Spark在Local环境下的使用
① 将 spark-3.0.0-bin-hadoop3.2.tgz 文件上传到 Linux (cd /opt/module路径下)并解压缩
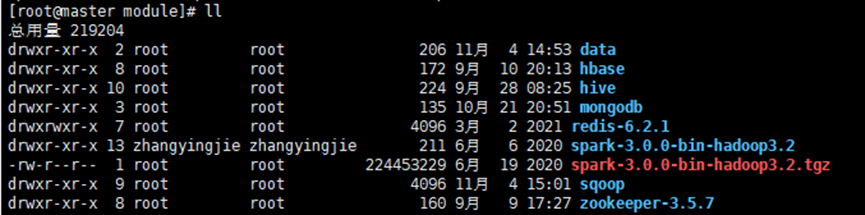
② 修改spark-3.0.0-bin-hadoop3.2名称为spark-local
mv spark-3.0.0-bin-hadoop3.2/ spark-local
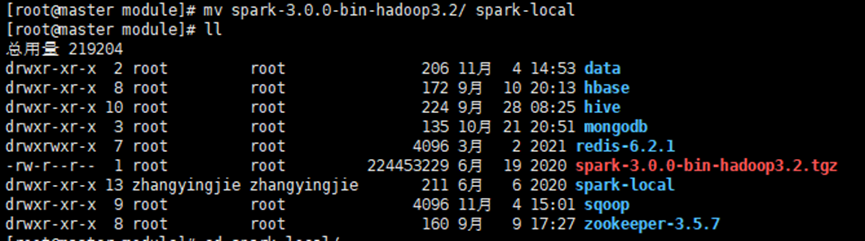
③ 进入spark-local
cd spark-local/
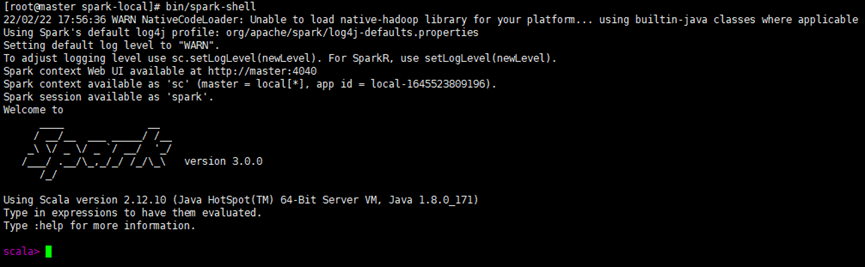
④ 启动local环境
bin/spark-shell
⑤ Web页面访问:master:4040
⑥ 命令行的使用
sc.textFile("data/data.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect

⑦ 提交应用(cd /opt/module/spark-local路径下)
1) --class 表示要执行程序的主类,可以更换为自己写的应用程序
2) --master local[2] 部署模式,默认为本地模式,数字表示分配的虚拟 CPU 核数量
3) spark-examples_2.12-3.0.0.jar 运行的应用类所在的 jar 包,可以设定为自己打的 jar 包
4) 数字 10 表示程序的入口参数,用于设定当前应用的任务数量
bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master local[2] \ ./examples/jars/spark-examples_2.12-3.0.0.jar \ 10

⑧ 退出本地模式
:quit
Spark在Local环境下的使用的更多相关文章
- Spark 在 Window 环境下的搭建
1.java/scala的安装 - 安装JDK下载: http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-21 ...
- Spark在Windows环境下的配置
1.下载 下载地址:http://spark.apache.org/downloads.html. 选择下面版本下载. 2.操作流程:https://blog.csdn.net/nxw_tsp/art ...
- windows下 eclipse搭建spark java编译环境
环境: win10 jdk1.8 之前有在虚拟机或者集群上安装spark安装包的,解压到你想要放spark的本地目录下,比如我的目录就是D:\Hadoop\spark-1.6.0-bin-hadoop ...
- 在local模式下的spark程序打包到集群上运行
一.前期准备 前期的环境准备,在Linux系统下要有Hadoop系统,spark伪分布式或者分布式,具体的教程可以查阅我的这两篇博客: Hadoop2.0伪分布式平台环境搭建 Spark2.4.0伪分 ...
- Windows下搭建Spark+Hadoop开发环境
Windows下搭建Spark+Hadoop开发环境需要一些工具支持. 只需要确保您的电脑已装好Java环境,那么就可以开始了. 一. 准备工作 1. 下载Hadoop2.7.1版本(写Spark和H ...
- IntelliJ IDEA在Local模式下Spark程序消除日志中INFO输出
在使用Intellij IDEA,local模式下运行Spark程序时,会在Run窗口打印出很多INFO信息,辅助信息太多可能会将有用的信息掩盖掉.如下所示 要解决这个问题,主要是要正确设置好log4 ...
- kerberos环境下spark消费kafka写入到Hbase
一.准备环境: 创建Kafka Topic和HBase表 1. 在kerberos环境下创建Kafka Topic 1.1 因为kafka默认使用的协议为PLAINTEXT,在kerberos环境下需 ...
- spark最新源码下载并导入到开发环境下助推高质量代码(Scala IDEA for Eclipse和IntelliJ IDEA皆适用)(以spark2.2.0源码包为例)(图文详解)
不多说,直接上干货! 前言 其实啊,无论你是初学者还是具备了有一定spark编程经验,都需要对spark源码足够重视起来. 本人,肺腑之己见,想要成为大数据的大牛和顶尖专家,多结合源码和操练编程. ...
- Windows环境下在IDEA编辑器中spark开发安装步骤
以下是windows环境下安装spark的过程: 1.安装JDK(version:1.8.0.152) 2.安装scala(version:2.11/2.12) 3.安装spark(version:s ...
随机推荐
- 决策树3:基尼指数--Gini index(CART)
既能做分类,又能做回归.分类:基尼值作为节点分类依据.回归:最小方差作为节点的依据. 节点越不纯,基尼值越大,熵值越大 pi表示在信息熵部分中有介绍,如下图中介绍 方差越小越好. 选择最小的那个0.3 ...
- 【Android开发】毛玻璃效果
使用一:静态控件上使用 先附上自定义view-BlurringView public class BlurringView extends View { private int mDownsample ...
- Android Studio 异常以及解决方案
1. Error:(1, 0) Plugin is too old, please update to a more recent version, or set ANDROID_DAILY_OVER ...
- Message: 'geckodriver' executable needs to be in PATH
1.下载geckodriver.exe:下载地址:mozilla/geckodriver请根据系统版本选择下载:(如Windows 64位系统) 2.下载解压后将getckodriver.exe复制到 ...
- java的命令行参数到底怎么用,请给截图和实际的例子
8.2 命令行参数示例(实验) public class Test { public static void main(String[] args){ if(args.length ...
- jsp基础、el技术、jstl标签、javaEE的开发模式
一.jsp技术基础 1.jsp脚本和注释 jsp脚本: 1)<%java代码%> ----- 内部的java代码翻译到service方法的内部 2)<%=java变量或表达式> ...
- 虚拟机上 安装 CentoOS 7.5 1804 过程记录
1.准备安装镜像 在开始安装CentOS之前,必须下载安装ISO映像.镜像可从CentOS网站https://www.centos.org/download/.提供以下基本类型的镜像: DVD ISO ...
- Wireshark捕获网易云音乐音频文件地址
打开Wireshark,开始捕获. 打开网易云音乐,然后播放一首歌. Wireshark停时捕获,然后在不活的文件中搜索字符串"mp3".可以发现有如下信息: 将其中的内容:&qu ...
- php代码审计之——phpstorm动态调试
xdebug调试 调试环境部署 xdebug的版本需要与PHP版本相对于,所以不要轻易改变PHP环境版本. 0 配置php解析器 1 下载对应版本的xdebug xdebug官网下载地址:https: ...
- 取地址与解引用 C指针浅析
C语言指针入门需要掌握的两个概念就是取地址&和解引用*,下面我们按例子来理解这两个符号的使用. int main() { int a = 0; int* pa = &a;//取地址操作 ...