『MXNet』第三弹_Gluon模型参数
MXNet中含有init包,它包含了多种模型初始化方法。
from mxnet import init, nd
from mxnet.gluon import nn net = nn.Sequential()
net.add(nn.Dense(256, activation='relu'))
net.add(nn.Dense(10))
net.initialize() x = nd.random.uniform(shape=(2,20))
y = net(x)
一、访问模型参数
我们知道可以通过[]来访问Sequential类构造出来的网络的特定层。对于带有模型参数的层,我们可以通过Block类的params属性来得到它包含的所有参数。例如我们查看隐藏层的参数:
print(net[0].params)
print(net[0].collect_params())
dense0_ (
Parameter dense0_weight (shape=(256, 20), dtype=float32)
Parameter dense0_bias (shape=(256,), dtype=float32)
)
dense0_ (
Parameter dense0_weight (shape=(256, 20), dtype=float32)
Parameter dense0_bias (shape=(256,), dtype=float32)
)
有意思的是,
print(net.params)
print(net.collect_params())
sequential0_ ( )
sequential0_ (
Parameter dense0_weight (shape=(256, 20), dtype=float32)
Parameter dense0_bias (shape=(256,), dtype=float32)
Parameter dense1_weight (shape=(10, 256), dtype=float32)
Parameter dense1_bias (shape=(10,), dtype=float32)
)
为了访问特定参数,我们既可以通过名字来访问字典里的元素,也可以直接使用它的变量名。下面两种方法是等价的,但通常后者的代码可读性更好,
(net[0].params['dense0_weight'], net[0].weight)
(Parameter dense0_weight (shape=(256, 20), dtype=float32),
Parameter dense0_weight (shape=(256, 20), dtype=float32))
Parameter类
data和grad函数来访问:
net[0].weight.data()
net[0].weight.grad()
声明方法一
至于Parameter类,是指mxnet.gluon.Parameter,声明需要名字和尺寸:
my_param = gluon.Parameter('exciting_parameter_yay', shape=(3, 3))
my_param.initialize()
声明方法二
我们还可以使用Block自带的ParameterDict类的成员变量params。顾名思义,这是一个由字符串类型的参数名字映射到Parameter类型的模型参数的字典。
我们可以通过get函数从ParameterDict创建Parameter,同样的声明需要名字和尺寸:
params = gluon.ParameterDict()
params.get("param2", shape=(2, 3))
params
(
Parameter param2 (shape=(2, 3), dtype=<class 'numpy.float32'>)
)
形如net.params返回的就是一个ParameterDict类,自己的层class书写时,就是用这个方式创建参数并被层class感知(收录进层隶属的ParameterDict类中)。
二、初始化模型参数
[-0.07, 0.07]之间均匀分布的随机数,偏差参数则全为0. 但经常我们需要使用其他的方法来初始话权重,MXNet的init模块里提供了多种预设的初始化方法。例如下面例子我们将权重参数初始化成均值为0,标准差为0.01的正态分布随机数。
# 非首次对模型初始化需要指定 force_reinit
net.initialize(init=init.Normal(sigma=0.01), force_reinit=True)
- mxnet.init模块
- force_reinit为了防止用户失误将参数全部取消
自定义初始化函数
有时候我们需要的初始化方法并没有在init模块中提供,这时我们有两种方法来自定义参数初始化。
一种是实现一个Initializer类的子类
使得我们可以跟前面使用init.Normal那样使用它。在这个方法里,我们只需要实现_init_weight这个函数,将其传入的NDArray修改成需要的内容。下面例子里我们把权重初始化成[-10,-5]和[5,10]两个区间里均匀分布的随机数,教程只讲了weight初始化,后面查看源码还有bias的,以及一些其他的子方法,理论上用时再研究,不过方法二明显更简单易用……
class MyInit(init.Initializer):
def _init_weight(self, name, data):
print('Init', name, data.shape)
data[:] = nd.random.uniform(low=-10, high=10, shape=data.shape)
data *= data.abs() >= 5 net.initialize(MyInit(), force_reinit=True)
net[0].weight.data()[0]
Init dense0_weight (256, 20)
Init dense1_weight (10, 256)[-5.36596727 7.57739449 8.98637581 -0. 8.8275547 0.
5.98405075 -0. 0. 0. 7.48575974 -0. -0.
6.89100075 6.97887039 -6.11315536 0. 5.46652031 -9.73526287
9.48517227]
<NDArray 20 @cpu(0)>
第二种方法是我们通过Parameter类的set_data函数
可以直接改写模型参数。例如下例中我们将隐藏层参数在现有的基础上加1.
net[0].weight.set_data(net[0].weight.data()+1)
net[0].weight.data()[0]
[ -4.36596727 8.57739449 9.98637581 1. 9.8275547 1.
6.98405075 1. 1. 1. 8.48575974 1. 1.
7.89100075 7.97887039 -5.11315536 1. 6.46652031
-8.73526287 10.48517227]
<NDArray 20 @cpu(0)>
三、共享模型参数
在有些情况下,我们希望在多个层之间共享模型参数。我们在“模型构造”这一节看到了如何在Block类里forward函数里多次调用同一个类来完成。这里将介绍另外一个方法,它在构造层的时候指定使用特定的参数。如果不同层使用同一份参数,那么它们不管是在前向计算还是反向传播时都会共享共同的参数。
原理:层函数params API接收其他层函数的params属性即可
在下面例子里,我们让模型的第二隐藏层和第三隐藏层共享模型参数:
from mxnet import nd
from mxnet.gluon import nn net = nn.Sequential()
shared = nn.Dense(8, activation='relu')
net.add(nn.Dense(8, activation='relu'),
shared,
nn.Dense(8, activation='relu', params=shared.params),
nn.Dense(10))
net.initialize() x = nd.random.uniform(shape=(2,20))
net(x) net[1].weight.data()[0] == net[2].weight.data()[0]
[ 1. 1. 1. 1. 1. 1. 1. 1.]
<NDArray 8 @cpu(0)>
我们在构造第三隐藏层时通过params来指定它使用第二隐藏层的参数。由于模型参数里包含了梯度,所以在反向传播计算时,第二隐藏层和第三隐藏层的梯度都会被累加在shared.params.grad()里。
四、模型延后初始化
从下面jupyter可以看到模型参数实际初始化的时机:既不是调用initialize时,也不是没次运行时,仅仅第一次送入数据运行时会调用函数进行参数初始化,所以MXNet不需要定义指定输入数据尺寸的关键也在这里。
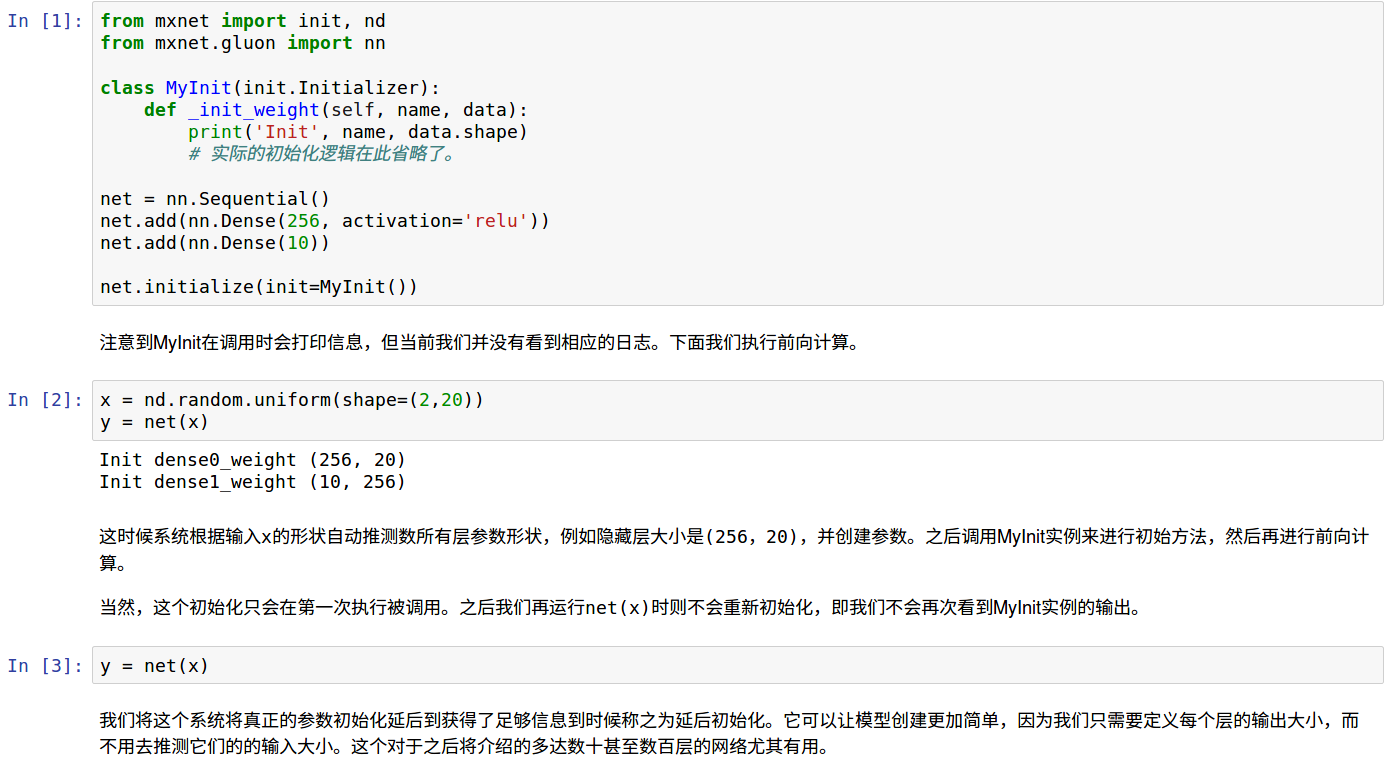
立即初始化参数
基于以上,当模型获悉数据尺寸时不会发生延后,
- 已经运行过,指定重新初始化时不会延后
- 定义过程中,指定in_units的模型不会延后
代码如下,
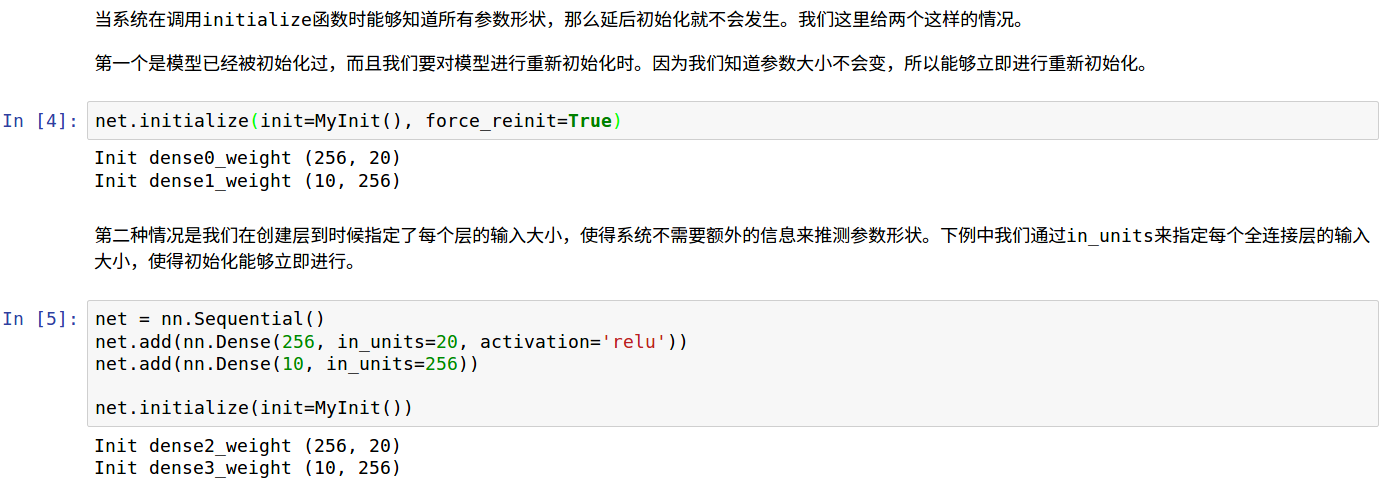
最后一格代码块中,第二个dense层去掉in_uints的话仅仅第一个dense会立即初始化。
数据形状改变时网络行为
如果在下一次net(x)前改变x形状,包括批量大小和特征大小,会发生什么?
批量大小改变不影响,特征大小改变会报错。
『MXNet』第三弹_Gluon模型参数的更多相关文章
- 『MXNet』第四弹_Gluon自定义层
一.不含参数层 通过继承Block自定义了一个将输入减掉均值的层:CenteredLayer类,并将层的计算放在forward函数里, from mxnet import nd, gluon from ...
- 『MXNet』第六弹_Gluon性能提升
一.符号式编程 1.命令式编程和符号式编程 命令式: def add(a, b): return a + b def fancy_func(a, b, c, d): e = add(a, b) f = ...
- 『MXNet』第六弹_Gluon性能提升 静态图 动态图 符号式编程 命令式编程
https://www.cnblogs.com/hellcat/p/9084894.html 目录 一.符号式编程 1.命令式编程和符号式编程 2.MXNet的符号式编程 二.惰性计算 用同步函数实际 ...
- 『PyTorch』第三弹重置_Variable对象
『PyTorch』第三弹_自动求导 torch.autograd.Variable是Autograd的核心类,它封装了Tensor,并整合了反向传播的相关实现 Varibale包含三个属性: data ...
- 关于『HTML』:第三弹
关于『HTML』:第三弹 建议缩放90%食用 盼望着, 盼望着, 第三弹来了, HTML基础系列完结了!! 一切都像刚睡醒的样子(包括我), 欣欣然张开了眼(我没有) 敬请期待Markdown语法系列 ...
- 『MXNet』第十一弹_符号式编程初探
一.符号分类 符号对我们想要进行的计算进行了描述, 下图展示了符号如何对计算进行描述. 我们定义了符号变量A, 符号变量B, 生成了符号变量C, 其中, A, B为参数节点, C为内部节点! mxne ...
- 『MXNet』第七弹_多GPU并行程序设计
资料原文 一.概述思路 假设一台机器上有个GPU.给定需要训练的模型,每个GPU将分别独立维护一份完整的模型参数. 在模型训练的任意一次迭代中,给定一个小批量,我们将该批量中的样本划分成份并分给每个G ...
- 『MXNet』第十弹_物体检测SSD
全流程地址 一.辅助API介绍 mxnet.image.ImageDetIter 图像检测迭代器, from mxnet import image from mxnet import nd data_ ...
- 『MXNet』第八弹_数据处理API_下_Image IO专题
想学习MXNet的同学建议看一看这位博主的博客,受益良多. 在本节中,我们将学习如何在MXNet中预处理和加载图像数据. 在MXNet中加载图像数据有4种方式. 使用 mx.image.imdecod ...
随机推荐
- IDEA配置SVN,Git,GitLab
集成GitLab插件:http://baijiahao.baidu.com/s?id=1602987918454762059&wfr=spider&for=pc 使用IDEA集成Git ...
- fhqtreap初探
介绍 fhqtreap为利用分裂和合并来满足平衡树的性质,不需要旋转操作的一种平衡树. 并且利用函数式编程可以极大的简化代码量. (题目是抄唐神的来着) 核心操作 (均为按位置分裂合并) struct ...
- LightOJ 1258 Making Huge Palindromes(KMP)
题意 给定一个字符串 \(S\) ,一次操作可以在这个字符串的右边增加任意一个字符.求操作之后的最短字符串,满足操作结束后的字符串是回文. \(1 \leq |S| \leq 10^6\) 思路 \( ...
- win10 右键菜单很慢的解决方式
本来想用 win7 的,不想花很多时间折腾了.现在新电脑主板硬盘CPU都在排挤 win7 ,真是可怜呀.正题: 新电脑的性能应该还算不错的, 18 年跑分 29w 以上,但在图标上面右键却都要转圈几秒 ...
- Codeforces Round #267 (Div. 2) D. Fedor and Essay tarjan缩点
D. Fedor and Essay time limit per test 2 seconds memory limit per test 256 megabytes input standard ...
- ros 节点关闭后重启
加入参数 respawn="true"
- eclipse里安装SVN插件的两种方式
eclipse里安装SVN插件,一般来说,有两种方式: 直接下载SVN插件,将其解压到eclipse的对应目录里 使用eclipse 里Help菜单的“Install New Software”,通过 ...
- webpack 使用
背景: 简而言之,如果你曾经遇到过以下任何一种情况:载入有问题的依赖项遇到作用域的问题 —— CSS 和 JavaScript 都会有寻找一个让你在 JavaScript 中使用 Node/Bower ...
- 虹软人脸识别SDK的接入方法
背景: 虹软的人脸识别还是不错的,在官方注册一个账号,成为开发者,下载SDK的jar包,在开发者中心,找一个demo就可以开始做了,安装里边的逻辑,先看理解代码,然后就可以控制代码,完成自己想要的功能 ...
- 学习笔记37—WIN7系统本地连接没有有效的IP地址 电脑本地连接无有效ip配置怎么办
WIN7系统本地连接没有有效的IP地址 电脑本地连接无有效ip配置怎么办 家中有两台笔记本都有无线网卡,现在想让两台笔记本都能够上网,而又不想购买路由器,交换机等设备,这个时候怎么办呢? 其实只要进行 ...