5.Django|模型层--多表关系
多表操作
文件为 ----> orm2
数据库表关系之关联字段与外键约束
一对多
Book
id title price publish email addr
php 人民出版社 北京
python 沙河出版社 沙河
go 人民出版社 北京
java 人民出版社 北京 Book多
id title price publish_id
php
python
go
java Publish一
id name email addr
人民出版社 北京
沙河出版社 沙河 查询python这本书的出版社的邮箱(子查询)
select publish_id from Book where title="python"
select email from Publish where id= id=(上边的) 一旦确定是一对多的表关系:建立一对多的关系------->在多的表中建立关联字段(publish_id)
多对多:
Book
id title price publish_id
php
python
go
java Author
id name age addr
alex 北京
egon 南京 Book2Author
id book_id author_id alex出版过的书籍名称(子查询)
select id form Author where name='alex' (拿到alex这个id)
select book_id from Book2Author where author_id=
select title from Book id=book_id
一旦确定表关系是多对多:创建第三张表:
id book_id author_id
一对一:
Author
id name age Authordetail_id(unique)
alex
egon AuthorDetail
id addr gender tel gf_name
北京 male 小花
南京 male 小红 一旦确定是一对多的关系:建立一对多的关系------->在多的表中建立关联字段 (一个出版社可以出版多本书)
一旦确定多对多的关系:建立多对多的关系--------->创建第三张表(关联表):id和两个关联字段 (一本书可以有多个作者,一个作者可以出版多本书;)
一旦确定一对一的关系:建立一对一的关系---------->在两张表中的任意一张表中建立关联字段+unique (一个作者只有一个详细信息)
数据库表关系之sql创建关联表
对应的sql语句
Publish
Book
Author
AuthorDetail
Book2Author CREATE TABLE publish(
id INT PRIMARY KEY auto_increment,
name VARCHAR(20)
);
CREATE TABLE book(
id INT PRIMARY KEY auto_increment,
title VARCHAR (20),
price DECIMAL (8,2),
pub_date DATE,
publish_id INT,
FOREIGN KEY (publish_id) REFERENCES publish(id) 一个出版社可以出版多本书
);
CREATE TABLE authordetail(
id INT PRIMARY KEY auto_increment,
tel VARCHAR(20)
);
CREATE TABLE author(
id INT PRIMARY KEY auto_increment,
name VARCHAR(20),
age INT,
authordetail_id INT UNIQUE,
FOREIGN KEY(authordetail_id) REFERENCES authordetail(id) 一个作者只有一个详细信息
);
CREATE TABLE book2author(
id INT PRIMARY KEY auto_increment,
book_id INT,
author_id INT,
FOREIGN KEY(book_id) REFERENCES book(id),
FOREIGN KEY(author_id) REFERENCES author(id) 一个书可以有多个作者,一个作者可以出版多本书
);
1、创建模型(ORM生成关联表模型)
models
from django.db import models # Create your models here. '''
Book ----> Publish 一对多
'''
#作者详情表
class AuthorDetail(models.Model):
nid = models.AutoField(primary_key=True)
birthday=models.DateField()
telephone=models.BigIntegerField()
addr=models.CharField( max_length=64) class Author(models.Model):
nid = models.AutoField(primary_key=True)
name=models.CharField( max_length=32)
age=models.IntegerField()
# 与AuthorDetail建立一对一的关系
authorDetail=models.OneToOneField(to="AuthorDetail",on_delete=models.CASCADE) to_field="nid"这个可加可不加,它会默认去关联主键 #出版社表
class Publish(models.Model):
nid = models.AutoField(primary_key=True) id字段是自动添加的,如果不加主键数据库迁移的时候它也会给你默认生成一个id的字段,可以不写nid,写了就用你写的。
name=models.CharField( max_length=32)
city=models.CharField( max_length=32)
email=models.EmailField() class Book(models.Model):
nid = models.AutoField(primary_key=True)
title = models.CharField( max_length=32)
publishDate=models.DateField()
price=models.DecimalField(max_digits=5,decimal_places=2)
#建立一对多关联要有一个关联字段,上边的都是普通字段;给关联字段再绑定约束关系;
# 与Publish建立一对多的关系,外键字段建立在多的一方;django会自动给你补全publish_id; to就是foreign key哪个;加上引号就会在全局里边找;
publish=models.ForeignKey(to="Publish",to_field="nid",on_delete=models.CASCADE, null=True) #关联主键nid;这句话相当于下面两句;在django2.0要加上on_delete=models.CASCADE;null=True是允许这个字段为空
'''
publish_id INT,
FOREIGN KEY(publish_id)REFERENCES publish(id) to_field这个字段的nid主键;上边的publish在数据库迁移的时候就是这两句话
'''
#多对多,会自动生成第三张表;下面的几个意思是一样的
authors = models.ManyToManyField(to="Author")
'''
CREATE TABLE book2author( 上边那一句话执行的结果就相当于会生成这个;book_authors它就是这样拼的
id INT PRIMARY KEY auto_increment,
book_id INT,
author_id INT,
FOREIGN KEY(book_id)REFERENCES book(id),
FOREIGN KEY(author_id)REFERENCES author(id),
)
'''
# class Book2Author(models.Model): 这是自己写的第三张表
# nid = models.AutoField(primary_key=True)
# book = models.ForeignKey(to="Book") to_field="nid"
# author = models.ForeignKey(to="Author")
在settings里边
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
"app01",
]
#在models里边
publish=models.ForeignKey(to="Publish",to_field="nid",on_delete=models.CASCADE) #关联主键nid;这句话相当于两句;在django2.0要加上on_delete=models.CASCADE,只要用到Foreignkey(在一对多的时候,在one to one的时候)
C:\Users\Administrator\PycharmProjects\orm2>python manage.py makemigrations
Migrations for 'app01':
app01\migrations\0001_initial.py
- Create model Author
- Create model AuthorDetail
- Create model Book
- Create model Publish
- Add field publish to book
- Add field authorDetail to author C:\Users\Administrator\PycharmProjects\orm2>python manage.py migrate
Operations to perform:
Apply all migrations: admin, app01, auth, contenttypes, sessions
Running migrations:
Applying contenttypes.0001_initial... OK
Applying auth.0001_initial... OK
Applying admin.0001_initial... OK
Applying admin.0002_logentry_remove_auto_add... OK
Applying app01.0001_initial... OK
Applying contenttypes.0002_remove_content_type_name... OK
Applying auth.0002_alter_permission_name_max_length... OK
Applying auth.0003_alter_user_email_max_length... OK
Applying auth.0004_alter_user_username_opts... OK
Applying auth.0005_alter_user_last_login_null... OK
Applying auth.0006_require_contenttypes_0002... OK
Applying auth.0007_alter_validators_add_error_messages... OK
Applying auth.0008_alter_user_username_max_length... OK
Applying auth.0009_alter_user_last_name_max_length... OK
Applying sessions.0001_initial... OK
生成了5张表;book_authors生成的表;book表生成了一个publish_id字段;
注意事项:
id字段是自动添加的- 对于外键字段,Django 会在字段名上添加"_id" 来创建数据库中的列名 如 authordetail_id 、 publish_id 、book_id 、author_id
- 这个例子中的
CREATE TABLESQL 语句使用PostgreSQL 语法格式,要注意的是Django 会根据settings 中指定的数据库类型来使用相应的SQL 语句。 - 定义好模型之后,你需要告诉Django _使用_这些模型。你要做的就是修改配置文件中的INSTALL_APPSZ中设置,在其中添加
models.py所在应用的名称。 - 外键字段 ForeignKey 有一个 null=True 的设置(它允许外键接受空值 NULL),你可以赋给它空值 None 。
一对一就是oneToOneField;一对多就是ForeignKey;它俩是一样的,会在那张表里边多生成一个字段,加一个_id+一个约束关系;多对多就是ManyToManyField,会生成一个第三张关系表;
2.多表操作-添加
单表(没有任何关联字段)操作添加记录有两种一个是create,一个是obj.save(实例化来一个对象,用这个对象.sabe)
一对多添加记录(如果在有绑定关系的表中添加记录)
from django.shortcuts import render, HttpResponse # Create your views here.
from app01.models import *
def add(request):
#pub = Publish.objects.create(name="人民出版社", email="1234@123.com", city="北京") Publish是单表,可以直接生成一个出版社记录
###################绑定一对多的关系##############
#方式一:
#为book表绑定关系 和出版社的关系:book多----->publish
#book_obj = Book.objects.create(title="红楼梦", price=100, publishDate="2012-12-12", publish_id=1)
#print(book_obj.title, type(book_obj) ) #返回值book_obj就是添加记录的对象 打印 -- > 红楼梦 <class 'app01.models.Book'>
#book_obj.publishDate 、 book_obj.publish(拿到出版社对象<class 'app01.models.Publish'>)、 book_obj.publish_id(book_obj.publish.nid) 、 book_obj.publish.city
book_obj可以直接 .Book的字段;也可以.Publish里边的字段,先.出它的出版社对象再.它的字段
#方式二:
# pub_obj = Publish.objects.filter(nid=1).first() 查询id为1的出版社对象<class 'app01.models.Publish'>;不加first就是queryset的那个集合<class 'django.db.models.query.QuerySet'>
# book_obj = Book.objects.create(title="水浒传", price=100, publishDate="2012-12-12", publish=pub_obj) #publish就是book表里边的那个字段;
#让它等于publish的一个实例模型对象,赋值的时候pub_obj给了它一个对象;相当于它把上边第一种方式的翻译过来了
# print(book_obj.title) 打印它的title
# print(book_obj.price)
# print(book_obj.publishDate)
# print(book_obj.publish) #人民出版社; #拿到的就是出版社Publish对象,可以继续往后 . ;方式一的话是查到为id为1的出版社再赋给它 #它就是与这本书关联的出版社对象,一个书只有一个出版社对象;
##无论用方式一还是方式二创建都可以.publish或者.publish_id;
它打印出来是Publish object(1);在那张表中加上__str__(self)就显示name了,打印出来那个出版社看起来是字符串其实是个对象,可以继续在对象之前取.
#print(book_obj.publish.name) #与这本书关联的出版社对象,你可以.拿到这个出版社的任何字段 #(book_obj.publish.email)
# print(book_obj.publish_id) #就是那个1 #查询西游记的出版社对应的邮箱;
book_obj = Book.objects.filter(title="西游记").first() #先把这个书的对象取出来;
print(book_obj.publish.email) #先拿出一个对象找出它的关联对象,再去. publish为什么可以.出来,是因在赋值的时候已给它对象了,方式一或二都可以
return HttpResponse("ok")
多对多添加纪录
通过第三张表给它绑定两个作者;你没办法直接给这张表添加记录,数据库知道这张表叫什么,orm不知道这张表叫什么名字;django给我们提供了一个接口。
###############绑定多对多的关系######################
# book_obj = Book.objects.create(title="三国演义", price=100, publishDate="2012-12-12", publish_id=1)
#
# egon = Author.objects.get(name="egon") #把这两个作者找出来
# alex = Author.objects.get(name="alex")
# #绑定多对多的关系的API(找到这个字段) ##authors这个字段接受了ManyToManyField(to="Author")这个实例对象;给书籍对象添加作者 .authors就可以了
# book_obj.authors.add(egon, alex) #作者对象;book_obj为书籍对象,给它添加作者;它所要做的事情就是,找到book和author关联的那张表,在那张表中生成纪录;
#book_obj的id主键是3,egon是2,alex是1;这句话它去找到book_obj和author之间的关联表,然后去表中生成记录,3 1、3 2生成两条记录
# #book_obj.authors.add(1, 2, 3) #这里边放的是author的主键的id;这是另外一种简洁的形式,用4跟1拼一个,4跟2拼一个,4跟3,这样的三条记录;直接放author的主键。作者主键值;
# #book_obj.authors.add(*[1,2,3]) #跟上边的效果是等效的,*是在给函数传列表时等效位置参数加* #解出多对多关系
book = Book.objects.filter(nid=4).first() #查到nid=4,把这本书拿到查出来了;
# book.authors.remove(2) #加上1,2就把他们都删除了,删除4 1 、4 2;book的主键为4
##book.authors.remove(*[1,2]) #跟上边一样了 #book.authors.clear()#全部删除 #查询主键为4的书籍的所有作者的名字
print(book.authors.all()) #拿出来的是一个集合,所有的,注意与上边.publish的区别(与这本书关联的一个出版社对象)[obj1、obj2....]
<QuerySet [<Author:alex >]> queryset:与这本书关联的所有作者对象集合;列表里边套对象的格式;打印出<QuerySet [<Author: object(1)>]>;加上__str__就打印出了
ret = book.authors.all().values("name") <QuerySet [{'name':'alex'}]>
print(ret)
return HttpResponse("ok")
book_obj.publish book.authors.all() 两个最核心的知识点;一对一,一对多的字段,意味着这张表的实例对象,当它.publish的时候它就会.出与它关联的出版社对象;
当它.authors.all()的时候就会.出与它关联的作者集对象集合。
3.跨表查询
3.1基于对象(子查询)之跨表查询(会翻译成子查询)
一对多
def query(request):
'''
跨表查询:
1 基于对象查询;
2 基于双下划线查询;
3 聚合与分组查询
4 F 与 Q 查询
:param request:
:return:
'''
##########基于对象(就是先查出来拿到那个结果再去跨表去查到它相关的内容)的跨表查询(子查询)###########
'''
#一对多 正向按字段:publish
book多 --------------> publish 1
<--------------
反向按表名book_set.all() django封装的
'''
#一对多的正向查询(确定关联字段(属性)放在哪里放在哪张表里,book表和publish表的关联字段在book表里边)
#查询主键为1的书籍的出版社所在的城市
# book_obj = Book.objects.filter(nid=1).first() 拿到book对象
# print(book_obj.publish.city) '''
select publish_id from Book where nid=1;
select city from publish where nid=1
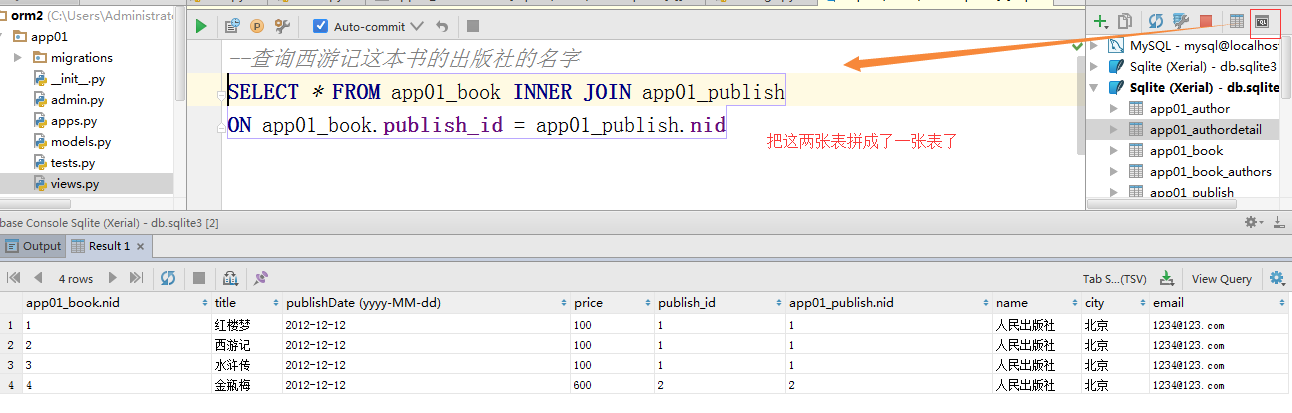
''' #一对多查询的正向查询:查询西游记这本书的出版社的名字
# book_obj = Book.objects.filter(title="西游记").first() #SELECT "app01_book"."nid", "app01_book"."title", "app01_book"."publishDate", "app01_book"."price", "app01_book"."read_num", "app01_book"."comment_num", "app01_book"."publish_id" FROM "app01_book" WHERE "app01_book"."title" = '西游记' ORDER BY "app01_book"."nid" ASC LIMIT 1; args=('西游记',)
#SELECT "app01_publish"."nid", "app01_publish"."name", "app01_publish"."city", "app01_publish"."email" FROM "app01_publish" WHERE "app01_publish"."nid" = 1; args=(1,)
# print(book_obj.publish) #与这本书关联的出版社对象 #人民出版社
# print(book_obj.publish.name) #人民出版社
#基于对象跨表查询的sql语句
#select publish_id from Book where title='西游记'
#select name from Publish where id=1 #一对多查询的反向查询:查询人民出版社出版过的书籍名称
# publish = Publish.objects.filter(name='人民出版社').first()
# ret = publish.book_set.all()
# print(ret) #Queryset里边放对象 <QuerySet [<Book: 红楼梦>, <Book: 西游记>, <Book: 水浒传>]> # for obj in publish.book_set.all():
# print(obj.title) #打印出了关联书籍的名字
多对多
#多对多查询
'''
#多对多 按字段authors
book -----------------------> author
<----------------------
按表名book_set.all()
'''
#正向查询
#查询水浒传所有作者的名字
book_obj = Book.objects.filter(title="水浒传").first()
#SELECT "app01_book"."nid", "app01_book"."title", "app01_book"."publishDate", "app01_book"."price", "app01_book"."read_num", "app01_book"."comment_num", "app01_book"."publish_id" FROM "app01_book" WHERE "app01_book"."title" = '水浒传' ORDER BY "app01_book"."nid" ASC LIMIT 1; args=('水浒传',)
# SELECT "app01_author"."nid", "app01_author"."name", "app01_author"."age", "app01_author"."authordetail_id" FROM "app01_author" INNER JOIN "app01_book_authors" ON ("app01_author"."nid" = "app01_book_authors"."author_id") WHERE "app01_book_authors"."book_id" = 3;
author_list = book_obj.authors.all() #queryset对象<QuerySet []> [author_obj1,...]
for author in author_list:
print(author.name) #alex egon #反向查询
#alex出版过的所有书籍名称
# alex = Author.objects.filter(name="alex").first()
# book_list = alex.book_set.all()
# for book in book_list:
# print(book.title) #金瓶、水浒传
一对一
#############一对一查询(只是多了个unique)
'''
#一对一 按字段(关联字段):authordetail
author --------------> authordetail
<--------------
按表名author
'''
##############正向查询:查询alex的手机号 alex = Author.objects.filter(name="alex").first() #拿到作者对象
# SELECT "app01_author"."nid", "app01_author"."name", "app01_author"."age", "app01_author"."authordetail_id" FROM "app01_author" WHERE "app01_author"."name" = 'alex' ORDER BY "app01_author"."nid" ASC LIMIT 1; args=('alex',)
# SELECT "app01_authordetail"."nid", "app01_authordetail"."birthday", "app01_authordetail"."telephone", "app01_authordetail"."addr" FROM "app01_authordetail" WHERE "app01_authordetail"."nid" = 1; args=(1,)
print(alex.authordetail.telephone) #1867889 找出它的关联对象.authordetail #反向查询#查询手机号为911的的作者的名字和年龄
ad = AuthorDetail.objects.filter(telephone=911).first() #AuthorDetail对象
#SELECT "app01_authordetail"."nid", "app01_authordetail"."birthday", "app01_authordetail"."telephone", "app01_authordetail"."addr" FROM "app01_authordetail" WHERE "app01_authordetail"."telephone" = 911 ORDER BY "app01_authordetail"."nid" ASC LIMIT 1; args=(911,)
#SELECT "app01_author"."nid", "app01_author"."name", "app01_author"."age", "app01_author"."authordetail_id" FROM "app01_author" WHERE "app01_author"."authordetail_id" = 2; args=(2,)
print(ad.author.name) #egon #找它的关联对象,反向查询直接用表名author表
print(ad.author.age) #
3.2 基于queryset双下划线的跨表查询(对应翻译的sql语句是join)(会翻译成join查询)
Django 还提供了一种直观而高效的方式在查询(lookups)中表示关联关系,它能自动确认 SQL JOIN 联系。要做跨关系查询,就使用两个下划线来链接模型(model)间关联字段的名称,直到最终链接到你想要的 model 为止。
关键点:正向查询按字段,反向查询按表名。
####################################基于双下划线的跨表查询(join查询)#########################
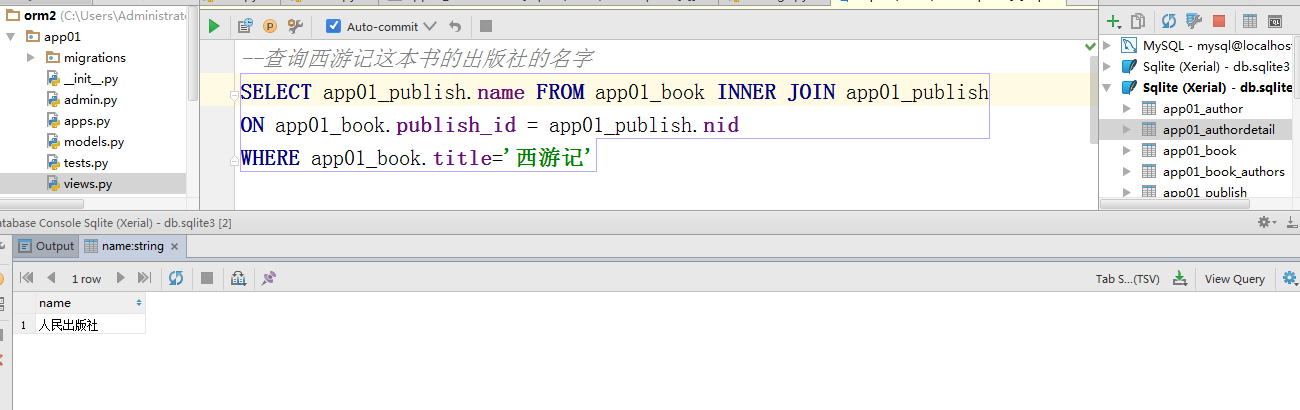
###############一对多查询的正向查询:查询西游记这本书的出版社名字
'''
正向查询按字段,反向查询按表名小写 用来告诉ORM引擎join哪张表
'''
#方式一
ret = Book.objects.filter(title='西游记').values('publish__name') #values(publish)就相当于join另外一张表,但这里按orm的规则是不能写表名,写字段,然后再去__它的字段
# SELECT "app01_publish"."name" FROM "app01_book" INNER JOIN "app01_publish" ON ("app01_book"."publish_id" = "app01_publish"."nid") WHERE "app01_book"."title" = '西游记' LIMIT 21;
print(ret) #<QuerySet [{'publish__name': '人民出版社'}]>
#方式二 这两种方式所对应sql语句是一样的
ret = Publish.objects.filter(book__title='西游记').values("name")
# SELECT "app01_publish"."name" FROM "app01_publish" INNER JOIN "app01_book" ON ("app01_publish"."nid" = "app01_book"."publish_id") WHERE "app01_book"."title" = '西游记' LIMIT 21;
print(ret) #<QuerySet [{'name': '人民出版社'}]>
# 练习1: 查询苹果出版社出版过的所有书籍的名字与价格(一对多) #以谁为基表以谁为左表都可以;
ret=Publish.objects.filter(name="人民出版社").values("book__title","book__price") #publish为左表,出版社去找书籍是反向查询;
ret=Book.objects.filter(publish__name="人民出版社").values("title","price") #以book为左表,显示它的values它的字段
print(ret)
'''依次对应上边的Book和Publish;这两种方式翻译成sql语句都一样
SELECT * FROM "app01_book" INNER JOIN "app01_publish" ON ("app01_book"."publish_id" = "app01_publish"."nid") WHERE "app01_publish"."name" = '人民出版社' LIMIT 21; args=('人民出版社',)
SELECT * FROM "app01_publish" LEFT OUTER JOIN "app01_book" ON ("app01_publish"."nid" = "app01_book"."publish_id") WHERE "app01_publish"."name" = '人民出版社' LIMIT 21; args=('人民出版社',)
'''
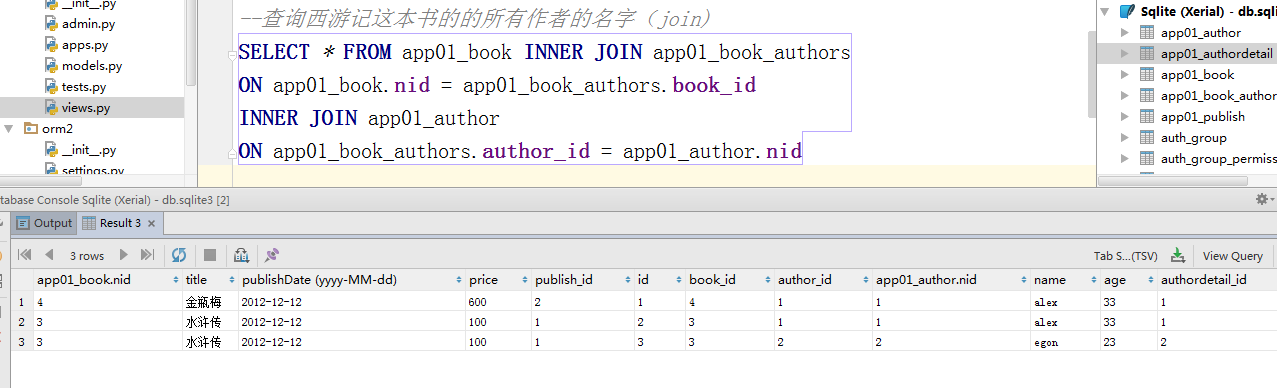
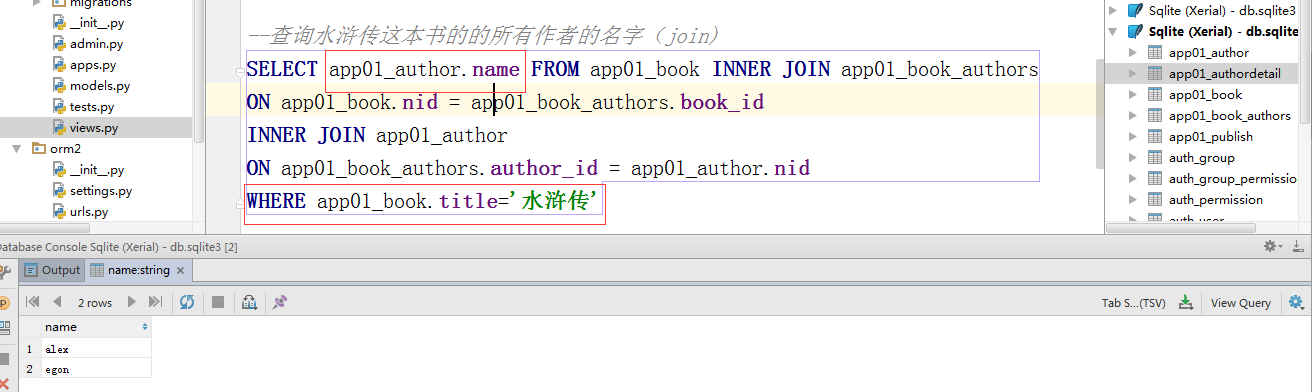
#####################多对多:查询水浒传这本书的的所有作者的名字(join)
# 方式一 #多对多的字段相当于跨了2张表;foreignkey跨了1张表
#需求:通过Book(基表)表join与其关联的Author表,属于正向查询:按字段authors通知ORM引擎join book_authors与author;Book表通过它下面那个authors字段去关联Author表
ret = Book.objects.filter(title='水浒传').values('authors__name')
# SELECT "app01_author"."name" FROM "app01_book" LEFT OUTER JOIN "app01_book_authors" ON ("app01_book"."nid" = "app01_book_authors"."book_id") LEFT OUTER JOIN "app01_author" ON ("app01_book_authors"."author_id" = "app01_author"."nid") WHERE "app01_book"."title" = '水浒传' LIMIT 21; args=('水浒传',)
print(ret)#<QuerySet [{'authors__name': 'alex'}, {'authors__name': 'egon'}]>
#方式二
#需求:通过Author表join与其关联的Book表,属于反向查询:按表名小写book通知ORM引擎join book_authors与book表
ret = Author.objects.filter(book__title='水浒传').values('name')
# SELECT "app01_author"."name" FROM "app01_author" INNER JOIN "app01_book_authors" ON ("app01_author"."nid" = "app01_book_authors"."author_id") INNER JOIN "app01_book" ON ("app01_book_authors"."book_id" = "app01_book"."nid") WHERE "app01_book"."title" = '水浒传' LIMIT 21; args=('水浒传',)
print(ret) #<QuerySet [{'name': 'alex'}, {'name': 'egon'}]>
# 练习2: 查询alex出过的所有书籍的名字(多对多)
ret = Author.objects.filter(name="alex").values("book__title") #跨表查询 正向
ret = Book.objects.filter(authors__name="alex").values("title") # 正向按字段,反向按表名 # 练习3: 查询人民出版社出版过的所有书籍的名字以及作者的姓名
ret = Book.objects.filter(publish__name="人民出版社").values("title", "authors__name") #只要不是这张表自己提供的就需要跨表 # 练习4: 手机号以151开头的作者出版过的所有书籍名称以及出版社名称 #用哪张表作为基表都可以的
Book.objects.filter(authors__authordetail__telephone="151").values("title", "publish__title") ##因为Book表只跟authors表有关联,所以最开始前边应加上这个;book表通过关系表跨到authors表 return HttpResponse("ok")
#一对一查询:查询alex的手机号
#方式一:
# 需求:通过Author表join与其关联的AuthorDetail表,属于正向查询:按字段authordetail通知ORM引擎join Authordetail表
ret = Author.objects.filter(name='alex').values('authordetail__telephone')
# SELECT "app01_authordetail"."telephone" FROM "app01_author" INNER JOIN "app01_authordetail" ON ("app01_author"."authordetail_id" = "app01_authordetail"."nid") WHERE "app01_author"."name" = 'alex' LIMIT 21; args=('alex',)
print(ret) #<QuerySet [{'authordetail__telephone': 1867889}]> #方式二:
# 需求:通过AuthorDetail表join与其关联的Author表,属于反向查询:按表名小写author通知ORM引擎join Author
ret = AuthorDetail.objects.filter(author__name='alex').values('telephone')
# SELECT "app01_authordetail"."telephone" FROM "app01_authordetail" INNER JOIN "app01_author" ON ("app01_authordetail"."nid" = "app01_author"."authordetail_id") WHERE "app01_author"."name" = 'alex' LIMIT 21; args=('alex',)
print(ret) #<QuerySet [{'telephone': 1867889}]>
#############进阶练习
#练习:手机号以186开头的作者出版过的所有书籍名称以及书籍出版社名称
#方式一
#需求通过Book表join AuthorDetail表,Book与AuthorDetail无关联,所以必须连续跨表
ret = Book.objects.filter(authors__authordetail__telephone__startswith = '').values('title','publish__name')
# SELECT "app01_book"."title", "app01_publish"."name" FROM "app01_book" INNER JOIN "app01_book_authors" ON ("app01_book"."nid" = "app01_book_authors"."book_id")
# INNER JOIN "app01_author" ON ("app01_book_authors"."author_id" = "app01_author"."nid")
# INNER JOIN "app01_authordetail" ON ("app01_author"."authordetail_id" = "app01_authordetail"."nid") INNER JOIN "app01_publish" ON ("app01_book"."publish_id" = "app01_publish"."nid")
# WHERE "app01_authordetail"."telephone" LIKE '186%' ESCAPE '\' LIMIT 21; args=('186%',)
print(ret) #<QuerySet [{'title': '金瓶', 'publish__name': '人民出版社'}, {'title': '水浒传', 'publish__name': '人民出版社'}]>
# 方式二:
ret = Author.objects.filter(authordetail__telephone__startswith='').values('book__title','book__publish__name')
# SELECT "app01_book"."title", "app01_publish"."name" FROM "app01_author" INNER JOIN "app01_authordetail" ON ("app01_author"."authordetail_id" = "app01_authordetail"."nid")
# LEFT OUTER JOIN "app01_book_authors" ON ("app01_author"."nid" = "app01_book_authors"."author_id")
# LEFT OUTER JOIN "app01_book" ON ("app01_book_authors"."book_id" = "app01_book"."nid")
# LEFT OUTER JOIN "app01_publish" ON ("app01_book"."publish_id" = "app01_publish"."nid") WHERE "app01_authordetail"."telephone" LIKE '186%' ESCAPE '\' LIMIT 21; args=('186%',)
print(ret) #<QuerySet [{'book__title': '金瓶', 'book__publish__name': '人民出版社'}, {'book__title': '水浒传', 'book__publish__name': '人民出版社'}]>
3.3 聚合查询和分组查询
#############聚合与分组查询############
#######聚合 aggregate(聚合统计函数);返回值是一个字典,不再是queryset
# 计算所有图书的平均价格
from django.db.models import Avg,Max,Min,Count #aggregate是聚合组件
ret = Book.objects.all().aggregate(avg__price=Avg("price"),max_price=Max("price")) #{'price__avg': 100.0}
#SELECT AVG("app01_book"."price") AS "avg__price", CAST(MAX("app01_book"."price") AS NUMERIC) AS "max_price" FROM "app01_book"; args=()
print(ret) #{'avg__price': 225.0, 'max_price': Decimal('600.00')}
models.py(增加一个emp表)
class Emp(models.Model):
name=models.CharField(max_length=32)
age=models.IntegerField()
salary=models.DecimalField(max_digits=8,decimal_places=2)
dep=models.CharField(max_length=32)
province=models.CharField(max_length=32)
##########分组查询 annotate(分组查询里的统计函数) ,返回值依然是queryset
#单表分组查询
#示例一:
#查询每一个部门的名称以及员工的平均薪水
#select dep,Avg(salary) from emp group by dep
# ret = Emp.objects.values("dep").annotate(avg_salary=Avg('salary'))
# SELECT "app01_emp"."dep", AVG("app01_emp"."salary") AS "avg_salary" FROM "app01_emp" GROUP BY "app01_emp"."dep" LIMIT 21; args=()
# print(ret)#<QuerySet [{'dep': '保安部', 'avg_salary': 5000.0}, {'dep': '教学部', 'avg_salary': 2000.0}]>
#单表分组查询的ORM语法:单表模型 .objects.values("group by的字段").annotate(聚合函数('统计字段'))
#示例二:
#查询每一个省份的名称以及员工数
ret = Emp.objects.values("province").annotate(c = Count('id'))
# SELECT "app01_emp"."province", COUNT("app01_emp"."id") AS "c" FROM "app01_emp" GROUP BY "app01_emp"."province" LIMIT 21; args=()
print(ret) #<QuerySet [{'province': '山东省', 'c': 2}, {'province': '河北省', 'c': 1}]> from django.db.models import Avg,Count,Max
#统计每本书的作者个数
# ret = Book.objects.all().annotate(c=Count("authors__name")) #它会把前边查出来的每一个对象进行分组统计,每一个对象就是一个组,统计每一个对象对应的作者的个数;涉及到关联的作者正向查询按字段反向按表名
# print(ret)
# for obj in ret:
# print(obj.title,obj.c)
#<QuerySet [<Book: 红楼梦>, <Book: 西游记>, <Book: 水浒传>, <Book: 三国>]>
# 红楼梦 0
# 西游记 0
# 水浒传 0
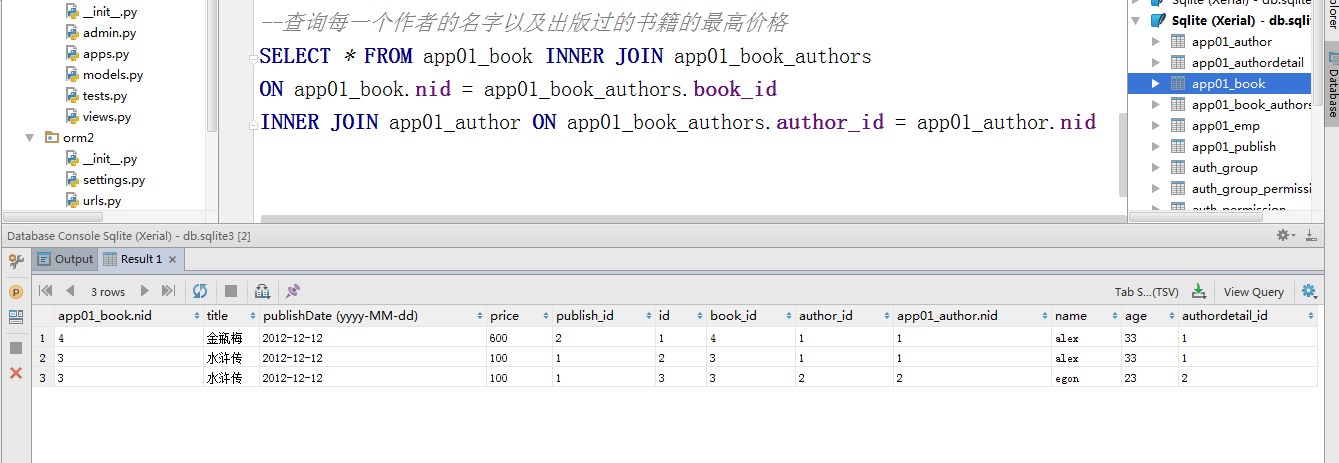
# 三国 1 #统计每一个作者出版过的书籍最高价格
# ret=Author.objects.all().annotate(max_price=Max("book__price")) #通过Authors表去找它关联的书籍的价格,authors找书籍是反向查询 用表名
# for obj in ret:
# print(obj.name, obj.max_price)
#alex 600.00
#egon 100.00 #每一个出版社出版过的书籍的平均价格
ret = Publish.objects.all().annotate(avg_price=Avg("book__price")).values("name", "avg_price") #publish关联的那个书籍,反向查询用表名;values每个出版社的名字、平均价格
print(ret) #<QuerySet [{'name': '人民出版社', 'avg_price': 100.0}, {'name': '人民出版社', 'avg_price': 600.0}]>
return HttpResponse("ok") #补充知识点:
ret = Emp.objects.all()
# SELECT "app01_emp"."id", "app01_emp"."name", "app01_emp"."age", "app01_emp"."salary", "app01_emp"."dep", "app01_emp"."province" FROM "app01_emp" LIMIT 21; args=()
print(ret) #select * from emp; <QuerySet [<Emp: Emp object (1)>, <Emp: Emp object (2)>, <Emp: Emp object (3)>]> ret = Emp.objects.values("name")
# SELECT "app01_emp"."name" FROM "app01_emp"
print(ret) #select name from emp; <QuerySet [{'name': 'alex'}, {'name': 'egon'}, {'name': 'yuan'}]>
# Emp.objects.all().annotate(avg_salary=Avg("salary")) #在单表分组下,按着主键进行group by 是没有任何意义的;统计出来都是每一个是一组 #########多表(跨表)分组查询
# 示例一查询每一个出版社的名称以及出版的书籍个数
ret = Publish.objects.values("nid").annotate(c=Count("book__title")) #反向查询
# SELECT "app01_publish"."nid", COUNT("app01_book"."title") AS "c" FROM "app01_publish" LEFT OUTER JOIN "app01_book" ON ("app01_publish"."nid" = "app01_book"."publish_id") GROUP BY "app01_publish"."nid"
print(ret) #<QuerySet [{'nid': 1, 'c': 3}, {'nid': 2, 'c': 1}]> ret = Publish.objects.values("nid").annotate(c=Count("book__title")).values("name","c")
# SELECT "app01_publish"."name", COUNT("app01_book"."title") AS "c" FROM "app01_publish" LEFT OUTER JOIN "app01_book" ON ("app01_publish"."nid" = "app01_book"."publish_id") GROUP BY "app01_publish"."nid", "app01_publish"."name"
print(ret) #<QuerySet [{'name': '人民出版社', 'c': 3}, {'name': '南京出版社', 'c': 1}]> ret = Publish.objects.values("name").annotate(c=Count("book__title"))
# SELECT "app01_publish"."name", COUNT("app01_book"."title") AS "c" FROM "app01_publish" LEFT OUTER JOIN "app01_book" ON ("app01_publish"."nid" = "app01_book"."publish_id") GROUP BY "app01_publish"."name" LIMIT 21;
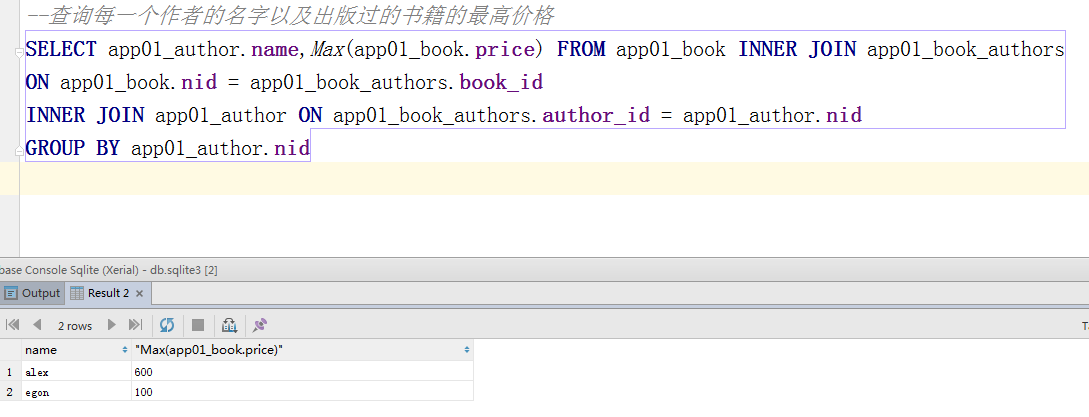
print(ret) #<QuerySet [{'name': '人民出版社', 'c': 3}, {'name': '南京出版社', 'c': 1}]> # 示例二查询每一个作者的名字以及出版过的书籍的最高价格
ret = Author.objects.values('pk').annotate(max_price=Max("book__price")).values("name","max_price")
# SELECT "app01_author"."name", CAST(MAX("app01_book"."price") AS NUMERIC) AS "max_price" FROM "app01_author"
# LEFT OUTER JOIN "app01_book_authors" ON ("app01_author"."nid" = "app01_book_authors"."author_id")
# LEFT OUTER JOIN "app01_book" ON ("app01_book_authors"."book_id" = "app01_book"."nid")
# GROUP BY "app01_author"."nid", "app01_author"."name" LIMIT 21;
print(ret) #<QuerySet [{'name': 'alex', 'max_price': Decimal('600.00')}, {'name': 'egon', 'max_price': Decimal('100.00')}]>
#总结跨表的分组查询的模型:
#每一个后表模型.objects.values("pk").annotate(聚合函数(关联表__统计字段))
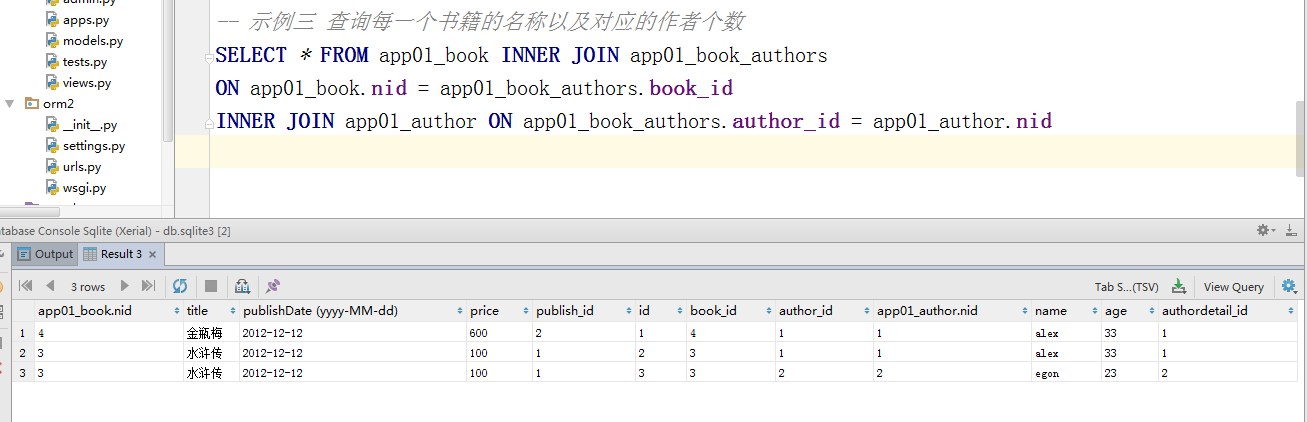
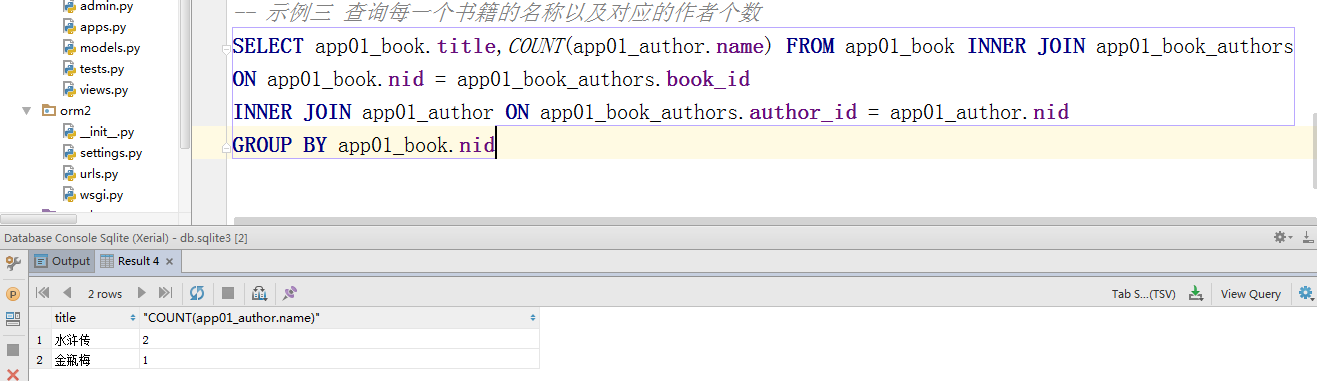
#示例三 查询每一个书籍的名称以及对应的作者个数
ret = Book.objects.values('pk').annotate(c=Count("authors__name")).values("title","c")
# SELECT "app01_book"."title", COUNT("app01_author"."name") AS "c" FROM "app01_book" LEFT OUTER JOIN "app01_book_authors" ON ("app01_book"."nid" = "app01_book_authors"."book_id") LEFT OUTER JOIN "app01_author" ON ("app01_book_authors"."author_id" = "app01_author"."nid") GROUP BY "app01_book"."nid", "app01_book"."title" LIMIT 21;
print(ret) #<QuerySet [{'title': '红楼梦', 'c': 0}, {'title': '西游记', 'c': 0}, {'title': '水浒传', 'c': 2}, {'title': '金瓶', 'c': 1}]> ####################跨表分组查询的另一种玩法
ret = Publish.objects.values("nid").annotate(c=Count("book__title")).values("name","email","c")
#SELECT "app01_publish"."name", "app01_publish"."email", COUNT("app01_book"."title") AS "c" FROM "app01_publish" LEFT OUTER JOIN "app01_book" ON ("app01_publish"."nid" = "app01_book"."publish_id") GROUP BY "app01_publish"."nid", "app01_publish"."name", "app01_publish"."email" LIMIT 21;
print(ret)#<QuerySet [{'name': '人民出版社', 'email': '1234@123.com', 'c': 3}, {'name': '南京出版社', 'email': '345@163.com', 'c': 1}]>
ret = Publish.objects.all().annotate(c=Count("book__title")).values("name","c","city")
# SELECT "app01_publish"."name", "app01_publish"."city", COUNT("app01_book"."title") AS "c" FROM "app01_publish" LEFT OUTER JOIN "app01_book" ON ("app01_publish"."nid" = "app01_book"."publish_id") GROUP BY "app01_publish"."nid", "app01_publish"."name", "app01_publish"."city", "app01_publish"."email" LIMIT 21;
#ret = Publish.objects.annotate(c=Count("book__title")).values("name","c","city")跟上边完全等效的
print(ret) #按每一个字段进行分组;annotate(c=Count("book__titile"))统计完只显示对象;
#<QuerySet [{'name': '人民出版社', 'city': '北京', 'c': 3}, {'name': '南京出版社', 'city': '南京', 'c': 1}]> ######练习###########
#统计每一本以py开头的书籍的作者个数:
#每一个后的表模型.objects.values("pk").annotate(聚合函数(关联表__统计字段)).values("表模型的所有字段以及统计字段")
ret = Book.objects.filter(title__startswith="py").values("pk").annotate(c=Count("authors__name")).values("title","c")
# SELECT "app01_book"."title", COUNT("app01_author"."name") AS "c" FROM "app01_book" LEFT OUTER JOIN "app01_book_authors" ON ("app01_book"."nid" = "app01_book_authors"."book_id") LEFT OUTER JOIN "app01_author" ON ("app01_book_authors"."author_id" = "app01_author"."nid") WHERE "app01_book"."title" LIKE 'py%' ESCAPE '\' GROUP BY "app01_book"."nid", "app01_book"."title" LIMIT 21;
print(ret) #<QuerySet [{'title': 'PYTHON全栈', 'c': 0}]>
#统计不止一个作者的图书
ret = Book.objects.values("pk").annotate(c=Count("authors__name")).filter(c__gt=1).values("title","c")
# SELECT "app01_book"."title", COUNT("app01_author"."name") AS "c" FROM "app01_book" LEFT OUTER JOIN "app01_book_authors" ON ("app01_book"."nid" = "app01_book_authors"."book_id") LEFT OUTER JOIN "app01_author" ON ("app01_book_authors"."author_id" = "app01_author"."nid") GROUP BY "app01_book"."nid", "app01_book"."title" HAVING COUNT("app01_author"."name") > 1 LIMIT 21;
print(ret) #<QuerySet [{'title': '水浒传', 'c': 2}]>
3.4 F查询和Q查询
http://www.cnblogs.com/yuanchenqi/articles/8963244.html
#######F查询和Q查询##########
from django.db.models import F
ret = Book.objects.filter(comment_num__gt=F("read_num"))
# SELECT "app01_book"."nid", "app01_book"."title", "app01_book"."publishDate", "app01_book"."price", "app01_book"."read_num", "app01_book"."comment_num", "app01_book"."publish_id" FROM "app01_book" WHERE "app01_book"."comment_num" > ("app01_book"."read_num") LIMIT 21;
print(ret) #<QuerySet [<Book: 红楼梦>, <Book: 金瓶>]>
# Book.objects.all().update(price=F("price")+1) #UPDATE "app01_book" SET "price" = CAST(("app01_book"."price" + 1) AS NUMERIC); from django.db.models import F,Q
# ret = Book.objects.filter(title="红楼梦",price=101) # SELECT "app01_book"."nid", "app01_book"."title", "app01_book"."publishDate", "app01_book"."price", "app01_book"."read_num", "app01_book"."comment_num", "app01_book"."publish_id" FROM "app01_book" WHERE ("app01_book"."title" = '红楼梦' AND "app01_book"."price" = '101') LIMIT 21;
ret = Book.objects.filter(Q(title="红楼梦")| Q(price=101)) #如果是且就加&;或加| #SELECT "app01_book"."nid", "app01_book"."title", "app01_book"."publishDate", "app01_book"."price", "app01_book"."read_num", "app01_book"."comment_num", "app01_book"."publish_id" FROM "app01_book" WHERE ("app01_book"."title" = '红楼梦' OR "app01_book"."price" = '101') LIMIT 21; args=('红楼梦', Decimal('101'))
print(ret) #<QuerySet [<Book: 红楼梦>]>
# ret = Book.objects.filter((Q(title="红楼梦")& Q(price=101))|Q()) #ret = Book.objects.filter(~ Q(title="红楼梦") | Q(price=101)) #SELECT "app01_book"."nid", "app01_book"."title", "app01_book"."publishDate", "app01_book"."price", "app01_book"."read_num", "app01_book"."comment_num", "app01_book"."publish_id" FROM "app01_book" WHERE (NOT ("app01_book"."title" = '红楼梦') OR "app01_book"."price" = '101') LIMIT 21; args=('红楼梦', Decimal('101'))
ret = Book.objects.filter(~Q(title='红楼梦')|Q(price=101),comment_num__gt=100) #Q完了再放键值对,得有个顺序,这样语法才支持
# SELECT "app01_book"."nid", "app01_book"."title", "app01_book"."publishDate", "app01_book"."price", "app01_book"."read_num", "app01_book"."comment_num", "app01_book"."publish_id" FROM "app01_book" WHERE ((NOT ("app01_book"."title" = '红楼梦') OR "app01_book"."price" = '101') AND "app01_book"."comment_num" > 100) LIMIT 21; args=('红楼梦', Decimal('101'), 100)
print(ret) #<QuerySet [<Book: 西游记>, <Book: 金瓶>]> return HttpResponse('OK')
4. 总结:
'''
A-B
关联属性在A表中
正向查询:A ----> B
反向查询:B ----> A
#一对多 正向查询:按字段publish
反向查询:表名小写_set.all()
book_obj.publish
book多(关联属性publish)--------------> publish 1
<----------------
publish_obj.book_set.all() #queryset
反向按表名book_set.all() django封装的 #多对多 正向查询:按字段
反向查询:表名小写_set.all()
book_obj.authors.all()
Book(关联属性:authors)对象--------------> Author对象
<--------------
author_obj.book_set.all() #queryset
#一对一 正向查询:按字段
反向查询:表名小写_set.all()
authors.authordetail
Author(关联属性:authordetail)对象--------------> Authordetail对象
<--------------
authordetail.author #queryset
基于双下划线的跨表查询(join查询)
key:正向查询按字段,反向查询按表名小写 单表的分组查询:
查询每一个部门名称以及对应的员工数
emp:
id name age salary dep
1 alex 12 2000 销售部
2 egon 22 3000 人事部
3 wen 22 5000 人事部
sql语句:
select dep,Count(*) from emp group by dep;
思考:如何用ORM语法进行分组查询:
#单表分组查询的ORM语法:单表模型 .objects.values("group by的字段").annotate(聚合函数('统计字段'))
在单表分组下,按着主键进行group by 是没有任何意义的
ORM:
emp.objects.values("dep").annotate(c=Count("id") 跨表的分组查询
Book表
id title date price publish_id
1 红楼梦 2012-12-12 100 1
2 西游记 2012-12-12 100 1
3 水浒传 2012-12-12 100 1
4 金瓶 2012-12-12 600 2
Publish表
id name city email
1 人民出版社 北京 1234@123.com
2 南京出版社 南京 345@163.com
查询每一个出版社出版的书籍个数
Book.objects.values("publish_id").annotate(Count("id"))
查询每一个出版社的名称以及出版的书籍个数
join sql: select * from Book inner join Publish on book.publish_id=publish.id
id title date price publish_id publish.id publish.name publish.addr publish.email
1 红楼梦 2012-12-12 100 1 1 人民出版社 北京 123@qq.com
2 西游记 2012-12-12 100 1 1 人民出版社 北京 123@qq.com
3 水浒传 2012-12-12 100 1 1 人民出版社 北京 123@qq.com
4 金瓶 2012-12-12 600 2 2 南京出版社 南京 456@163.com
分组查询的sql:
select publish.name,Count("title") from Book inner join Publish on book.publish_id=publish.id
group by publish.id
如何用ORM语法进行跨表分组查询
示例二查询每一个作者的名字以及出版过的书籍的最高价格
ret = Author.objects.values('pk').annotate(max_price=Max("book__price")).values("name","max_price")
示例三 查询每一个书籍的名称以及对应的作者个数
ret = Book.objects.values('pk').annotate(c=Count("authors__name")).values("title","c")
总结跨表的分组查询的模型:
#每一个后的表模型.objects.values("pk").annotate(聚合函数(关联表__统计字段)).values("表模型的所有字段以及统计字段")
每一个后的表模型.objects.annotate(聚合函数(关联表__统计字段)).values("表模型的所有字段以及统计字段")
'''
5.Django|模型层--多表关系的更多相关文章
- Python之路【第三十篇】:django 模型层-多表关系
多表操作 文件为 ----> orm2 数据库表关系之关联字段与外键约束 一对多Book id title price publish email addr 1 php 100 人民出版社 1 ...
- Django模型层-单表操作
ORM介绍 MVC或者MVC框架中包括一个重要的部分,就是ORM,它实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库,这极大的减轻了开发人员的 ...
- Django之django模型层一单表操作
一 ORM简介 MVC或者MVC框架中包括一个重要的部分,就是ORM,它实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库,这极大的减轻了开发人 ...
- Django 模型层--单表
ORM 简介 MTV或者MVC框架中包括一个重要的部分,就是ORM,它实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库,这可以大大的减少了开 ...
- Django模型层-多表操作
多表操作 一.创建模型 实例:我们来假定下面这些概念,字段和关系 作者模型:一个作者有姓名和年龄. 作者详细模型:把作者的详情放到详情表,包含生日,手机号,家庭住址等信息.作者详情模型和作者模型之间是 ...
- Django模型层(各种表及表数据的操作)
目录 一.Django模型层 0. django模型层的级联关系 1. 配置django测试脚本 (1)方式一 (2)方式二 2. orm表数据的两种增删改 (1)方式一: (2)方式二: 3. pk ...
- {django模型层(二)多表操作}一 创建模型 二 添加表记录 三 基于对象的跨表查询 四 基于双下划线的跨表查询 五 聚合查询、分组查询、F查询和Q查询
Django基础五之django模型层(二)多表操作 本节目录 一 创建模型 二 添加表记录 三 基于对象的跨表查询 四 基于双下划线的跨表查询 五 聚合查询.分组查询.F查询和Q查询 六 xxx 七 ...
- Django模型层之单表操作
Django模型层之单表操作 一 .ORM简介 我们在使用Django框架开发web应用的过程中,不可避免地会涉及到数据的管理操作(如增.删.改.查),而一旦谈到数据的管理操作,就需要用到数据库管理软 ...
- 第五章、Django之模型层----多表查询
目录 第五章.Django之模型层----多表查询 一.一对多字段增删改查 1.增 2.查 3.改 4. 删除 二.多对多的增删改查 1. 增 2. 改 3. 删 三.ORM跨表查询 四.正反向的概念 ...
随机推荐
- mongoDB - 日常操作三
MongoDB 进程控制 进程控制 db.currentOp() # 查看活动进程 db.$cmd.sys.inprog.findOne() # 查看活动进程 与上面一样 opid # 操作进程号 o ...
- MySQL指令
在mysql里:文件夹就是数据库 文件就是表 创建用户: 格式:create user '用户名'@'IP地址' identified by '密码'; 说明:IP地址是用来限制用户只能在哪 ...
- luogu P1445 [Violet]嘤F♂A
博主决定更博文啦 这道题一开始没什么思路啊qwq 要求 \(\frac{1}{x}+\frac{1}{y}=\frac{1}{n!}\) 的正整数解总数 首先通分,得 \[\frac{x+y}{xy} ...
- 有关ACM学习的博客链接
大综合: 杭电OJ水题大全题解:http://blog.csdn.net/ysc504?viewmode=contents 14级浙江财经大学大佬:http://blog.csdn.net/jtjy5 ...
- SpringMVC——SpringMVC简介
Spring web mvc 和Struts2 都属于表现层的框架,它是Spring 框架的一部分,我们可以从Spring 的整体结构中看得出来:
- springMVC入门(一)
1. SpringMVC入门 1.1SpringMVC是什么 Spring web mvc和Struts2都属于表现层的框架,它是Spring框架的一部分,我们可以从Spring的整体结构中看得出 ...
- ES系列十一、ES的index、store、_source、copy_to和all的区别
1.基本概念 1.1._source 存储的原始数据._source中的内容就是搜索api返回的内容,如: { "query":{ "term":{ &q ...
- Visual Studio 2017 + Python3.6安装scipy库
Windows10下安装scipy很麻烦,直接在命令行下使用pip install scipy无法安装,但可以借助VS2017的集成环境来安装. (1)首先在Visual Studio Install ...
- windows系统上搭建redis集群哨兵及主从复制
搭建master 修改redis配置redis.windows.conf: 修改监听端口: port 26379 修改绑定IP: bind 127.0.0.1 添加redis日志:logfile & ...
- OA系统高性能解决方案(史上最全的通达OA系统优化方案)
序: 这是一篇针对通达OA系统的整体优化方案,文档将硬件.网络.linux操作系统.程序本身(包括web和数据库)以及现有业务有效结合在一起,进行了系统的整合优化.该方案应用于真实生产环境,部署完成后 ...