.6以及以前版本中,常量池是放在 Perm 区(属于方法区)中的,熟悉JVM的话应该知道这是和堆区完全分开的。
使用引号声明的字符串都是会直接在字符串常量池中生成的,而 new 出来的 String 对象是放在堆空间中的。所以两者的内存地址肯定是不相同的,即使调用了intern()方法也是不影响的。
intern()方法在JDK1.6中的作用是:比如String s = new String("SEU_Calvin"),再调用s.intern(),此时返回值还是字符串"SEU_Calvin",表面上看起来好像这个方法没什么用处。但实际上,在JDK1.6中它做了个小动作:检查字符串池里是否存在"SEU_Calvin"这么一个字符串,如果存在,就返回池里的字符串;如果不存在,该方法会把"SEU_Calvin"添加到字符串池中,然后再返回它的引用。然而在JDK1.7中却不是这样的,后面会讨论。
2.2 JDK1.7
针对JDK1.7以及以上的版本,我们将上面两段代码分开讨论。先看第一段代码的情况:
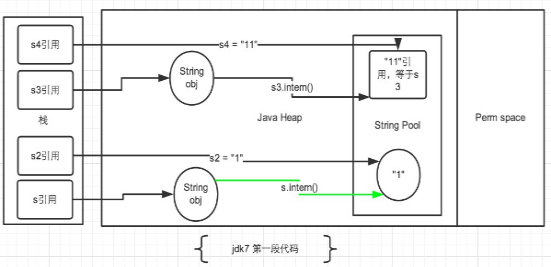
再把第一段代码贴一下便于查看:
- String s = new String("1");
- s.intern();
- String s2 = "1";
- System.out.println(s == s2);
- String s3 = new String("1") + new String("1");
- s3.intern();
- String s4 = "11";
- System.out.println(s3 == s4);
String s = newString("1"),生成了常量池中的“1” 和堆空间中的字符串对象。
s.intern(),这一行的作用是s对象去常量池中寻找后发现"1"已经存在于常量池中了。
String s2 = "1",这行代码是生成一个s2的引用指向常量池中的“1”对象。
结果就是 s 和 s2 的引用地址明显不同。因此返回了false。
String s3 = new String("1") + newString("1"),这行代码在字符串常量池中生成“1” ,并在堆空间中生成s3引用指向的对象(内容为"11")。注意此时常量池中是没有 “11”对象的。
s3.intern(),这一行代码,是将 s3中的“11”字符串放入 String 常量池中,此时常量池中不存在“11”字符串,JDK1.6的做法是直接在常量池中生成一个 "11" 的对象。
但是在JDK1.7中,常量池中不需要再存储一份对象了,可以直接存储堆中的引用。这份引用直接指向 s3 引用的对象,也就是说s3.intern() ==s3会返回true。
String s4 = "11", 这一行代码会直接去常量池中创建,但是发现已经有这个对象了,此时也就是指向 s3 引用对象的一个引用。因此s3 == s4返回了true。
下面继续分析第二段代码:
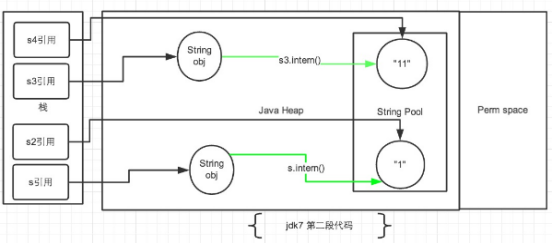
再把第二段代码贴一下便于查看:
String s = new String("1");
String s2 = "1";
s.intern();
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
String s4 = "11";
s3.intern();
System.out.println(s3 == s4);
String s = newString("1"),生成了常量池中的“1” 和堆空间中的字符串对象。
String s2 = "1",这行代码是生成一个s2的引用指向常量池中的“1”对象,但是发现已经存在了,那么就直接指向了它。
s.intern(),这一行在这里就没什么实际作用了。因为"1"已经存在了。
结果就是 s 和 s2 的引用地址明显不同。因此返回了false。
String s3 = new String("1") + newString("1"),这行代码在字符串常量池中生成“1” ,并在堆空间中生成s3引用指向的对象(内容为"11")。注意此时常量池中是没有 “11”对象的。
String s4 = "11", 这一行代码会直接去生成常量池中的"11"。
s3.intern(),这一行在这里就没什么实际作用了。因为"11"已经存在了。
结果就是 s3 和 s4 的引用地址明显不同。因此返回了false。
为了确保文章的实时更新,实时修改可能出错的地方,请确保这篇是原文,而不是无脑转载来的“原创文”,原文链接为:SEU_Calvin的博客。
3 总结
终于要做Ending了。现在再来看一下开篇给的引入例子,是不是就很清晰了呢。
- String str1 = new String("SEU") + new String("Calvin");
- System.out.println(str1.intern() == str1);
- System.out.println(str1 == "SEUCalvin");
str1.intern() == str1就是上面例子中的情况,str1.intern()发现常量池中不存在“SEUCalvin”,因此指向了str1。 "SEUCalvin"在常量池中创建时,也就直接指向了str1了。两个都返回true就理所当然啦。
那么第二段代码呢:
- String str2 = "SEUCalvin";//新加的一行代码,其余不变
- String str1 = new String("SEU")+ new String("Calvin");
- System.out.println(str1.intern() == str1);
- System.out.println(str1 == "SEUCalvin");
也很简单啦,str2先在常量池中创建了“SEUCalvin”,那么str1.intern()当然就直接指向了str2,你可以去验证它们两个是返回的true。后面的"SEUCalvin"也一样指向str2。所以谁都不搭理在堆空间中的str1了,所以都返回了false。
小结:string.Intern()会先检查在字符串常量池中有没有这个字符串,如果没有,那么在字符串常量池中村存入一个指针指向堆中的String对象,如果字符串常量池中有这个字符串,那么会返回字符串常量池中这个对象地址.
String str1 = new String("SEU") + new String("Calvin");
语句在内存中是什么样的呢?因为String是不可改变的,所以Str1相当于创建了5个对象,两个new,两个在字符串常量池,一个是str1的指向,这个指向的内容并不是SEUCalvin,
而是一个计算new String("SEU") + new String("Calvin")的计算,也就是会有这两个new对象的地址,还有运算法则,所以System.out.println(str1.intern() == str1); 为true,如果是下面情况:
String str1 = new String("SEUCalvin");
System.out.println(str1.intern() == str1);
那么结果就是false,因为第一句会在字符串常量池中创建SEUCalvin字符串对象,str1.intern()后地址就变成了字符串常量池中的地址,两个地址这时变不一样了.
Question 20171114 String的一些问题?的更多相关文章
- Question 20171115 String&&StringBuffer&&StringBuilder的区别与联系?
Question 20171114 String&&StringBuffer&&StringBuilder的区别和联系 创建成功的String对象,其长度是固定的,内容 ...
- 05_整理String类的Length()、charAt()、 getChars()、replace()、 toUpperCase()、 toLowerCase()、trim()、toCharArray()使用说明
Question: 整理String类的Length().charAt(). getChars().replace(). toUpperCase(). toLowerCase().trim().toC ...
- 为什么Java中的密码优先使用 char[] 而不是String?
可以看下壁虎的回答:https://www.zhihu.com/question/36734157 String是常量(即创建之后就无法更改),会保存到常量池中,如果有其他进程可以dump这个进程的内 ...
- STL 中 string 的使用
赋值 string 类型变量可以直接赋值 str = "string"; // str 是 一个 string 类型变量 //等价于 str.assign("string ...
- string的 insert
// inserting into a string #include <iostream> #include <string> int main () { std::stri ...
- 字符串(二):string
字符串使用方法整理 系列: 字符串(一):char 数组 字符串(二):string string 是 C++ STL 的一个字符串类型,原型是 vector<char> 并对字符串处理做 ...
- C++ string类型小结
目录 构造函数 string.append() string.assign() string.at() string.back() string.begin() string.capasity() s ...
- 443. String Compression - LeetCode
Question 443. String Compression Solution 题目大意:把一个有序数组压缩, 思路:遍历数组 Java实现: public int compress(char[] ...
- 【Java EE 学习 74 下】【数据采集系统第六天】【使用Jfreechart的统计图实现】【将JFreechart整合到项目中】
之前说了JFreechart的基本使用方法,包括生成饼图.柱状统计图和折线统计图的方法.现在需要将其整合到数据采集系统中根据调查结果生成三种不同的统计图. 一.统计模型的分析和设计 实现统计图显示的流 ...
随机推荐
- C/C++中的auto关键词
C语言 auto被解释为一个自动存储变量的关键字,也就是申明一块临时的变量内存. 例如: auto double a=3.7; 表示a为一个自动存储的临时变量. C++语言 C++ 98标准/C++0 ...
- -ms-zoom property
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- HDU 5215 Cycle(dfs判环)
题意 题目链接 \(T\)组数据,给出\(n\)个点\(m\)条边的无向图,问是否存在一个奇环/偶环 Sol 奇环比较好判断吧,直接判是否是二分图就行了.. 偶环看起来很显然就是如果dfs到一个和他颜 ...
- SCI收录的期刊查询
SCI 收录的期刊查询(动态) 1.Science Citation Index (SCI)收录期刊查询地址:http://www.isinet.com/cgi-bin/jrnlst/jlopti ...
- 关于 “VMware Workstation 不可恢复错误- (vcpu-0)”
重装系统后第一次在 VMware Workstation 上创建虚拟机,结果出现了 VMware Workstation 不可恢复错误: (vcpu-0) 错误. 于是我们遵循它给出的提示,查看一下日 ...
- qt 创建线程
http://www.cnblogs.com/xinxue/p/6840315.html Qt 之 QtConcurrent 本文以 Qt 中的 QtConcurrent::run() 函数为例,介绍 ...
- Siebel界面的搭建
Siebel界面的初步搭建都是基于Siebel Tools工具来创建的,其搭建步骤: 1. 首先先创建一个Project项目,点击project--->点 new Record--->输入 ...
- mybatis开发dao的方式
mybatis基于传统dao的开发方式 第一步:开发接口 public interface UserDao { public User getUserById(int id) throws Excep ...
- Flask入门模板Jinja2语法与函数(四)
1 模板的创建 模板文件结构: project/ templates/ 模板文件 跳转模板一般使用: from flask import render_template,render_template ...
- 初涉京东及淘宝开放平台API-商品模型
============ 京东 ============ [Product]http://help.jd.com/jos/question-568.html#A2ware_id(相当于SPU?)sku ...