Hanlp实战HMM-Viterbi角色标注中国人名识别
这几天写完了人名识别模块,与分词放到一起形成了两层隐马模型。虽然在算法或模型上没有什么新意,但是胜在训练语料比较新,对质量把关比较严,实测效果很满意。比如这句真实的新闻“签约仪式前,秦光荣、李纪恒、仇和等一同会见了参加签约的企业家。”,分词结果:[签约/v, 仪式/n, 前/f, ,/w, 秦光荣/nr, 、/w, 李纪恒/nr, 、/w, 仇和/nr, 等/u, 一同/d, 会见/v, 了/ul, 参加/v, 签约/v, 的/uj, 企业家/n, 。/w],三个人名“秦光荣”“李纪恒”“仇和”一个不漏。一些比较变态的例子也能从容应对,比如下面:

这是hankcs将自己的分词与ansj作比较得出的结果,由于自己可以随时调整算法,所以主场占了很大便宜。但是第一句绝对没有放水,说实话能识别出“仇和”这么冷僻的名字着实让人惊喜了一下。

开源项目
本文代码已集成到HanLP中开源:https://github.com/hankcs/HanLP
原理
推荐仔细阅读《基于角色标注的中国人名自动识别研究.doc》这篇论文,该论文详细地描述了算法原理和实现。从语料库的整理、标注到最后的模式匹配都讲得清清楚楚。hankcs在这篇论文的基础上做了改进,主要步骤总结如下:
1、对熟语料库自动标注,将原来的标注转化为角色标注。角色标注一共有如下几种:
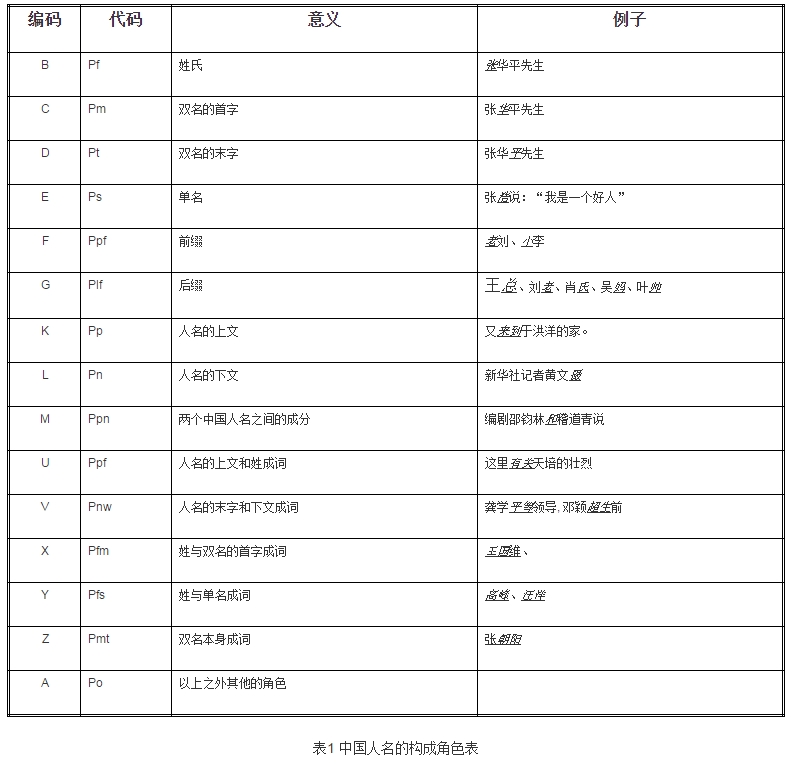
hankcs在此基础上拓展了一个S,代表句子的开始。
2、统计标签的出现频次,标签的转移矩阵。
3、对粗分结果角色标注,模式匹配。
hankcs对论文中的几个模式串做了拓充,并且采用了AC模式匹配算法。
体会
论文中将三字名称拆分为BCD,实测在2-gram模型下,C很容易被识别为E,导致人名缺一半。
人民日报2014中的人名并不能覆盖所有常用字,所以hankcs去别的地方找了个人名库,拆成BCD或BE补充了进去。
人民日报2014语料库中有很多错误,比如
去/vf 年老/vi 张中秋/nr 去/vf “/w 泡茶/vi ”/w ,/w 送礼/vi 遭到/v 了/ule 拒绝/v ,/w 老张/nz 担心/v 金额/n 不够/a
中秋很明显不是人名的组成部分,这个必须手工剔除。
“中秋安全”会识别出“中 秋安全”来,因为2-gram词典中没有“中秋@安全”这种接续,而有“中@未##人”这种接续。初步的解决方法是手工往2-gram词典里面加一条“中秋@安全”。这反映了这种方法的局限性,另一方面也说明词典的重要性。

文章转载自hankcs的博客!
Hanlp实战HMM-Viterbi角色标注中国人名识别的更多相关文章
- 实战HMM-Viterbi角色标注地名识别
http://www.hankcs.com/nlp/ner/place-names-to-identify-actual-hmm-viterbi-role-labeling.html 命名实体识别(N ...
- ICTCLAS中的HMM人名识别
http://www.hankcs.com/nlp/segment/ictclas-the-hmm-name-recognition.html 本文主要从代码的角度分析标注过程中的细节,理论谁都能说, ...
- 基于分布式的短文本命题实体识别之----人名识别(python实现)
目前对中文分词精度影响最大的主要是两方面:未登录词的识别和歧义切分. 据统计:未登录词中中文姓人名在文本中一般只占2%左右,但这其中高达50%以上的人名会产生切分错误.在所有的分词错误中,与人名有关的 ...
- 学习笔记CB008:词义消歧、有监督、无监督、语义角色标注、信息检索、TF-IDF、隐含语义索引模型
词义消歧,句子.篇章语义理解基础,必须解决.语言都有大量多种含义词汇.词义消歧,可通过机器学习方法解决.词义消歧有监督机器学习分类算法,判断词义所属分类.词义消歧无监督机器学习聚类算法,把词义聚成多类 ...
- HanLP-基于HMM-Viterbi的人名识别原理介绍
Hanlp自然语言处理包中的基于HMM-Viterbi处理人名识别的内容大概在年初的有分享过这类的文章,时间稍微久了一点,有点忘记了.看了 baiziyu 分享的这篇比我之前分享的要简单明了的多.下面 ...
- HanLP中人名识别分析
HanLP中人名识别分析 在看源码之前,先看几遍论文<基于角色标注的中国人名自动识别研究> 关于命名识别的一些问题,可参考下列一些issue: 名字识别的问题 #387 机构名识别错误 关 ...
- HanLP中人名识别分析详解
HanLP中人名识别分析详解 在看源码之前,先看几遍论文<基于角色标注的中国人名自动识别研究> 关于命名识别的一些问题,可参考下列一些issue: l ·名字识别的问题 #387 l ·机 ...
- HanLP中的人名识别分析详解
在看源码之前,先看几遍论文<基于角色标注的中国人名自动识别研究> 关于命名识别的一些问题,可参考下列一些issue: u u名字识别的问题 #387 u u机构名识别错误 u u关于层叠H ...
- hanlp自然语言处理包的人名识别代码解析
HanLP发射矩阵词典nr.txt中收录单字姓氏393个.袁义达在<中国的三大姓氏是如何统计出来的>文献中指出:当代中国100个常见姓氏中,集中了全国人口的87%,根据这一数据我们只保留n ...
随机推荐
- django面试三
1.Django. Flask.Tornado框架的比较? Django: 对于django,大而全的框架它的内部组件比较多,内部提供:ORM.Admin.中间件.Form.ModelForm.Ses ...
- python 元组攻略
1.元组中只包含一个元素时,需要在元素后面添加逗号来消除歧义 tup1=(50,) 2.元组中的元素值使不允许修改的,但可以对元组进行连接组合复制代码 1 tup1=(12,34.56)2 tup2= ...
- Day11作业及默写
1.写函数,传入n个数,返回字典{'max':最大值,'min':最小值} 例如:min_max(2,5,7,8,4) 返回:{'max':8,'min':2}(此题用到max(),min()内置函数 ...
- MAC机下用Terminal操作MySql
在MAC机上安装好MySql后,在Terminal内运行mysql时会提示mysql command not found命令.这是因为没有把运行时的路径添加到$PATH变量中.检查$PATH变量中是否 ...
- Python之路,第二篇:Python入门与基础2
1,复合赋值运算符 += . -= . *= . /= . //= . %= , **= x += y 等同于 x = x + y x -= ...
- python中调用多线程加速处理文件
问题背景是这样的,我有一批需要处理的文件,对于每一个文件,都需要调用同一个函数进行处理,相当耗时 有没有加速的办法呢?当然有啦,比如说你将这些文件分成若干批,每一个批次都调用自己写的python脚本进 ...
- CF444(Div. 1简单题解)
A .DZY Loves Physics 题意:给定带点权和边权的无向图,现在让你选一些点,使得 点权和/被选点对间的边权和 最大. 思路:不难证明,选择边和对应的两点是最优的. #include&l ...
- Java之从头开始编写简单课程信息管理系统
编写简单的课程管理系统对于新手并不友好,想要出色的完成并不容易以下是我的一些经验和方法 详情可参考以下链接: https://www.cnblogs.com/dream0-0/p/10090828.h ...
- PTA——时间转换
PTA 7-14 然后是几点 #include<stdio.h> int main() { int a,b,hour,min; scanf("%d%d",&a, ...
- java-接口的概述及其特点
1.接口概述: - 从狭义的角度讲就是指java中的interface - 从广义的角度讲对外提供规则的都是接口 2.接口特点: - 接口中定义的全都是抽象方法. - 接口用关键字interface表 ...