day0320 时间模块 collection模块
一. TIME模块
`python`提供了一个`time`和`calendar`模块可以用于格式化日期和时间。
时间间隔一秒为单位。
每个时间戳都以1970年1月1日午夜经过多长时间来表示。
1.时间戳
函数time.time()用于获取当前时间戳。
import time
print(time.time())
结果:
1553066028.9183624
2.时间元祖:
很多`python`函数用一个元组装起来的9组数字来处理时间。
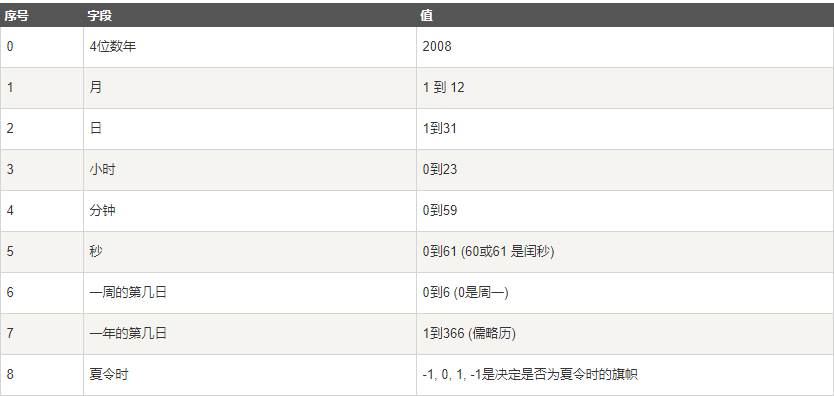
上述就是`struct_time`元组,且具有如下属性:
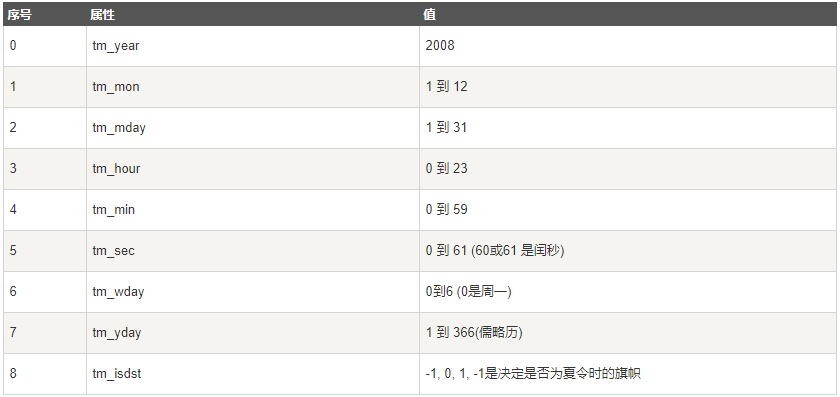
`tm_yday` 显示是一年的第几天。
怎么去获取当前时间?
从返回浮点数的时间戳向元组时间转换,用`localtime`函数
import time
localtime=time.localtime(time.time())
print('本地时间:',localtime)
结果:
本地时间: time.struct_time(tm_year=2019, tm_mon=3, tm_mday=20, tm_hour=15, tm_min=24, tm_sec=52, tm_wday=2, tm_yday=79, tm_isdst=0)
#这里是命名元组,可以索引,步长。
3.格式化时间
`time`模块中的`strftime`方式来格式化日期。
print(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime()))
#这里的格式可以改变的
结果:
2019-03-20 15:31:35
4.时间格式转换:

import time
#TIME 模块
#2019-03-20 将时间退后一个月。
f=time.strptime('2019-03-20 10:40:00','%Y-%m-%d %H:%M:%S')
将格式化时间转换成时间元组(结构化时间)
print(f)
new_T=time.mktime(f)+30*24*60*60
#将时间元组(结构化时间)转换成时间戳,在进行运算
print(new_T)
new_t=time.localtime(new_T)
#将计算后的时间戳转化成结构化时间。
print(new_t)
print(time.strftime('%Y-%m-%d %H:%M:%S',new_t))
#将结构化时间转化成格式化时间
结果:
2019-04-19 10:40:00
实现了从格式化时间-->时间元组--->时间戳--->时间元组--->格式化时间。timestamp(时间戳)
import time
#当前时间求前一个月时间
new_T=time.time()-28*24*60*60
f1=time.localtime(new_T)
print(f1)
print(time.strftime("%Y-%m-%d %H:%M:%S",f1))
结果:
2019-02-20 16:21:01
实现了从时间戳--->时间元组--->格式化时间。
二.datetime模块
`from datetime import datetime ==import datetime.datetime `导入模块
from datetime import datetime
print(datetime.now())#当前时间对象 print(datetime.timestamp(datetime.now())) #当前时间转时间戳 f=datetime.timestamp(datetime.now())
print(datetime.fromtimestamp(f)) # f是时间戳,转成时间对象 g=datetime.strptime('2019-03-21 ','%Y-%m-%d ') #字符串时间 ————》时间对象
print(g) print(datetime.strftime(datetime.now(),'%Y-%m-%d %X'))# 时间对象————》字符串时间
结果:
2019-03-21 08:38:05.097608
1553128685.097608
2019-03-21 08:38:05.097608
2019-03-21 00:00:00
2019-03-21 08:38:05
三.COLLECTION 模块
在内置数据类型(dict、list、set、tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等。
1.namedtuple: 生成可以使用名字来访问元素内容的tuple
2.deque: 双端队列,可以快速的从另外一侧追加和推出对象
3.Counter: 计数器,主要用来计数
4.OrderedDict: 有序字典
5.defaultdict: 带有默认值的字典
A.namedtuple能够用来创建类似于元组的数据类型,除了能够用索引来访问数据,能够迭代,更能够方便的通过属性名来访问数据。
from collections import namedtuple
friend=namedtuple('friend',['name','age','email'])
f1=friend('林冲',28,'178*****8@163.com')
print(f1)
print(f1.email)
f2=friend('李逵',age=29,email='15***46@163.com')
print(f2)
name,age,email=f2
print(name,age)
结果:
friend(name='林冲', age=28, email='178*****8@163.com')
178*****8@163.com
friend(name='李逵', age=29, email='15***46@163.com')
李逵 29
from collections import namedtuple
def get_name():
name=namedtuple('name',['first','middle','last'])
return name('JOHN',"you know nothing",'snow')
name=get_name()
print(name.first,name.middle,name.last)
结果:
JOHN you know nothing snow
B.deque
使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。
deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈:提供了两端都可以操作的序列。在序列的前后都能执行添加或删除操作。
import collections
d=collections.deque() #创建双向队列
d.append('Ada lace') #左侧添加元素
d.appendleft('I love ')
print(d)
结果:
deque(['I love ', 'Ada lace'])
import collections
d=collections.deque() #创建双向队列
d.append('Ada lace')
d.appendleft('I love ')
print(d)
d.clear() #清空队列
print(d)
结果:
deque(['I love ', 'Ada lace'])
deque([])
import collections
d=collections.deque()#创建双向队列
d.append('蓝天白云。。。') #左侧添加元素
d.appendleft('爱就像 ')
print(d) d.extendleft([3,2,1]) #从左侧队列扩展列表元素
print(d)
结果:
deque(['爱就像 ', '蓝天白云。。。'])
deque([1, 2, 3, '爱就像 ', '蓝天白云。。。'])
import collections
d=collections.deque()#创建双向队列
d.append('蓝天白云。。。') #左侧添加元素
d.appendleft('爱就像 ') d.extend([3,2,1]) #从右侧队列扩展列表元素
print(d)
print(d.index(3)) #该方法返回查找对象的索引位置,如果没有找到对象则抛出异常。
print(d.index('爱就像 ',0,1)) #从索引0到1,定义了查找区间
结果:
deque(['爱就像 ', '蓝天白云。。。', 3, 2, 1])
2
0
C.Counter
Counter类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数作为value。计数值可以是任意的Interger(包括0和负数)。Counter类和其他语言的bags或multisets很相似。
from collections import Counter
L=Counter({'k':1})
l1=Counter([1,2,'ada',1])
print(L)
print(l1) #显示元素和出现次数
结果:
Counter({'k': 1})
Counter({1: 2, 2: 1, 'ada': 1})
https://www.jb51.net/article/115578.htm(关于defaultdict的文章)
from collections import defaultdict
li = [('红色',1),('黄色',1),('绿色',1),('蓝色',1),('红色',5),('绿色',1),('绿色',1),('绿色',1)] d = defaultdict(list)
for i in li:
d[i[0]].append(i[1])
dd = dict(d)
print(dd)
for em in dd:
dd[em] = sum(dd[em]) print(dd)
结果:
{'红色': [1, 5], '黄色': [1], '绿色': [1, 1, 1, 1], '蓝色': [1]}
{'红色': 6, '黄色': 1, '绿色': 4, '蓝色': 1}
D.defaultdict:
# -*- coding: utf-8 -*-
from collections import defaultdict
members = [
# Age, name
['male', 'John'],
['male', 'Jack'],
['female', 'Lily'],
['male', 'Pony'],
['female', 'Lucy'],
]
result = defaultdict(list)
for sex, name in members:
result[sex].append(name)
print result
# Result:
defaultdict(<type 'list'>, {'male': ['John', 'Jack', 'Pony'], 'female': ['Lily', 'Lucy']})
day0320 时间模块 collection模块的更多相关文章
- Python进阶(十)----软件开发规范, time模块, datatime模块,random模块,collection模块(python额外数据类型)
Python进阶(十)----软件开发规范, time模块, datatime模块,random模块,collection模块(python额外数据类型) 一丶软件开发规范 六个目录: #### 对某 ...
- day 20 collection模块 time 模块 os 模块
一.collection模块 1.namedtuple: 生成可以使用名字来访问元素内容的tuple 2.deque: 双端队列,可以快速的从另外一侧追加和推出对象 3.Counter: 计数器,主要 ...
- Backbone源码解析(三):Collection模块
Collection模块式是对分散在项目中model的收集,他可以存储所有的model,构成一个集合,并且通过自身的方法统一操作model.Collection模块包装着若干对象,对象本身不具有一些方 ...
- s14 第5天 时间模块 随机模块 String模块 shutil模块(文件操作) 文件压缩(zipfile和tarfile)shelve模块 XML模块 ConfigParser配置文件操作模块 hashlib散列模块 Subprocess模块(调用shell) logging模块 正则表达式模块 r字符串和转译
时间模块 time datatime time.clock(2.7) time.process_time(3.3) 测量处理器运算时间,不包括sleep时间 time.altzone 返回与UTC时间 ...
- python双端队列-collection模块
双端队列(double-ended queue,或者称deque)在需要按照元素增加的顺序来移除元素时非常有用.其中collection模块,包括deque类型. 使用实例:
- python基础 ---time,datetime,collections)--时间模块&collections 模块
python中的time和datetime模块是时间方面的模块 time模块中时间表现的格式主要有三种: 1.timestamp:时间戳,时间戳表示的是从1970年1月1日00:00:00开始按秒计算 ...
- python 全栈开发,Day27(复习, defaultdict,Counter,时间模块,random模块,sys模块)
一.复习 看下面一段代码,假如运行结果有问题,那么就需要在每一步计算时,打印一下结果 b = 1 c = 2 d = 3 a = b+c print(a) e = a + d print(e) 执行输 ...
- python的时间处理-time模块
time模块 时间的表示方法有三种: 时间戳:表示的是从1970年1月1日0点至今的秒数 格式化字符串表示:这种表示更习惯我们通常的读法,如2018-04-24 00:00:00 格式化元祖表示:是一 ...
- Python:日期和时间的处理模块及相关函数
Python:日期和时间的处理模块及相关函数 Python 提供 time 模块和 calendar 模块用于格式化日期和时间. 一.时间戳 在Python中,时间戳是以秒为单位的浮点小数,它是指格林 ...
随机推荐
- lua -- 生成协议
这是爬塔的协议 <?xml version="1.0" encoding="utf-8" ?> <coder name="Tower ...
- 【IOS】java 与oc之间的比较
Cocoa是什么,Cocoa是使用OC语言编写的工具包,里面有大量的类库.结构体,其实就相当于java中的标准API.C++中的标准库.OC中没有命名空间的概念,所以使用加前缀来防止命名冲突,因此你会 ...
- Java、Linux、Win 快速生成指定大小的空文件
Linux dd 命令: dd if=/dev/zero of=<fileName> bs=<一次复制的大小> count=<复制的次数> 生成 50 MB 的空文 ...
- MT7601 AP模式移植
MT7601 的 STA 模式和 AP 模式的驱动,是不一样的. 所以,需要另外移植驱动 驱动源码位置 https://github.com/eywalink/mt7601u 下载之后,先修改 Mak ...
- Java知多少(41)泛型详解
我们知道,使用变量之前要定义,定义一个变量时必须要指明它的数据类型,什么样的数据类型赋给什么样的值. 假如我们现在要定义一个类来表示坐标,要求坐标的数据类型可以是整数.小数和字符串,例如: x = 1 ...
- java 全组合 与全排列
一.全组合 public static void Combination( ) { /*基本思路:求全组合,则假设原有元素n个,则最终组合结果是2^n个.原因是: * 用位操作方法:假设元素原本有:a ...
- jQuery图片播放插件prettyPhoto使用介绍
演示效果 http://www.17sucai.com/preview/131993/2014-07-09/mac-Bootstrap/gallery.html 点击之后的效果 使用方法 Query ...
- [TensorBoard] Name & Variable scope
TF有两个scope, 一个是name_scope一个是variable_scope 第一个程序: with tf.name_scope("hello") as name_scop ...
- 网络编程 -- RPC实现原理 -- Netty -- 迭代版本V4 -- 粘包拆包
网络编程 -- RPC实现原理 -- 目录 啦啦啦 V2——Netty -- new LengthFieldPrepender(2) : 设置数据包 2 字节的特征码 new LengthFieldB ...
- puppet 用户和组资源管理
1. 用户和组资源的特性: 1.1 用户特性: allows_duplicates 支持含有相同UID的用户. manages_aix_lam ...