Java线程内存模型-JVM-底层原理

public class Demo1 {
private static boolean initFlag=false;
public static void main(String[] args) throws InterruptedException {
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("waiting data......");
while (!initFlag)
{
}
System.out.println("====================");
}
}).start();
Thread.sleep(2000);
new Thread(new Runnable() {
@Override
public void run() {
prepareData();
}
}).start();
}
public static void prepareData()
{
System.out.println("prepare data.....");
initFlag=true;
System.out.println("prepare data end....");
}
}
运行结果如下:线程1未结束,但打印的数据可能与你想的不一样,我们一般会这样想:当线程1由于while(! initFlag)而陷入死循环,则线程1就一直停在那里,然后线程2在运行时将initFlag的值改为true,那么while(! initFlag)不应该不满足条件而跳出吗,然后不应该把system.out.prinltln("=============")打印出来吗
其实这样想是不对的,当理解了底层原理之后你就明白了
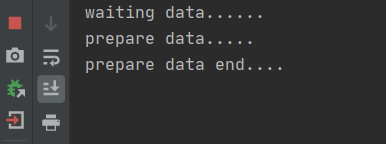
分析如下:
一、首先先了解几个JVM数据原子操作
*read(读取):从主内存中读取数据
*load(载入):将内存读取到的数据写入工作内存
*use(使用):从工作内存读取数据来计算
*assign(赋值):将计算好的值重新赋值给工作内存中的变量
*store(存储):将工作内存数据写入到主内存
*write(写入):将store过去的变量值赋值给主内存中的变量
*lock(锁定):将主内存变量加锁,标识为线程独占状态
*unlock(解锁):将主内存变量解锁,解锁后其他线程可以锁定该变量
二、
底层原理:
Java线程线程内存模型和cpu缓存模型类似;
1、代码储存在主内存,然后运行程序,线程启动,之后JVM通过read将initFlag变量读取出来,再通过load将initFlag=false加载到工作内存中的共享变量副本中
2、cpu 调用数据来计算,由于线程1运行的是while(!initFlag),则陷入循环,线程1就一直停在那个地方
3、接着看线程2,由于从主内存到工作内存一致,就不再多说,然后cpu会调用数据来计算,由于线程2的计算是将initFlag变为true,则cpu会调用assign将计算好的initFlag=true重新赋值给工作内存中的变量
4.线程2由于工作内存数据改变,则将通过store将数据写入到主内存中,但此时主内存中的变量值还未改变,还要通过write将store过去的变量值赋值给主内存中的变量,此时程序基本结束
三、但是这样的话线程1就不会结束,就不会实现并发,那么该怎么操作呢。
这时我们要在代码中添加volatile关键字,也就是代码开头类的属性private static volatile boolean initFlag=false;当加入了volatile关键字之后,结果如下
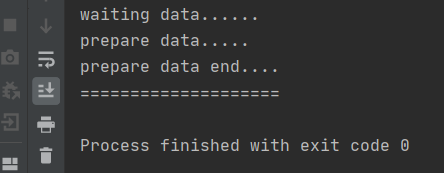
这说明了线程1结束了,也就是线程1中的initFlag的值变为了true,这是什么原因呢?
其实源于总线(MESI缓存一致性协议),当线程2工作内存中的共享变量变为true时,由于volatile的存在,原子操作中的lock会迅速将该变量通过store和write写入到主内存,此时主内存中的initFlag的值已经变为true,然后我们要来理解一下MESI缓存一致性协议:就是cpu使用总线嗅探机制对使用store经过总线的数据进行监视(总线就是Java线程内存模型中绿色包括的,总线相当于你打开台式计算机的后盖,然后会发现一排一排的线,然后它连接着cpu、主内存等,当然cpu上的主板也存在),线程2:lock锁将initFlag=true使用store写入主内存时,这时使用了store并经过总线,此时线程1,通过cpu总线嗅探机制以及发现initFlag发生改变,则会使线程1中的工作内存中的变量失效,当失效之后,就会重新从主内存中读取数据,之后cpu再use工作内存中的initFlag=true数据,再则cpu计算while(!initFlag)时就会跳出循环,然后线程1就会结束,此时system.out.println("============")就会打印出来。
至此,volatile的功能就显而易见了:调用lock锁迅速将改变的数据写入到主内存中,其间使用了store,则会启动MESI缓存一致性协议(使用cpu嗅探机制对使用store通过总线的数据进行监视)
四、然后你是否会有这样的疑问:如果我不使用volatile关键字,那线程2的工作内存中的数据改变之后依旧会使用store和write写入到主内存中呀,依旧经过了总线,那么volatile还有什么用,lock锁还有什么用呢,直接去掉不就好了吗?当然我们来看一下原因:
原因1:如果不使用volatile中的lock,那么在你线程2工作内存中的数据改变时,它不一定会迅速将改变的数据写入到主内存中,如果这个线程2还有其他复杂的步骤,那么肯定会有很大影响。
原因2:如果没有lock,那么当你将改变线程2中工作内存中的数据时,使用store通过了总线,此时cpu嗅探机制发现数据改变了,然后就会令线程1中工作内存中的数据失效,然后重新从主内存中读取,就在此时问题来了,你线程2没有迅速将改变的数据写入到主内存中,我们知道主内存中的数据改变要经过store和write,如果线程1在你线程2将数据赋值给主内存之前就已经重新读取了数据,那么此时读取的还是initFlag=false,那么线程2依旧还是没有停下来,这只是两个线程,如果是很多线程,那么就可能会引发并发问题。或者是两个线程都改变数据,那么如果不加使用lock前缀指令,那同时写入主内存就会引发并发问题
五:注意
以前的计算机是利用lock锁将线程上锁,必须等待这个线程结束后,然后其他线程才能继续运行,然后你会发现这将并发变成了一串串,这样的效率肯定很低
而以上我所说的lock锁的迅速是为了方便理解,它是将数据从store->write->主内存上锁,所以上锁的只是给主内存赋值过程,由于主内存变量的赋值超每秒可达上百万次,所以这个时间可以忽略不记
Java线程内存模型-JVM-底层原理的更多相关文章
- java线程内存模型,线程、工作内存、主内存
转自:http://rainyear.iteye.com/blog/1734311 java线程内存模型 线程.工作内存.主内存三者之间的交互关系图: key edeas 所有线程共享主内存 每个线程 ...
- Java I/O模型及其底层原理
Java I/O是Java基础之一,在面试中也比较常见,在这里我们尝试通过这篇文章阐述Java I/O的基础概念,帮助大家更好的理解Java I/O. 在刚开始学习Java I/O时,我很迷惑,因为网 ...
- 【Java并发】1. Java线程内存模型JMM及volatile相关知识
Java招聘知识合集:https://www.cnblogs.com/spzmmd/tag/Java招聘知识合集/ 该系列用于汇集Java招聘需要的知识点 JMM 并发编程的三大特性:可见性(vola ...
- 【转】Java 内存模型及GC原理
一个优秀Java程序员,必须了解Java内存模型.GC工作原理,以及如何优化GC的性能.与GC进行有限的交互,有一些应用程序对性能要求较高,例如嵌入式系统.实时系统等,只有全面提升内存的管理效率,才能 ...
- Java虚拟机--内存模型与线程
Java虚拟机--内存模型与线程 高速缓存:处理器要与内存交互,如读取.存储运算结果,而计算机的存储设备和处理器的运算速度差异巨大,所以加入一层读写速度和处理器接近的高速缓存来作为内存和处理器之间的缓 ...
- Java 内存模型及GC原理 (转载)
一个优秀Java程序员,必须了解Java内存模型.GC工作原理,以及如何优化GC的性能.与GC进行有限的交互,有一些应用程序对性能要求较高,例如嵌入式系统.实时系统等,只有全面提升内存的管理效率,才能 ...
- Java 内存模型、GC原理及算法
Java 内存模型.GC原理:https://blog.csdn.net/ithomer/article/details/6252552 GC算法:https://www.cnblogs.com/sm ...
- JVM底层原理及调优之笔记一
JVM底层原理及调优 1.java虚拟机内存模型(JVM内存模型) 1.堆(-Xms -Xmx -Xmn) java堆,也称为GC堆,是JVM中所管理的内存中最大的一块内存区域,是线程共享的,在JVM ...
- 全网最硬核 Java 新内存模型解析与实验单篇版(不断更新QA中)
个人创作公约:本人声明创作的所有文章皆为自己原创,如果有参考任何文章的地方,会标注出来,如果有疏漏,欢迎大家批判.如果大家发现网上有抄袭本文章的,欢迎举报,并且积极向这个 github 仓库 提交 i ...
随机推荐
- JavaScript的事件循环机制浅析
前言 JavaScript是一门单线程的弱类型语言,但是我们在开发中,经常会遇到一些需要异步或者等待的处理操作. 类似ajax,亦或者ES6中新增的promise操作用于处理一些回调函数等. 概念 在 ...
- MySQL报错 SQL ERROR:1064 ,SQLState:42000
使用mysql新增数据时报错,具体信息如图所示: 错误原因: 所建的表中 表名或字段名与数据库关键字冲突 解决办法 可以根据报错信息,查看错误的具体位置,找到数据库中对应的字段,查询是否与关键字(不分 ...
- Mybatis工具类(自动提交事务)
public class MybatisUtils { private static SqlSessionFactory sqlSessionFactory; static { try { //获取工 ...
- WOE(weight of evidence, 证据权重)
1. WOE(weight of evidence, 证据权重) WOE是一种衡量正常样本( Good)和违约样本( Bad)分布的差异方法 WOE=ln(Distr Good/Distr Bad)例 ...
- [bzoj3809]Gty的二逼妹子序列/[bzoj3236][Ahoi2013]作业
[bzoj3809]Gty的二逼妹子序列/[bzoj3236][Ahoi2013]作业 bzoj bzoj 题目大意:一个序列,m个询问在$[l,r]$区间的$[x,y]$范围内的数的个数/种类. ...
- SpringCloudAlibaba 微服务讲解(四)Sentinel--服务容错(一)
4.1 高并发带来的问题 在微服务中,我们将业务拆分成一个个的服务,服务与服务之间可以相互调用,但是由于网络原因或者自身的原因,服务并不能保证100%可用,如果单个服务出现问题,调用这个服务就会出现网 ...
- 半吊子菜鸟学Web开发 -- PHP学习 1-基础语法
1索引数组 $fruit = array("苹果","香蕉","菠萝"): print_r($fruit); 索引数组的初始化,有三种方式: ...
- springcloud断路器作用?
当一个服务调用另一个服务由于网络原因或自身原因出现问题,调用者就会等待被调用者的响应 当更多的服务请求到这些资源导致更多的请求等待,发生连锁效应(雪崩效应)断路器有完全打开状态:一段时间内 达到一定的 ...
- Mybatis框架基础入门(三)--Mapper动态代理方式开发
使用MyBatis开发Dao,通常有两个方法,即原始Dao开发方法和Mapper动态代理开发方法. 原始Dao开发方法需要程序员编写Dao接口和Dao实现类,此方式开发Dao,存在以下问题: Dao方 ...
- Invalid prop: type check failed for prop "maxlength"
Invalid prop: type check failed for prop "maxlength", element 框架时,因为想限制文本框的输入长度, maxlength ...