在MongoDB的MapReduce上踩过的坑
太久没动这里,目前人生处于一个新的开始。这次博客的内容很久前就想更新上来,但是一直没找到合适的时间点(哈哈,其实就是懒),主要内容集中在使用Mongodb时的一些隐蔽的MapReduce问题:
1、Reduce时的计数问题
2、Reduce时的提取数据问题
另外,补充一个小tips:mongoDB中建立的索引,优先使用固定的,而不要使用范围。
一、MapReduce时的计数问题
这个问题主要出现在使用“+1”的思路去计算累计次数时。如果在Map后的某一类中,记录量过大,就会导致计数失败。
具体演示如下:
原始数据(有400条一样的存在数据库results表中):{ "grade" : 1, "name" : "lekko", "score" : 95 }
进行MapReduce:
db.runCommand({ mapreduce: "results",
map : function Map() {
emit(
{grade:this.grade},
{recnum:1,score:this.score}
);
},
reduce : function Reduce(key, values) {
var reduced = {recnum:0,score:0};
values.forEach(function(val){
reduced.score += val.score;
++reduced.recnum;
});
return reduced;
},
finalize : function Finalize(key, reduced) {
return reduced;
},
out : { inline : 1 }
});
满怀希望地以为value.recnum会输出400,结果却是101!而value.scorce却是输出的正确的:38000(95*400)。本人在这疑惑了好久,并且通过更改reduce函数: function Reduce(key, values) { return {test:values}; } ,发现数据是这样的:
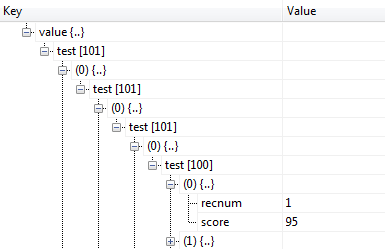
在原本Reduce函数中的forEach只遍历了第一层的数据,即101个,所以++操作也只做了101次!
经过思考,导致问题的原因关键就在于MapReduce中emit后的Bosn的数据格式,一个大于100的Array,会被拆分存储,变成了非线性的链表结构,如图:
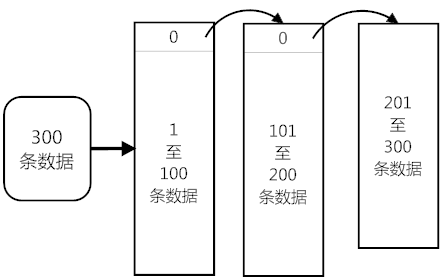
那么,分数相加却能正确,可以大胆地推测:“reduced.score += val.score;” 语句可以智能地找到所有子结点的score并相加!
最后,这里给出计数的替代方案,修改Reduce的++,改用+=操作:
function Reduce(key, values) { ;
var reduced = {recnum:0,score:0};
values.forEach(function(val){
reduced.score += val.score;
reduced.recnum += val.recnum;
});
return reduced;
}
二、在Reduce中把数据提取出来组成Array
这个问题产生的原因与上面的相似,也是由于emit后的数据在reduce时是非线性的(有层次关系),所以提取数据字段时也会产生问题,为了测试,往上面所说的表中再插入3条数据:
{ "grade" : 1, "name" : "monkey", "score" : 95 }, { "grade" : 2, "name" : "sudan", "score" : 95 }, { "grade" : 2, "name" : "xiaoyan", "score" : 95 }
编写提取出各个grade的所有人名(不重复)列表:
db.runCommand({ mapreduce: "results",
map : function Map() {
emit(
{grade:this.grade},
{name:this.name}
);
},
reduce : function Reduce(key, values) {
var reduced = {names:[]};
values.forEach(function(val) {
var isExist = false;
for(var i = 0; i<reduced.names.length; i++) {
var cur = reduced.names[i];
if(cur==val.name){
isExist = true;
break;
}
}
if(!isExist)
reduced.names.push(val.name);
});
return reduced;
},
finalize : function Finalize(key, reduced) {
return reduced;
},
out : { inline : 1 }
});
返回结果为:
{ "_id" : {"grade" : 1},
"value" :{ "names" : [null,"lekko"]}
},
{ "_id" : {"grade" : 2},
"value" :{ "names" : ["xiaoyan","sudan"]}
}
新插入的grade=2的两条数据正常了,但grade=1的monkey却不见了!采用问题一的思维方式,肯定也是在Reduce时遍历到一个数组对象,其name值为空,也给添加进来了,monkey对象根本就没有访问到。
解决这一问题的方法是,抛弃MapReduce,改用Group:
db.results.group({
key : {"grade":true},
initial : {names:[]},
reduce : function Reduce(val, out) {
var isExist = false;
for(var i = 0; i<out.names.length; i++) {
var cur = out.names[i];
if(cur==val.name){
isExist = true;
break;
}
}
if(!isExist)
out.names.push(val.name);
},
finalize : function Finalize(out) {
return out;
}});
这样,便可正常取到grade=1时的name非重复集合!虽说MapReduce比Group要强大,速度也要快很多,但像这种要从大量项(超过100条)中提取数据,就有很大风险了。所以,使用MapReduce时,尽量只用到累加、累减、累乘等基本操作,不要去用++、push、delete等可能会产生风险的操作!
三、补充几个小Tips
1、使用Group或MapReduce时,如果一个分类只有一个元素,那么Reduce函数将不会执行,但Finalize函数还是会执行的。这时你要在Finalize函数中考虑一个元素与多个元素返回结果的一致性(比如,你把问题二中插入一个grade=3的数据看看,执行返回的grade=3时还有names集合吗?)。
2、查找范围时的索引效率,如果查询的是一个值的范围,它索引的优先级是很低的。比如一个表test,有海量元素,字段有'committime'、'author',建立了两个索引:author_1、committime:-1,author:1,下面的测试证明了效率:
db.test.find({'committime':{'$gt':910713600000,'$lte':1410192000000},'author':'lekko'}).hint({committime:-1,author:1}).explain() "millis" : 49163
db.test.find({'committime':{'$gt':910713600000,'$lte':1410192000000},'author':'lekko'}).explain() author_1 "millis" : 2641
转载请注明原址:http://www.cnblogs.com/lekko/p/3963418.html
在MongoDB的MapReduce上踩过的坑的更多相关文章
- mongodb3.6 (五)net 客户端访问mongodb设置超时时间踩过的“坑”
前言 在上一篇文章中,我们有提到net访问mongodb连接超时默认为30秒,这个时间在实际项目中肯定是太长的.而MongoClientSettings 也确是提供了超时属性,如下图: 可实际使用中, ...
- Redis上踩过的一些坑
来自: http://blog.csdn.net//chenleixing/article/details/50530419 上上周和同事(龙哥)参加了360组织的互联网技术训练营第三期,美团网的DB ...
- MongoDB 的 MapReduce 大数据统计统计挖掘
MongoDB虽然不像我们常用的mysql,sqlserver,oracle等关系型数据库有group by函数那样方便分组,但是MongoDB要实现分组也有3个办法: * Mongodb三种分组方式 ...
- MongoDb 用 mapreduce 统计留存率
MongoDb 用 mapreduce 统计留存率(金庆的专栏)留存的定义采用的是新增账号第X日:某日新增的账号中,在新增日后第X日有登录行为记为留存 输出如下:(类同友盟的留存率显示)留存用户注册时 ...
- mongoDB实现MapReduce
一.MongoDB Map Reduce Map-Reduce是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结果合并成最终结果(REDUCE).MongoDB提供的Ma ...
- MongoDB:Map-Reduce
Map-reduce是一个考虑大型数据得到实用聚集结果的数据处理程式(paradigm).针对map-reduce操作,MongoDB提供来mapreduce命令. 考虑以下的map-reduce操作 ...
- [转帖]美团在Redis上踩过的一些坑-1.客户端周期性出现connect timeout
美团在Redis上踩过的一些坑-1.客户端周期性出现connect timeout 博客分类: redis 运维 jedisconnect timeoutnosqltcp 转载请注明出处哈:http ...
- 美团在Redis上踩过的一些坑-目录(本人非美团)(转)
来自:http://carlosfu.iteye.com/blog/2254154 分为5个部分: 一.周期性出现connect timeout 二.redis bgrewriteaof问 ...
- 记录近期小改Apriori至MapReduce上的心得
·背景 前一阵,一直在研究一些ML的东东,后来工作关系暂停了一阵.现在继续把剩下一些热门的算法再吃吃透,"无聊+逗比"地把他们搞到MapReduce上.这次选择的入手对象为Apri ...
随机推荐
- Lind.DDD.LindMQ~关于持久化到Redis的消息格式
回到目录 关于持久化到Redis的消息格式,主要是说在Broker上把消息持久化的过程中,需要存储哪些类型的消息,因为我们的消息是分topic的,而每个topic又有若干个queue组成,而我们的to ...
- HTML学习笔记
HTML学习笔记 2016年12月15日整理 Chapter1 URL(scheme://host.domain:port/path/filename) scheme: 定义因特网服务的类型,常见的为 ...
- 微信小程序教程汇总
目前市面上在内测期间出来的一些实战类教程还是很不错的,主要还是去快速学习小程序开发的整体流程,一个组件一个组件的讲的很可能微信小程序一升级,这个组件就变了,事实本就如此,谁让现在是内测呢.我们不怕,下 ...
- hbase集群安装与部署
1.相关环境 centos7 hadoop2.6.5 zookeeper3.4.9 jdk1.8 hbase1.2.4 本篇文章仅涉及hbase集群的搭建,关于hadoop与zookeeper的相关部 ...
- linux下配置matlab运行环境(MCR)
在安装好的matlab下有MCR(MatlabCompilerRuntime)在matlab2011/toolbox/compiler/deploy/glnxa64下找到MCRInstaller.zi ...
- Struts2数据校验
Struts2数据校验 1.常见数据校验方法 表单数据的校验方式: 表单中的数据必须被效验以后才能够被使用,常用的效验方式分为两种: 前台校验:也称之为客户端效验,主要是通过JS编程的方式进行表单数据 ...
- CYQ.Data V5 分布式缓存Redis应用开发及实现算法原理介绍
前言: 自从CYQ.Data框架出了数据库读写分离.分布式缓存MemCache.自动缓存等大功能之后,就进入了频繁的细节打磨优化阶段. 从以下的更新列表就可以看出来了,3个月更新了100条次功能: 3 ...
- ASP.NET Core "完整发布,自带运行时" 到jexus
一.阅读前须知 1.使用 jexus整合asp.net core的优点: 1)支持多站点,同一端口可以同时支持任何多的asp.net core应用程序: 2)应用程序启动.停 ...
- webpack解惑:require的五种用法
我之前在 <前端搭环境之从入门到放弃>这篇文章中吐槽过,webpack中可以写commonjs格式的require同步语法,可以写AMD格式的require回调语法,还有一个require ...
- [转]Java实现定时任务的三种方法
在应用里经常都有用到在后台跑定时任务的需求.举个例子,比如需要在服务后台跑一个定时任务来进行非实时计算,清除临时数据.文件等.在本文里,我会给大家介绍3种不同的实现方法: 普通thread实现 Tim ...