nodeJs爬虫获取数据
var http=require('http');
var cheerio=require('cheerio');//页面获取到的数据模块
var url='http://www.jcpeixun.com/lesson/1512/';
function filterData(html){
/*所要获取到的目标数组
var courseData=[{
chapterTitle:"",
videosData:{
videoTitle:title,
videoId:id,
videoPrice:price
}
}] */
var $=cheerio.load(html);
var courseData=[];
var chapters=$(".list-collapse");
chapters.each(function(item){
var chapterTitle=$(this).find(".collapse-head").find("label").text();
var videos=$(this).find(".listview5").children("li");
var chaptersData={
chaptersTitle:chapterTitle,
videosData:[]
}
videos.each(function(item){
var videoTitle=$(this).find(".ml10").attr('data-lesson-name');
var videoId=$(this).find(".ml10").attr('data-lesson-id');
var vadeoPrice=$(this).find(".colblue").text();
chaptersData.videosData.push({
title:videoTitle,
id:videoId,
price:vadeoPrice
})
})
courseData.push(chaptersData)
})
return courseData
}
function printCourseInfo(courseData){
courseData.forEach(function(item){
console.log(item.chaptersTitle+'\n');
item.videosData.forEach(function(item){
console.log(item.title+'【'+item.id+'】'+item.price+'\n')
})
})
}
http.get(url,function(res){
html="";
res.on("data",function(data){
html+=data
})
res.on('end',function(){
var courseData=filterData(html);
printCourseInfo(courseData)
})
})
打开CMD,进行node环境,运行js,可以看到已经获取到了数据;
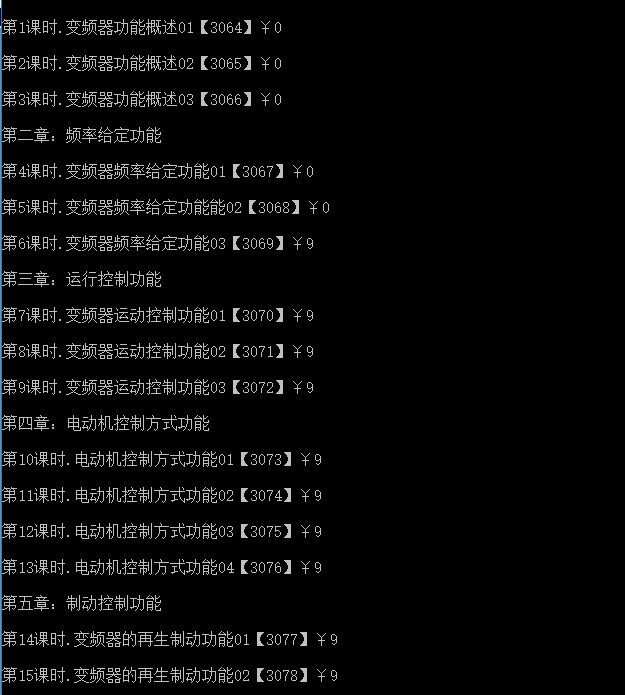
nodeJs爬虫获取数据的更多相关文章
- 利用Jsoup模拟跳过登录爬虫获取数据
今天在学习爬虫的时候想着学习一下利用jsoup模拟登录.下面分为有验证码和无验证码的情况进行讨论. ---------------------------无验证码的情况---------------- ...
- 在我的新书里,尝试着用股票案例讲述Python爬虫大数据可视化等知识
我的新书,<基于股票大数据分析的Python入门实战>,预计将于2019年底在清华出版社出版. 如果大家对大数据分析有兴趣,又想学习Python,这本书是一本不错的选择.从知识体系上来看, ...
- 手把手教你写带登录的NodeJS爬虫+数据展示
其实在早之前,就做过立马理财的销售额统计,只不过是用前端js写的,需要在首页的console调试面板里粘贴一段代码执行,点击这里.主要是通过定时爬取https://www.lmlc.com/s/web ...
- nodejs爬虫——汽车之家所有车型数据
应用介绍 项目Github地址:https://github.com/iNuanfeng/node-spider/ nodejs爬虫,爬取汽车之家(http://www.autohome.com.cn ...
- 爬虫 Http请求,urllib2获取数据,第三方库requests获取数据,BeautifulSoup处理数据,使用Chrome浏览器开发者工具显示检查网页源代码,json模块的dumps,loads,dump,load方法介绍
爬虫 Http请求,urllib2获取数据,第三方库requests获取数据,BeautifulSoup处理数据,使用Chrome浏览器开发者工具显示检查网页源代码,json模块的dumps,load ...
- Python实现简单的爬虫获取某刀网的更新数据
昨天晚上无聊时,想着练习一下Python所以写了一个小爬虫获取小刀娱乐网里的更新数据 #!/usr/bin/python # coding: utf-8 import urllib.request i ...
- nodejs 通过 get获取数据修改redis数据
如下代码是没有报错的正确代码 我通过https获取到数据 想用redis set一个键值存储 现在我掉入了回调陷阱res.on 里面接收到的数据是data 里面如果放入 client.on('conn ...
- Java学习-058-Jsoup爬虫获取中国所有的三级行政区划数据(三),处理二级编码缺失
通过查看数据可知,直辖市或者某些三级行政区域没有对应的二级区域,为方便后续的地址使用,可自定义缺失的二级地址. 如下示例自定义的二级行政区域的名称为一级区域的名称,对应的源码如下所示: 将此段源码添加 ...
- 豆瓣爬虫——通过json接口获取数据
最近在复习resqusts 爬虫模块,就重新写了一个豆瓣爬虫,这个网页从HTML 源码上来看是没有任何我想要的信息的,如下图所示: 这是网页视图,我在源码中查找影片信息,没有任何信息,如图: 由此我判 ...
随机推荐
- Mysql 自定义随机字符串
前几天在开发一个系统,需要用到随机字符串,但是mysql的库函数有没有直接提供,就简单的利用现有的函数东拼西凑出随机字符串来.下面简单的说下实现当时. 1.简单粗暴. select ..., subs ...
- 在VMware中安装RHEL6.2(下)—— RHEL系统安装
一. 打开安装好的虚拟机,因为上一篇我们未设置任何RHEL的安装源,所以它会如下图提示: 二. 图上标识为两种更改光盘设置的方法,物理或虚拟光盘皆可. 1. 选择①: 2. 选择②,点击设置...: ...
- kettle的windows安装
1.首先去官网下载安装包,这个安装包在所有平台上是通用的. 2.kettle是java语言开发的,所以需要配置JAVA_HOME 3.解压kettle的安装包 4.配置环境变量,KETTLE_HOME ...
- HBase分布式安装
安装HBase之前需要先安装Hadoop,因为HBase是运行在Hadoop集群上的.安装Hadoop可以参照http://www.cnblogs.com/stGeekpower/p/3307289. ...
- (转)最强Android模拟器genymotion的安装与配置
Android开发人员都知道,原生的模拟器启动比较慢,操作起来也不流畅,还会出现莫名的问题.当然很多人都会选择直接使用android手机来开发,但是有时候需要在投影仪上演示程序的时候手机不太好做到吧. ...
- [CentOS 7] 安装nginx第一步先搭建nginx服务器环境
简要地介绍一下,如何在CentOS 7中安装nginx服务器 方法/步骤 下载对应当前系统版本的nginx包(package) # wget http://nginx.org/packages/ ...
- How to executing direct SQL statements [Axapta, AX4.0, AX2009, AX2012]
Today I want to talk about executing SQL statements in X++ on both the current AX database and exter ...
- asp.net解析请求报文
NameValueCollection myHeader = new NameValueCollection(); int i; string strKey; string result; myHea ...
- C#调用sap接口及返回数据到sap
public class SapClass { /// <summary> /// /// </summary> /// <param name="fphm&q ...
- Spring IOC 方式结合TESTGN测试用例,测试简单java的命令模式
java命令模式: 可以命令("请求")封装成一个对象,一个命令对象通过在特定的接收着上绑定一组动作来封装一个请求.命令对象直接把执行动作和接收者包进对象中,只对外暴露出执行方法的 ...