Hadoop Hive概念学习系列之什么是Hive?
参考 《Hadoop大数据分析与挖掘实战》的在线电子书阅读
http://yuedu.baidu.com/ebook/d128cf8e33687e21ae45a935?pn=1&click_type=10010002
Hive最初是应Facebook每天产生的海量新兴社会网络数据进行管理和机器学习的需求而产生和发展的,是建立在Hadoop上的数据仓库基础构架。作为Hadoop的一个数据仓库工具,Hive可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能。
Hive作为构建在Hadoop之上的数据仓库,它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。Hive定义了简单的类SQL查询语言,成为HQL,它允许熟悉SQL的用户查询数据。因此,该语言也允许熟悉MapReduce的开发者开发自定义的Mapper和Reducer来处理内建的Mapper和Reducer无法完成的复杂的分析工作。
Hive没有专门的数据格式。Hive可以很好地工作在Thrift(是个服务器)之上,控制分隔符,也允许用户指定数据格式。
Hive具有以下特点:
.支持索引,加快数据查询。
.不同的存储类型,如纯文本文件、HBase中的文件。
.将元数据保存在关系数据库中,大大减少了在查询过程中执行语义检查的时间。
如, 2 hive的使用 + hive的常用语法 里的.hive的常用语法
.可以直接使用存储在Hadoop文件系统中的数据。
如, 2 hive的使用 + hive的常用语法 里的.hive的常用语法
.内置大量用户函数UDF来操作时间、字符串和其他的数据挖掘工具,支持用户扩展UDF函数来完成内置函数无法实现的操作。
如, 3 hql语法及自定义函数 里的 .hive自定义函数
.类SQL的查询方式,将SQL查询转换为MapReducer的Job在Hadoop集群上执行。
Hive构建在基于静态批处理的Hadoop之上,Hadoop通常都有较高的延迟并且在作业提交和调度时需要大量的开销。因此,Hive并不能够在大规模数据集上实现低延迟快速的查询。例如,Hive在几百MB的数据集上执行查询一般有分钟级的时间延迟。因此,Hive并不适合那些需要低延迟的应用,如联机事务处理(OLTP)。Hive查询操作过程严格遵守Hadoop MapReduce的作业执行模型,Hive将用户的HiveQL语句通过解释器转换为MapReduce作业提交到Hadoop集群上,Hadoo监控作业执行过程,然后返回作业执行结果给用户。Hive并非为联机事务处理而设计,Hive并不提供实时的查询和基于行级的数据更新操作。
Hive的最佳使用场合是大数据集的批处理作业,如网络日志分析。
Hive的架构

图1 Hive的架构
从图1中可以看到,Hive包含用户访问接口(CLI、JDBC/ODBC、GUI和Thrift Server)、元数据存储(Metastore)、驱动组件(包括编译、优化、执行驱动)。
用户访问接口即用户用来访问Hive数据仓库所使用的工具接口。
CLI(command line interface)即命令行接口。
Thrift Server是Facebook开发的一个软件框架,它用来开发可扩展且跨语言的服务,Hive集成了该服务,能让不同的编程语言调用Hive的接口。
Hive客户端提供了通过网页的方式访问Hive提供的服务,这个接口对应Hive的HWI组件(Hive web interface),使用前要启动HWI服务。
Metastore是Hive中的元数据存储,主要存储Hive中的元数据,包括表的名称、表的列和分区及其属性、表的属性(是否为外部表等)、表的数据所在目录等,一般使用MySQL或Derby数据库。
Metastore和Hive Driver驱动的互联有两种方式,一种是集成模式,如图2所示;一种是远程模式,如图3所示。
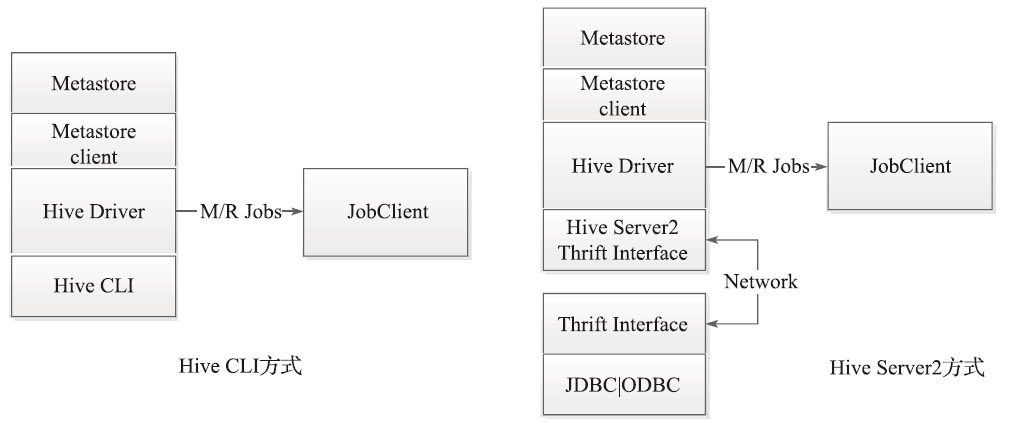
图2 Metastore 和 Driver通信(集成模式)

图3 Metastore 和 Driver通信(远程模式)
Hadoop Hive概念学习系列之什么是Hive?的更多相关文章
- Hadoop Hive概念学习系列之什么是Hive?(一)
参考 <Hadoop大数据分析与挖掘实战>的在线电子书阅读 http://yuedu.baidu.com/ebook/d128cf8e33687e21 ...
- Hadoop Hive概念学习系列之HDFS、Hive、MySQL、Sqoop之间的数据导入导出(强烈建议去看)
Hive总结(七)Hive四种数据导入方式 (强烈建议去看) Hive几种数据导出方式 https://www.iteblog.com/archives/955 (强烈建议去看) 把MySQL里的数据 ...
- Hadoop Hive概念学习系列之hive里的JDBC编程入门(二十二)
Hive与JDBC示例 在使用 JDBC 开发 Hive 程序时, 必须首先开启 Hive 的远程服务接口.在hive安装目录下的bin,使用下面命令进行开启: hive -service hives ...
- Hadoop Hive概念学习系列之hive三种方式区别和搭建、HiveServer2环境搭建、HWI环境搭建和beeline环境搭建(五)
说在前面的话 以下三种情况,最好是在3台集群里做,比如,master.slave1.slave2的master和slave1都安装了hive,将master作为服务端,将slave1作为服务端. 以 ...
- Hadoop Hive概念学习系列之hive里的索引(十三)
Hive支持索引,但是Hive的索引与关系型数据库中的索引并不相同,比如,Hive不支持主键或者外键. Hive索引可以建立在表中的某些列上,以提升一些操作的效率,例如减少MapReduce任务中需要 ...
- Hadoop Hive概念学习系列之hive的索引及案例(八)
hive里的索引是什么? 索引是标准的数据库技术,hive 0.7版本之后支持索引.Hive提供有限的索引功能,这不像传统的关系型数据库那样有“键(key)”的概念,用户可以在某些列上创建索引来加速某 ...
- Hadoop Hive概念学习系列之hive的数据压缩(七)
Hive文件存储格式包括以下几类: 1.TEXTFILE 2.SEQUENCEFILE 3.RCFILE 4.ORCFILE 其中TEXTFILE为默认格式,建表时不指定默认为这个格式,导入数据时会直 ...
- Hadoop Hive概念学习系列之hive里的扩展接口(CLI、Beeline、JDBC)(十六)
<Spark最佳实战 陈欢>写的这本书,关于此知识点,非常好,在94页. hive里的扩展接口,主要包括CLI(控制命令行接口).Beeline和JDBC等方式访问Hive. CLI和B ...
- Hadoop Hive概念学习系列之hive里的优化和高级功能(十四)
在一些特定的业务场景下,使用hive默认的配置对数据进行分析,虽然默认的配置能够实现业务需求,但是分析效率可能会很低. Hive有针对性地对不同的查询进行了优化.在Hive里可以通过修改配置的方式进行 ...
随机推荐
- mac下怎样删除冗余的环境变量?echo $PATH
记下$PATH变量中冗余路径所处顺序,例如: /Users/zhang/.rvm/gems/ruby-2.1.2/bin:/Users/zhang/.rvm/gems/ruby-2.1.2@globa ...
- 不要向没权力&能力的人证明自己的能力
[不要向没权力&能力的人证明自己的能力] 不是所有的上级都有足够的权力和能力.一个没权力的Leader,即使你向他证明了自己的能力,你所能获得的也只能是他的邮件表扬的荣誉.对于加薪,他能给的仅 ...
- Linux 各文件系统配置
区分目录跟文件 可执行文件:可以拿出来直接运行的命令. 符号链接 重要的目录 bin 里面是命令. etc 重要的配置文件.各种软件的配置文件.以后要配置网络环境,linux运行环境都是在这里进行配置 ...
- cocos2d-x 在vs2010下的搭建(win7系统)
1从官网下载cocos2d-x2.1.3的源码地址如下: http://cocos2d-x.org/ 2.解压下载的软件包我们会发现红框中vs2010的项目文件双击打开它 3.打开后我们要生成一些wi ...
- 基于 EntityFramework 的数据库主从读写分离架构(2)- 改进配置和添加事务支持
回到目录,完整代码请查看(https://github.com/cjw0511/NDF.Infrastructure)中的目录: src\ NDF.Data.EntityFramew ...
- 8.python 系统批量运维管理器之pexpect模块
小插曲 前几节讲了paramiko模块,但是pexpect模块的功能几乎跟paramiko一样,先来分析一下: 1.各自介绍 pexpect是一个通过启动子程序,使用正则表达式对程序输出做出特定响应, ...
- MySQL事务隔离级别测试实例
https://www.cnblogs.com/huanongying/p/7021555.html MySQL事务隔离级别 事务隔离级别 脏读 不可重复读 幻读 读未提交(read-uncommit ...
- Model View Controller (MVC) Overview
By Rakesh Chavda on Jul 01, 2015 What is MVC?Model View Controller is a type of user interface archi ...
- tomcat启动startup.bat一闪而过
编辑startup.bat,在文本最后添加PAUSE,保存后打开startup.bat,此时窗口会暂停,并出现错误信息,然后按照错误提示纠正即可!
- ubuntu 下python安装及hello world
//@desn:ubuntu 下python安装及hello world //@desn:码字不宜,转载请注明出处 //@author:张慧源 <turing_zhy@163.com> ...