Java学习----HashMap原理
1.HashMap的数据结构
数组的特点是:寻址容易,插入和删除困难;而链表的特点是:寻址困难,插入和删除容易。那么我们能不能综合两者的特性,做出一种寻址容易,插入删除也容易的数据结构?答案是肯定的,这就是我们要提起的哈希表,哈希表有多种不同的实现方法,我接下来解释的是最常用的一种方法—— 拉链法,我们可以理解为“链表的数组” ,如图:
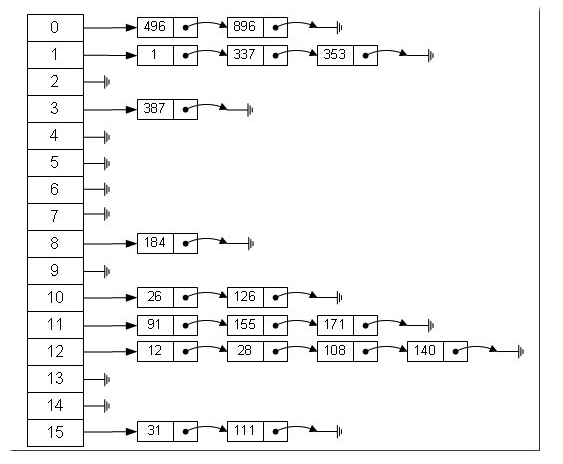
从上图我们可以发现哈希表是由数组+链表组成的,一个长度为16的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则存储到数组中呢。一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。比如上述哈希表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。
HashMap其实也是一个线性的数组实现的,所以可以理解为其存储数据的容器就是一个线性数组。这可能让我们很不解,一个线性的数组怎么实现按键值对来存取数据呢?这里HashMap有做一些处理。
1.首先HashMap里面实现一个静态内部类Entry,其重要的属性有 key , value, next,从属性key,value我们就能很明显的看出来Entry就是HashMap键值对实现的一个基础bean,我们上面说到HashMap的基础就是一个线性数组,这个数组就是Entry[],Map里面的内容都保存在Entry[]里面。
2.HashMap的存取实现
既然是线性数组,为什么能随机存取?这里HashMap用了一个小算法,大致是这样实现:
//存储时:
int hash = key.hashCode();// 这个hashCode方法这里不详述,只要理解每个key的hash是一个固定的int值
int index = hash % Entry[].length;
Entry[index] = value; //取值时:
int hash = key.hashCode();
int index = hash % Entry[].length;
return Entry[index];
到这里我们轻松的理解了HashMap通过键值对实现存取的基本原理
3.疑问:如果两个key通过hash%Entry[].length得到的index相同,会不会有覆盖的危险?
这里HashMap里面用到链式数据结构的一个概念。上面我们提到过Entry类里面有一个next属性,作用是指向下一个Entry。打个比方, 第一个键值对A进来,通过计算其key的hash得到的index=0,记做:Entry[0] = A。一会后又进来一个键值对B,通过计算其index也等于0,现在怎么办?HashMap会这样做:B.next = A,Entry[0] = B,如果又进来C,index也等于0,那么C.next = B,Entry[0] = C;这样我们发现index=0的地方其实存取了A,B,C三个键值对,他们通过next这个属性链接在一起。所以疑问不用担心。也就是说数组中存储的是最后插入的元素。到这里为止,HashMap的大致实现,我们应该已经清楚了。
当然HashMap里面也包含一些优化方面的实现,这里也说一下。比如:Entry[]的长度一定后,随着map里面数据的越来越长,这样同一个index的链就会很长,会不会影响性能?HashMap里面设置一个因素(也称为因子),随着map的size越来越大,Entry[]会以一定的规则加长长度。
3.解决hash冲突的办法
- 开放定址法(线性探测再散列,二次探测再散列,伪随机探测再散列)
- 再哈希法
- 链地址法
- 建立一个公共溢出区
Java中hashmap的解决办法就是采用的链地址法。
4.实现自己的HashMap
MapTest.java
package General;
import java.util.*;
public class MapTest {
public static void main(String[] args){
Map<String,Employee> staff=new HashMap<>();
staff.put("144-25-5456",new Employee("Amy Lee"));
staff.put("567-24-2456",new Employee("Harry Hacker"));
staff.put("157-62-7935",new Employee("Gary Cooper"));
staff.put("465-62-5537",new Employee("Francesca Cruz")); //print all entries
System.out.println(staff); //remove an entry
staff.remove("567-24-2456"); //replace an entry
staff.put("456-62-5527",new Employee("Francesca Miller")); //look up a value
System.out.println(staff.get("157-62-7935")); //iterate through all entries
for(Map.Entry<String, Employee>entry:staff.entrySet()){
String key=entry.getKey();
Employee value=entry.getValue();
System.out.println("Key="+key+", value="+value);
}
}
}
class Employee{
private String name;
public Employee(String n){
name=n;
}
public String getName(){
return name;
}
}
{157-62-7935=Amy Lee,
567-24-2456=Harry Hacker,
144-25-5456=Gary Cooper,
465-62-5537=Francesca Cruz}
Francesca Miller
Key=157-62-7935, value=Amy Lee
Key=144-25-5456, value=Harry Hacker
Key=465-62-5537, value=Gary Cooper
Key=456-62-5527, value=Francesca Cruz
Java学习----HashMap原理的更多相关文章
- Java基础-hashMap原理剖析
Java基础-hashMap原理剖析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.什么是哈希(Hash) 答:Hash就是散列,即把对象打散.举个例子,有100000条数 ...
- java中HashMap原理?
参考:https://www.cnblogs.com/yuanblog/p/4441017.html(推荐) https://blog.csdn.net/a745233700/article/deta ...
- Java学习——HashMap
遍历 Map map = new HashMap(); Iterator iter = map.entrySet().iterator(); while (iter.hasNext()) { Map. ...
- 【转】Java学习---HashMap的工作原理
[原文]https://www.toutiao.com/i6592560649652404744/ HashMap的工作原理是近年来常见的Java面试题.几乎每个Java程序员都知道HashMap,都 ...
- java的HashMap 原理
https://www.cnblogs.com/chengxiao/p/6059914.html 哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比 ...
- 【转】Java学习---HashMap和HashSet的内部工作机制
[原文]https://www.toutiao.com/i6593863882484220430/ HashMap和HashSet的内部工作机制 HashMap 和 HashSet 内部是如何工作的? ...
- java容器HashMap原理
1.为什么需要HashMap 前面我们说了ArrayList和LinkedList,它们对容器内的对象都能实现增.删.改.查.遍历等操作, 并且对应不同的情况,我们可以选择不同的List,用以提高效率 ...
- Java中HashMap的实现原理
最近面试中被问及Java中HashMap的原理,瞬间无言以对,因此痛定思痛觉得研究一番. 一.Java中的hashCode和equals 1.关于hashCode hashCode的存在主要是用于查找 ...
- 学习java之HashMap和TreeMap
HashMap和TreeMap是Map接口的两种实现,ArrayDeque和LinkedList是Queue接口的两种实现方式.下面的代码是我今天学习这四个数据结构之后写的.还是不熟悉,TreeMap ...
随机推荐
- Win32中常用消息
一 .WM_PAINT消息 1 WM_PAINT的产生 由于窗口的互相覆盖等,产生需要绘制的区域,那么会产生WM_PAINT消息. 一般情况下,不直接发送WM_PAINT消息,通过API声明需要绘 ...
- 任意轴算法 ( Arbitrary Axis Algorithm )
已知三维空间中任意单位向量,求以该向量为Z轴的local正交坐标系: 如上图,每个模型都有自己local 坐标系,已知其中一个朝向求另外两个方向. 在autodesk中采用的是Arbitrary Ax ...
- HDOJ/HDU 1297 Children’s Queue(推导~大数)
Problem Description There are many students in PHT School. One day, the headmaster whose name is Pig ...
- 实现自己的脚本语言ngscript之二:语法分析
ngscript的语法分析使用的是我自己的语法分析工具parseroid.与常用cc工具(yacc.bison.javacc.antlr.etc…)不同的是,parseroid生成的不是语法分析器的源 ...
- The equation - SGU 106(扩展欧几里得)
题目大意:有一个二元一次方程,给出系数值和x与y的取值范围,求出来总共有多少对整数解. 分析:有以下几点情况. 1,系数a=0, b=0, 当c != 0的时候结果很明显是无解,当c=0的时候x,y可 ...
- 超级好用的国际汇兑平台--Transferwise
一年的CSC留学快结束了,手里还剩了些积攒下来的美元.就国内那点博士的工资,出来一趟好不容易领了点美元可不想都给银行汇兑的手续费给吞了去. 这两天英国退欧,英镑大跌,美元有涨,是个把手里的美元寄回国换 ...
- thinkphp中使用PHPEXCEL导入数据
导入方法比较简单 但必须考虑到Excel本身单元格格式问题 例如以0开头的字符串读出来被去掉了前导0 成为float型而丢失一位 必须进行处理 <?php /** * Author lizhao ...
- timestamp ---自动更新修改时间 与 记录首次插入时间
自动更新修改时间: mysql> create table z(a int ,b timestamp on update current_timestamp); mysql> insert ...
- QSplashScreen类实现Qt程序启动画面
QSplashScreen类实现Qt程序启动画面 收藏人:zwsj 2013-09-13 | 阅:569 转:6 | 来源 | 分享 程序启动 ...
- Note | Javascript权威指南[第六版] 第1章:Javascript概述
JavaScript是一门高端的.动态的.弱类型的编程语言,非常适合面向对象和函数式的编程风格.JavaScript的语法源自Java,它的一等函数(first-class function)来 ...