DAST 黑盒漏洞扫描器 第五篇:漏洞扫描引擎与服务能力
0X01 前言
转载请标明来源:https://www.cnblogs.com/huim/
本身需要对外有良好的服务能力,对内流程透明,有日志、问题排查简便。
这里的服务能力指的是系统层面的服务,将扫描器封装成提供给业务的业务服务能力不在该篇讲述范围内
0X02 简单的扫描
高端的漏洞往往用最朴实的扫描方法
最简单的扫描需求,只需要从数据库中读取数据,定期跑一遍所有规则就好了。

一个脚本更新资产,一个脚本定时读取数据、结合规则进行扫描、并把结果打到数据库里,一个脚本定时读取结果发邮件,这样就已经满足SRC自动化挖漏洞的需求了,而且效果还不错。
0X03 分布式扫描
随着扫描的资产变多,单个机器的龟速扫描令人着急,所以运行规则这一步加上分布式,即任务打到队列(redis/MQ/kafka等),再由多个节点运行扫描规则、输出漏洞结果

0X04 几个数据源扫描
这样很方便的可以扫描主机漏洞
再往后,不想只单单的扫描主机漏洞了,也想扫描注入/XSS/SSRF/XXE等基于url的漏洞,有了url类型数据。
甚至发现有的漏洞应该是针对域名的(单纯的IP+端口请求到达不了负载均衡),又有了domain类型的数据。

0X05 多任务扫描
这时候生产模块还能应付得过来,即读取各类型数据、绑定各类型插件。
但是有时候新增了规则,想单纯的扫描对着所有数据扫描这条规则,需要另外起脚本加一个临时的生产者。
有时候新增了一批资产,想单独对着这批资产扫描所有的规则,又需要临时写个生产者脚本。
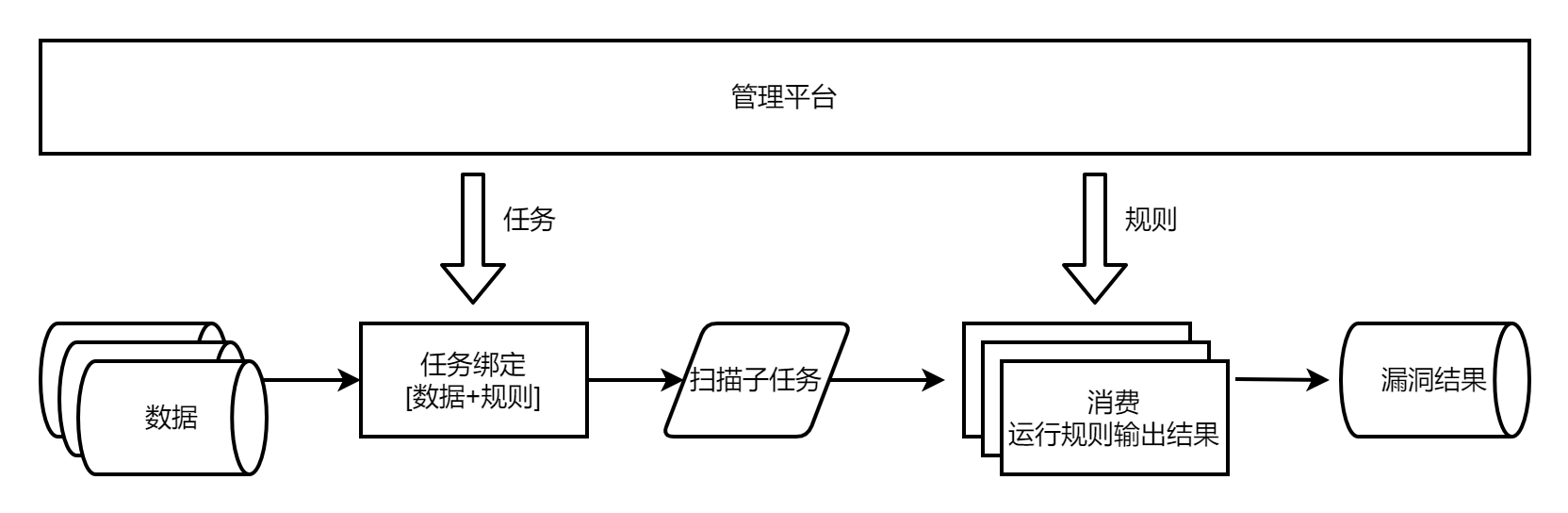
由此代码变得冗杂,操作变得繁琐,于是有了任务的概念。
任务用于绑定数据与规则,一个任务就是一个生产扫描子任务的单位。
这样增量规则扫描全量数据,新增一个任务绑定这个规则和对应的数据;增量资产扫描全量规则,新增一个任务绑定这批资产和对应的规则。
而从数据库上操作任务与规则变得不太方便,于是加上了可视化平台,可在web端发布扫描任务、新增修改规则。
0X06 多数据源扫描
而在甲方内部,随着接入的数据源越来越多,url数据有镜像流量、爬虫流量、代理流量、nginx流量等等,host数据有hids agent流量、黑盒资产探测流量、cmdb/IT等流量,domain有域名爆破流量、内部运维系统获取的流量等。
每多一个数据源,都得加一段代码逻辑 : "当数据源是a的时候,从哪哪哪获取流量数据"。
当数据源数量超过十种,任务模块的数据源获取代码变得很冗杂,且并硬编码横行(从哪哪哪获取数据)、逻辑写死不通用(a的数据要从接口分页遍历、b的数据需要从redis读、c的数据是kafka、d的数据从数据库获取)。
某些数据不走中间的某段过滤匹配逻辑,于是又要加一个字段 is_xxx 标识 ,再在引擎里 if is_xxx=True,代码通用性低、高度耦合,遇到bug时排查成本极高,比如遇到这个流量怎么会有这样的输出结果、怎么会报错这类问题时,往往花半天一天追踪流量。
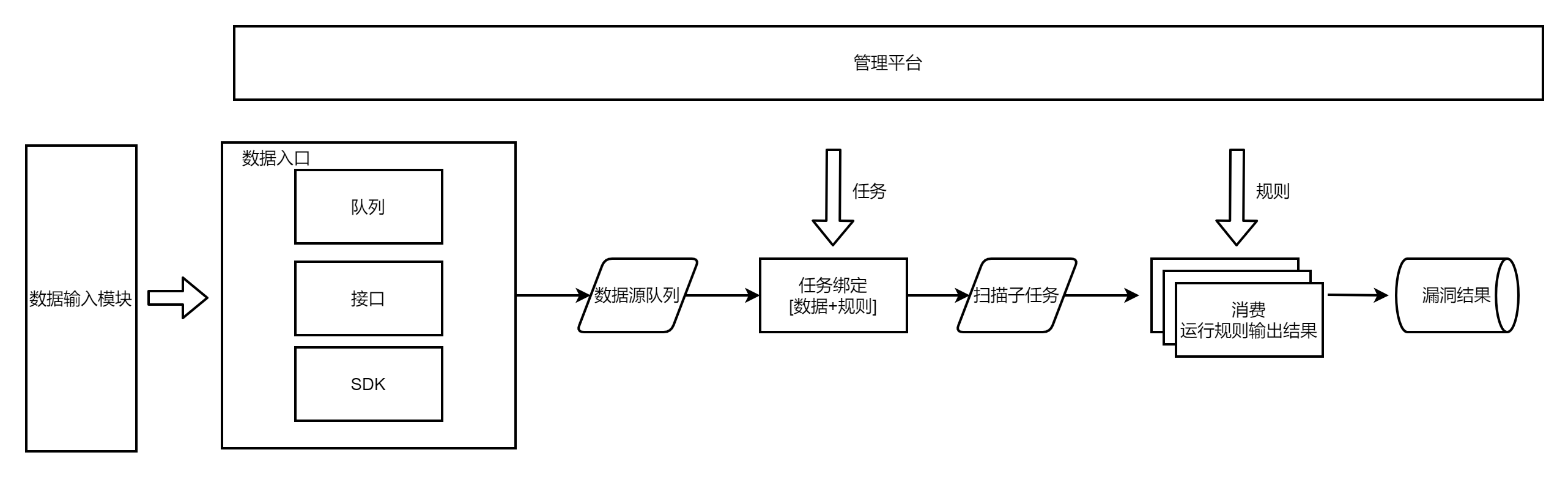
故而需要对数据源进行改造,统一数据源输入格式,数据源分几种类型,url/host/domain,每种类型都有固定的格式,由外部按照这种格式进行输入。
在数据源过多时,外部的输入代码太多了,可额外抽象出来形成数据输入模块。
比如定义redis类型数据从哪里获取、接口怎么分页获取数据、数据库怎么迭代读取等,再一一配置数据格式转换方式。这样再遇到需要新增的流量类型,需要新增的代码就是可复用的某类数据获取方式。
0X07 系统间服务能力
但是又遇到一个问题,遇到跨部门或者跨项目需要调用扫描能力时,很不方便,输入上需要自己配置数据来源,还需要扫描开发人员添加这类数据,扫描结果还需要去数据库获取,有的没结果不知道到底是没扫描还是没漏洞。
对于业务方,需求增改、服务调用不方便。
所以需要提高服务提供的能力,对于调用方来说,扫描是一个黑箱子,只管传入数据、启动任务、获取结果,提供给调用方的是扫描服务能力。
对于扫描引擎开发方,对外进行引擎能力封装,服务与上下游拆分开,也实现低耦合、高可维护、可扩展易扩展,不会因需求增改而频繁改动引擎代码、从而导致代码冗余、开发维护成本上升。
实现方式:
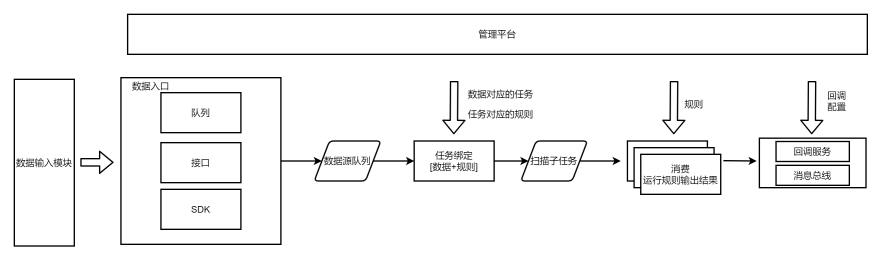
数据接入时,调用方在管理平台注册数据标签,并在传入数据时标明数据标签(抽象数据配置步骤);
结果输出时,调用方注册回调接口(数据打往回调接口),扫描结果分有漏洞/无漏洞/没扫描这一类,回调接口选择接收的结果类型;或注册处置结果标签,扫描结果打给消息总线。
回调方式不知道对方接口设置的状态,可能接口报错了消息没有正确打过去,可能接口返回200的 status: false但无法判断是失败了,简单来讲就是无法保证数据一致性,扫描结果里有但接口因为报错没有这个结果。所以还是尽量使用消息总线的方式,由消费方对消费失败的数据进行记录、排查并作再消费,保证接收结果的接口不会丢数据。
再由注册方操作任务,绑定待扫描的流量的标签,需要扫描的规则,处置的方式即结果是打给某个回调或者是打上某个结果标签。
实现效果:
这样将引擎封装起来,基本可以保证引擎中不会因为过多的数据源,而东一块西一块,有很多的针对不同数据源读取的代码。
引擎本身只保证数据读取、按照规定的任务选择扫描规则、将扫描的结果打到结果队列或者打回给调用方。
0X08 全流程日志
但还有另外一个问题,排查问题成本比较大。
扫描器引擎逻辑相比部分产品会比较复杂,主要涉及到其中的存活检测、集群判断、白名单限制、QPS控制、任务调度等功能,有时候丢流量或者因为某个字段不对导致漏报、在插件运行前请求的内容有问题导致判断为不存活的流量从而漏报。
这些情况在以redis为队列的引擎中,排查起来比较麻烦。
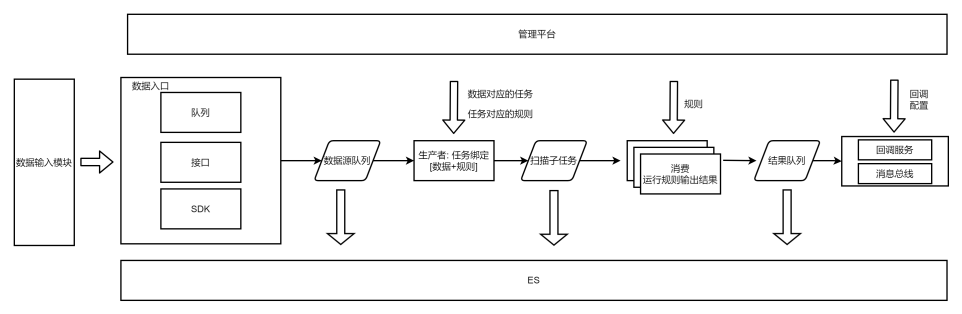
所以需要全流程的日志:最好能知道几个关键步骤的中间结果是什么样的,遇到问题时排查方便。扫描器在去重后扫描中间过程数据量不如IDS大 (日百亿处理结果),大概也就上千万,可以全部记录下来,资源紧张可以只记录一段时间。
关于日志种类:我们溯源排查时一般需要的中间结果有数据源、扫描子任务、扫描结果。
关于日志实现:redis pop后数据就没了,引擎读后做双写比较麻烦。
所以选择可订阅的消息队列,比如kafka,引擎使用一个group进行消息消费,再起一个服务用另外的group对这批topic的数据进行存储,熟悉的ELK结构。
DAST 黑盒漏洞扫描器 第五篇:漏洞扫描引擎与服务能力的更多相关文章
- DAST 黑盒漏洞扫描器 第六篇:运营篇(终)
0X01 前言 转载请标明来源:https://www.cnblogs.com/huim/ 当项目功能逐渐成熟,同时需要实现的是运营流程和指标体系建设.需要工程化的功能逐渐少了,剩下的主要工作转变成持 ...
- DAST 黑盒漏洞扫描器 第四篇:扫描性能
0X01 前言 大多数安全产品的大致框架 提高性能的目的是消费跟得上生产,不至于堆积,留有余力应对突增的流量,可以从以下几个方面考虑 流量:减少无效流量 规则:减少规则冗余请求 生产者:减少无效扫描任 ...
- DAST 黑盒漏洞扫描器 第三篇:无害化
0X01 前言 甲方扫描器其中一个很重要的功能重点,就是无害化,目的是尽量降低业务影响到可接受程度. 做过甲方扫描器,基本上对于反馈都有所熟悉. "我们的服务有大量报错,请问和你们有关么&q ...
- DAST 黑盒漏洞扫描器 第二篇:规则篇
0X01 前言 怎么衡量一个扫描器的好坏,扫描覆盖率高.扫描快.扫描过程安全 而最直接的效果就是扫描覆盖率高(扫的全) 怎么扫描全面,1 流量全面 2 规则漏报低 流量方面上篇已经讲过,这篇主要讲扫描 ...
- web网络漏洞扫描器编写
这两天看了很多web漏洞扫描器编写的文章,比如W12scan以及其前身W8scan,还有猪猪侠的自动化攻击背景下的过去.现在与未来,以及网上很多优秀的扫描器和博客,除了之前写了一部分的静湖ABC段扫描 ...
- qqzoneQQ空间漏洞扫描器的设计attilax总结
qqzoneQQ空间漏洞扫描器的设计attilax总结 1.1. 获取对方qq(第三方,以及其他机制)1 1.2. QQ空间的html流程1 1.3. 判断是否有权限1 1.4. 2015年度Web服 ...
- Web安全测试中常见逻辑漏洞解析(实战篇)
Web安全测试中常见逻辑漏洞解析(实战篇) 简要: 越权漏洞是比较常见的漏洞类型,越权漏洞可以理解为,一个正常的用户A通常只能够对自己的一些信息进行增删改查,但是由于程序员的一时疏忽,对信息进行增删改 ...
- 6. Vulnerability scanners (漏洞扫描器 11个)
Nessus是最流行和最有能力的漏洞扫描程序之一,特别为UNIX系统. 它最初是免费的和开源的,但是他们在2005年关闭了源代码,并在2008年删除了免费的“注册Feed”版本.现在要每年花费2,19 ...
- 5. Web vulnerability scanners (网页漏洞扫描器 20个)
5. Web vulnerability scanners (网页漏洞扫描器 20个) Burp Suite是攻击Web应用程序的集成平台. 它包含各种工具,它们之间有许多接口,旨在方便和加快攻击应用 ...
随机推荐
- C/C++在Win32控制台播放Bad Apple
##前言 这里首先你需要准备一些文件,将一个Bad Apple的视频分别转换成txt和mp3格式(mp3用来作为背景音乐) 我将txt文件放到exe文件目录下的子目录files里了 转换方法可以用Ad ...
- 3.初识Java
一.Java特性和优势 简单性 面向对象 可移植性 高性能 分布式 动态性 多线程 安全性 健壮性 二.Java三大版本 一次编写到处运行 JavaSE:标准版(桌面程序,控制台开发) JavaME: ...
- redis 知识点收集 注意理解底层
学redis,首先要明白其特性,其次要理解明白redis与操作系统底层的关系,这点很重要.这是一个优秀的学习方法,作为计算机专业,应当时刻想着技术和操作系统计算机组成数据结构的联系,听起来有些书生气死 ...
- Logistic regression中regularization失败的解决方法探索(文末附解决后code)
在matlab中做Regularized logistic regression 原理: 我的代码: function [J, grad] = costFunctionReg(theta, X, y, ...
- Java语言学习day34--8月09日
##13Math类的方法_1 A:Math类中的方法 /* * static double sqrt(double d) * 返回参数的平方根 */ public static void functi ...
- GitHub 自动合并 pr 的机器人——auto-merge-bot
本文首发于 Nebula Graph Community 公众号 背景 作为一款开源的分布式图数据库产品,Nebula 所有的研发流程都在 GitHub 上运作.基于 GitHub 生态 Nebula ...
- 攻防世界-MISC:Test-flag-please-ignore
这是攻防世界MISC高手进阶区的题目,题目如下 点击下载附件一,解压后得到一个文本文件,打开后得到一串字符串如下: 通过观察,发现是16进制的字符串(由0~f)的字符串组成,尝试将16进制转字符串,结 ...
- WFP资源
资源基础 WPF程序在代码中以及在标记中的各个位置定义资源,具有高效性.可维护性.适应性的优点. 资源的层次 <Windows.Resource> <ImageBrush x:key ...
- windows使用命令行终止端口的进程
C:\Users\fxz>netstat -ano | find "8093" TCP 0.0.0.0:8093 0.0.0.0:0 LISTENING 3956 TCP [ ...
- Linux操作系统,为什么需要内核空间和用户空间?
点击上方"开源Linux",选择"设为星标" 回复"学习"获取独家整理的学习资料! 本文以 32 位系统为例介绍内核空间(kernel sp ...