Annoy 近邻算法
Annoy
随机选择两个点,以这两个节点为初始中心节点,执行聚类数为2的kmeans过程,最终产生收敛后两个聚类中心点
二叉树底层是叶子节点记录原始数据节点,其他中间节点记录的是分割超平面的信息


但是上述描述存在两个问题:
(1)查询过程最终落到叶子节点的数据节点数小于 我们需要的Top N相似邻居节点数目怎么办?
(2)两个相近的数据节点划分到二叉树不同分支上怎么办?
针对这个问题可以通过两个方法来解决:
(1)如果分割超平面的两边都很相似,那可以两边都遍历
(2) 建立多棵二叉树树,构成一个森林
(3)所有树返回近邻点都插入到优先队列中,求并集去重, 然后计算和查询点距离, 最终根据距离值从近距离到远距离排序, 返回Top N近邻节点集合
Summary of features
- Euclidean distance, Manhattan distance, cosine distance, Hamming distance, or Dot (Inner) Product distance
- Cosine distance is equivalent to Euclidean distance of normalized vectors = sqrt(2-2*cos(u, v))
- Works better if you don't have too many dimensions (like <100) but seems to perform surprisingly well even up to 1,000 dimensions
- Small memory usage
- Lets you share memory between multiple processes
- Index creation is separate from lookup (in particular you can not add more items once the tree has been created)
- Native Python support, tested with 2.7, 3.6, and 3.7.
- Build index on disk to enable indexing big datasets that won't fit into memory (contributed by Rene Hollander)
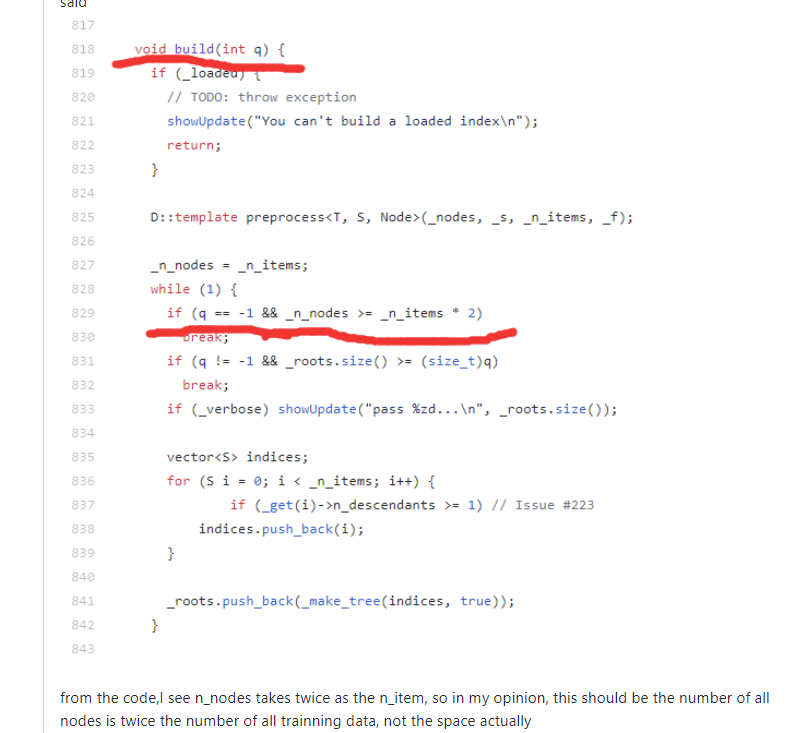
build(-1)的树的颗数问题
:所有节点的个数是trainning data的2倍左右:https://github.com/spotify/annoy/issues/338
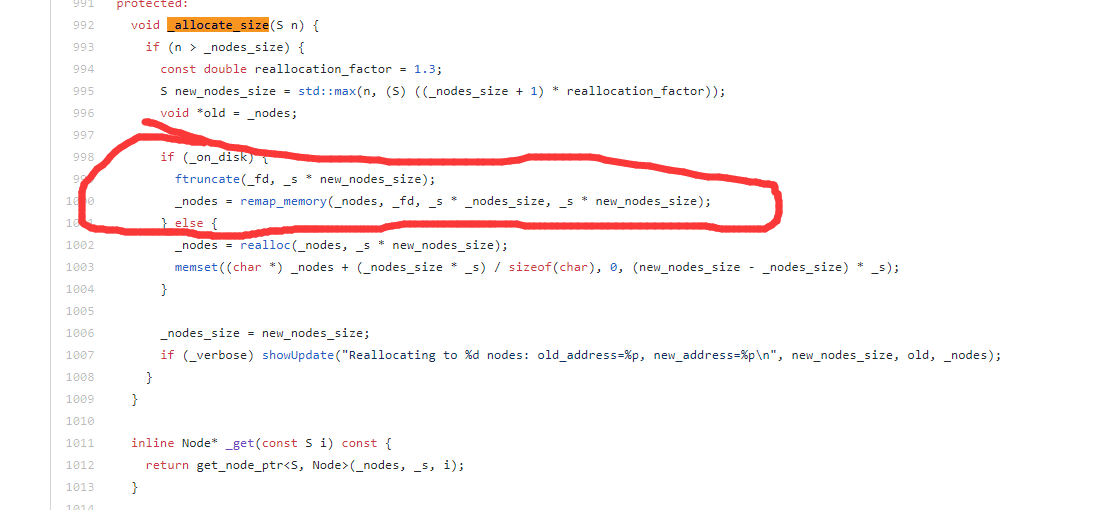
build_on_disk 问题
写文件时候,会向磁盘写
Annoy 近邻算法的更多相关文章
- 机器学习实战笔记--k近邻算法
#encoding:utf-8 from numpy import * import operator import matplotlib import matplotlib.pyplot as pl ...
- 机器学习实战笔记(Python实现)-01-K近邻算法(KNN)
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- KNN近邻算法
K近邻(KNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表.kNN算法的核 ...
- k近邻算法的Java实现
k近邻算法是机器学习算法中最简单的算法之一,工作原理是:存在一个样本数据集合,即训练样本集,并且样本集中的每个数据都存在标签,即我们知道样本集中每一数据和所属分类的对应关系.输入没有标签的新数据之后, ...
- 基本分类方法——KNN(K近邻)算法
在这篇文章 http://www.cnblogs.com/charlesblc/p/6193867.html 讲SVM的过程中,提到了KNN算法.有点熟悉,上网一查,居然就是K近邻算法,机器学习的入门 ...
- 从K近邻算法谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/v_july_v/article/details/8203674 ,感谢july的辛勤劳动 前言 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章 ...
- 机器学习之K近邻算法(KNN)
机器学习之K近邻算法(KNN) 标签: python 算法 KNN 机械学习 苛求真理的欲望让我想要了解算法的本质,于是我开始了机械学习的算法之旅 from numpy import * import ...
- k近邻算法
k 近邻算法是一种基本分类与回归方法.我现在只是想讨论分类问题中的k近邻法.k近邻算法的输入为实例的特征向量,对应于特征空间的点,输出的为实例的类别.k邻近法假设给定一个训练数据集,其中实例类别已定. ...
- KNN K~近邻算法笔记
K~近邻算法是最简单的机器学习算法.工作原理就是:将新数据的每一个特征与样本集中数据相应的特征进行比較.然后算法提取样本集中特征最相似的数据的分类标签.一般来说.仅仅提取样本数据集中前K个最相似的数据 ...
随机推荐
- Linux:echo中,>和>>的区别(保存结果和追加结果)
在Linux中,对于echo命令,保存文件时,">"和">>"是有区别的: 假如有A_R1,B_R2,C_R1三个字符 for i in `l ...
- SQL Server sp_executesql介绍和使用
execute相信大家都用的用熟了,简写为exec,除了用来执行存储过程,一般都用来执行动态Sql sp_executesql,sql2005中引入的新的系统存储过程,也是用来处理动态sql的, 如: ...
- shell中使用>/dev/null 2>&1 丢弃信息
在一些Shell脚本中,特别是Crontab的脚本中,经常会看到 >/dev/null 2>&1这样的写法. 其实这个很好理解.我们分两部分解释. 1. >/dev/nul ...
- nginx-1.12.1编译参数详情
一下nginx-1.12.1编译参数详情 #/usr/local/nginx/sbin/nginx -V nginx version: nginx/1.12.1 built by gcc 4.4.7 ...
- Ubuntu 16.04配置VNC进行远程桌面连接
1.安装 $sudo apt-get install xfce4 $sudo apt-get install vnc4server $sudo apt-get install xrdp 2.启动vnc ...
- Linux命令之less
less命令 用处:查看文件,功能强大,随意浏览,查看之前不会预先加载文件 用法:less + 文件名 (按q退出) 示例: 一.查看文档内容 (我这里有一个profile的文件,我想查看里面的 ...
- javascript 事件冒泡与取消冒泡
事件冒泡: 当一个元素上的事件被触发时,比如说鼠标点击了一个按钮,同样的事件将会在那个元素的所有祖先中被触发,这一过程被称为事件冒泡. 这个事件从原始祖先开始,一直冒泡到DOM树的最上层.(bug) ...
- Pool多进程示例
利用Pool类多进程实现批量主机管理 #!/usr/bin/python # -*- coding: UTF-8 -*- # Author: standby # Time: 2017-03-02 # ...
- CF949D Curfew
传送门 跟这个大佬学的->戳我 假设只有一个宿管,那么从前往后做的过程中,如果能到达某个寝室范围内的人数不够\(b\),那么不如把这个寝室空出来,这样更有利于后面的抉择;反之,就把这个寝室搞正好 ...
- luogu P2515 [HAOI2010]软件安装
传送门 看到唯一的依赖关系,容易想到树型dp,即\(f_{i,j}\)表示选点\(i\)及子树内连通的点,代价为\(j\)的最大价值,然后就是选课那道题 但是要注意 1.题目中的依赖关系不一定是树,可 ...