Spark2.2,IDEA,Maven开发环境搭建附测试
前言:
停滞了一段时间,现在要沉下心来学习点东西,出点货了。
本文没有JavaJDK ScalaSDK和 IDEA的安装过程,网络上会有很多文章介绍这个内容,因此这里就不再赘述。
一、在IDEA上安装Scala插件
首先打开IDEA,进入最初的窗口,选择Configure -——>Plugins

然后会看到下面的窗口:
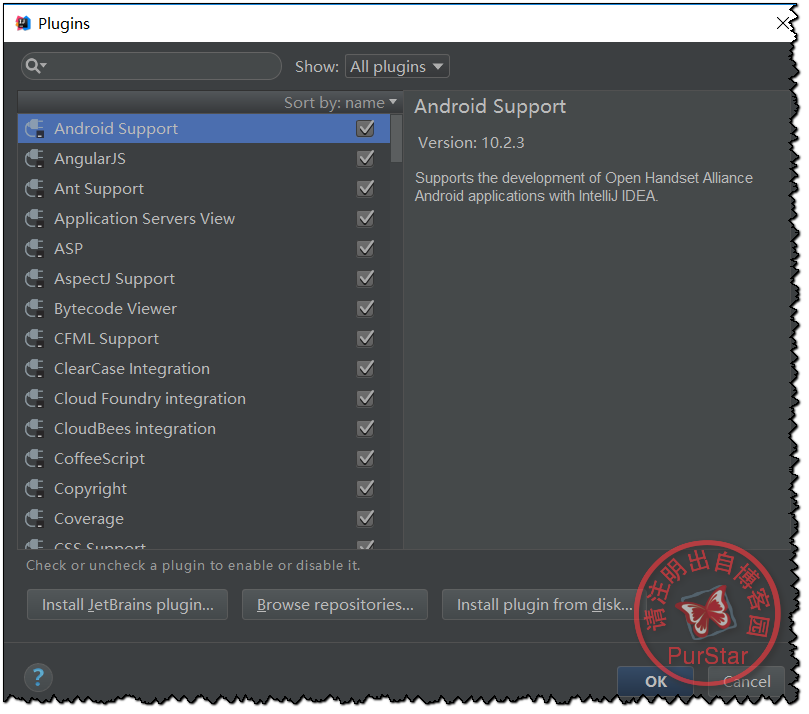
此时我们选择‘Browse Repositories …’,然后输入Scala,
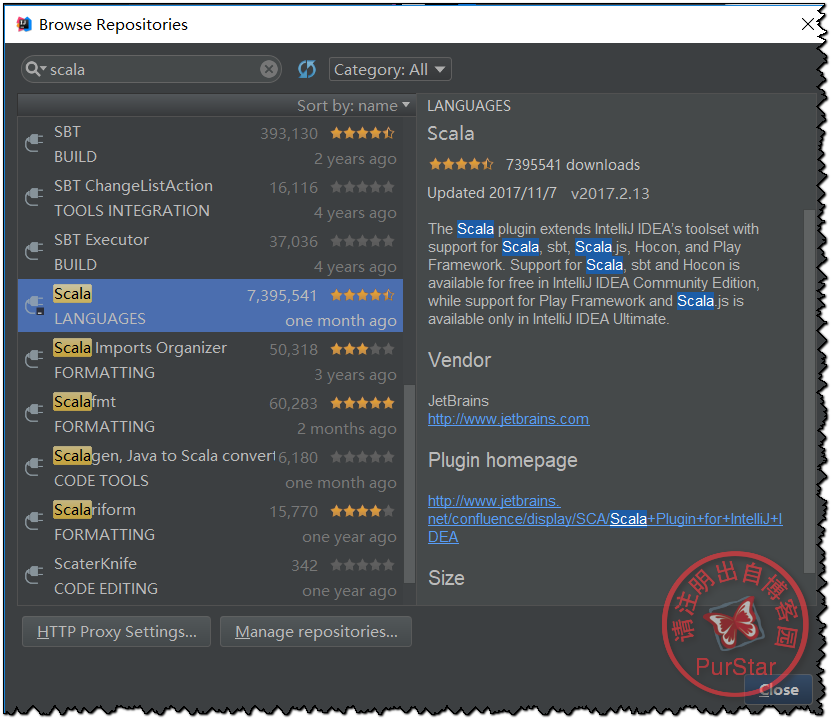
找到下图这一项,点击“install”即可
安装完成后,请重启IDEA。
二、创建一个Scala工程
依次点击Create New Project ——>Scala——>IDEA——>Next
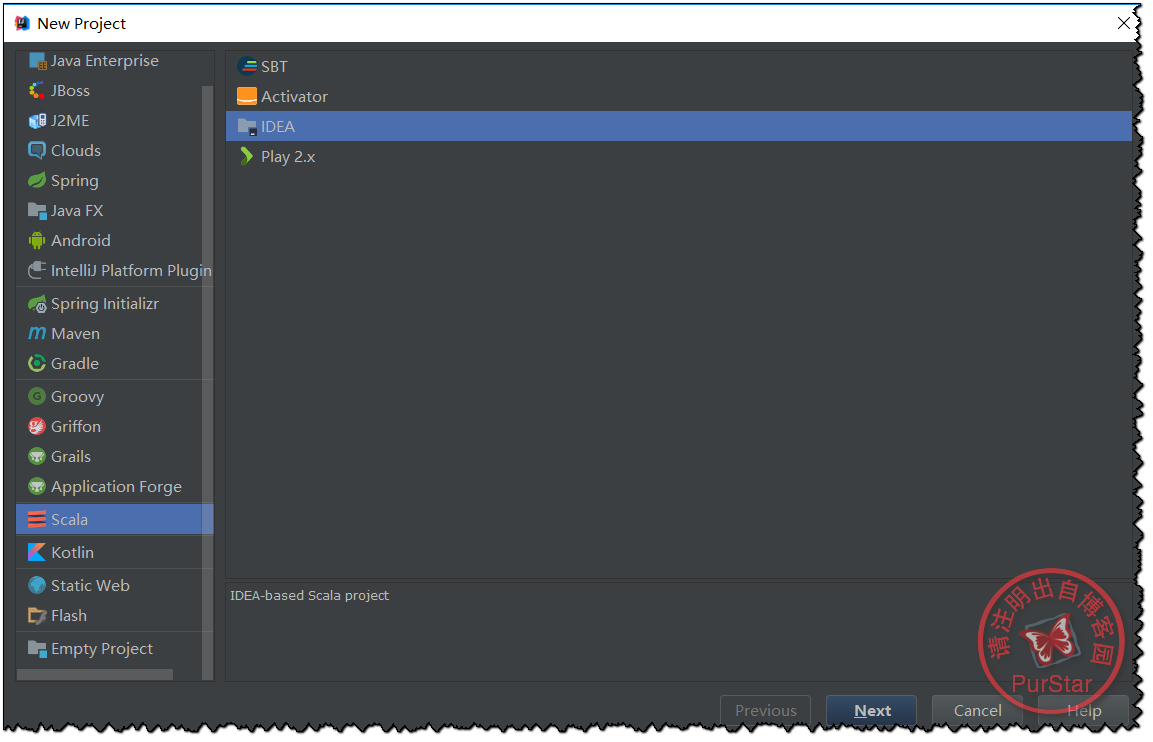
然后我们需要点击create,增加相应的SDK版本及位置。
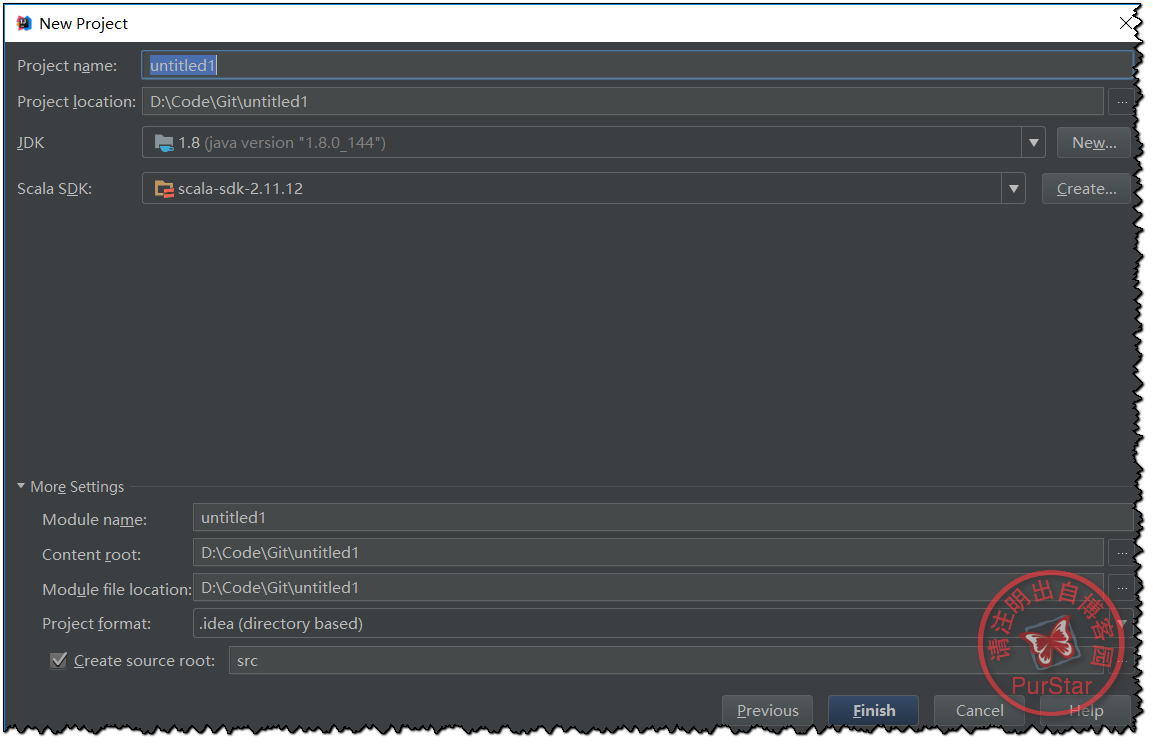
自己填写好其他信息后就可以,点击Finish了。
三、添加Maven框架以及编写pom.xml
首先右键项目名然后选择Add Framework Support...

然后找到maven打钩,点击Ok即可.
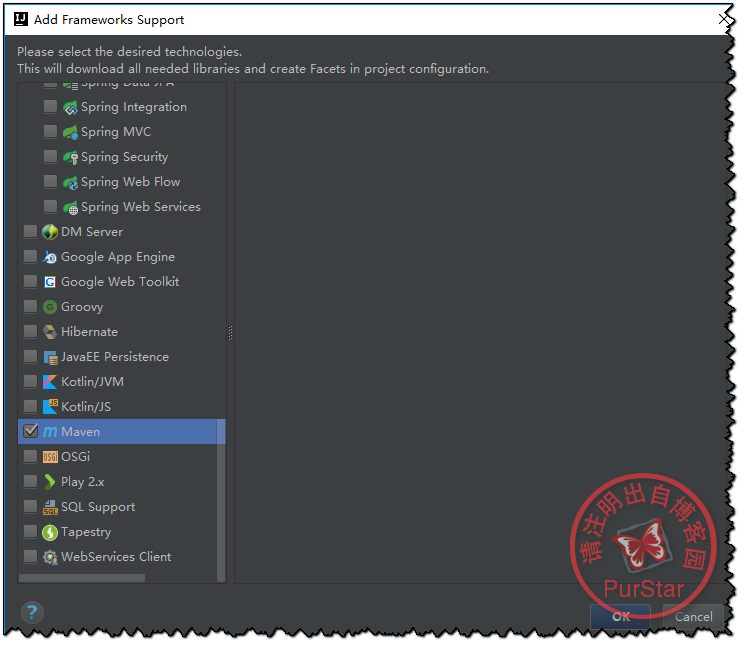
接下来,编写Pom.xml,如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>com.sudy</groupId>
<artifactId>SparkStudy</artifactId>
<version>1.0-SNAPSHOT</version> <properties>
<spark.version>2.2.0</spark.version>
<scala.version>2.11</scala.version>
</properties> <dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency> </dependencies> <build>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin> <plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin> <plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<configuration>
<skip>true</skip>
</configuration>
</plugin> </plugins>
</build> </project>
四、添加winutils.exe文件
winutils.exe下载地址:
https://codeload.github.com/srccodes/hadoop-common-2.2.0-bin/zip/master
解压后,记住放入的路径就好。
五、使用local模式测试环境是否搭建成功?
右键java文件夹,依次点击New——>Scala Class

然后选择Object,输入名称即可。
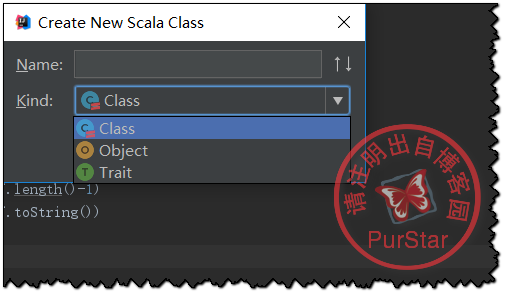
写入测试代码:
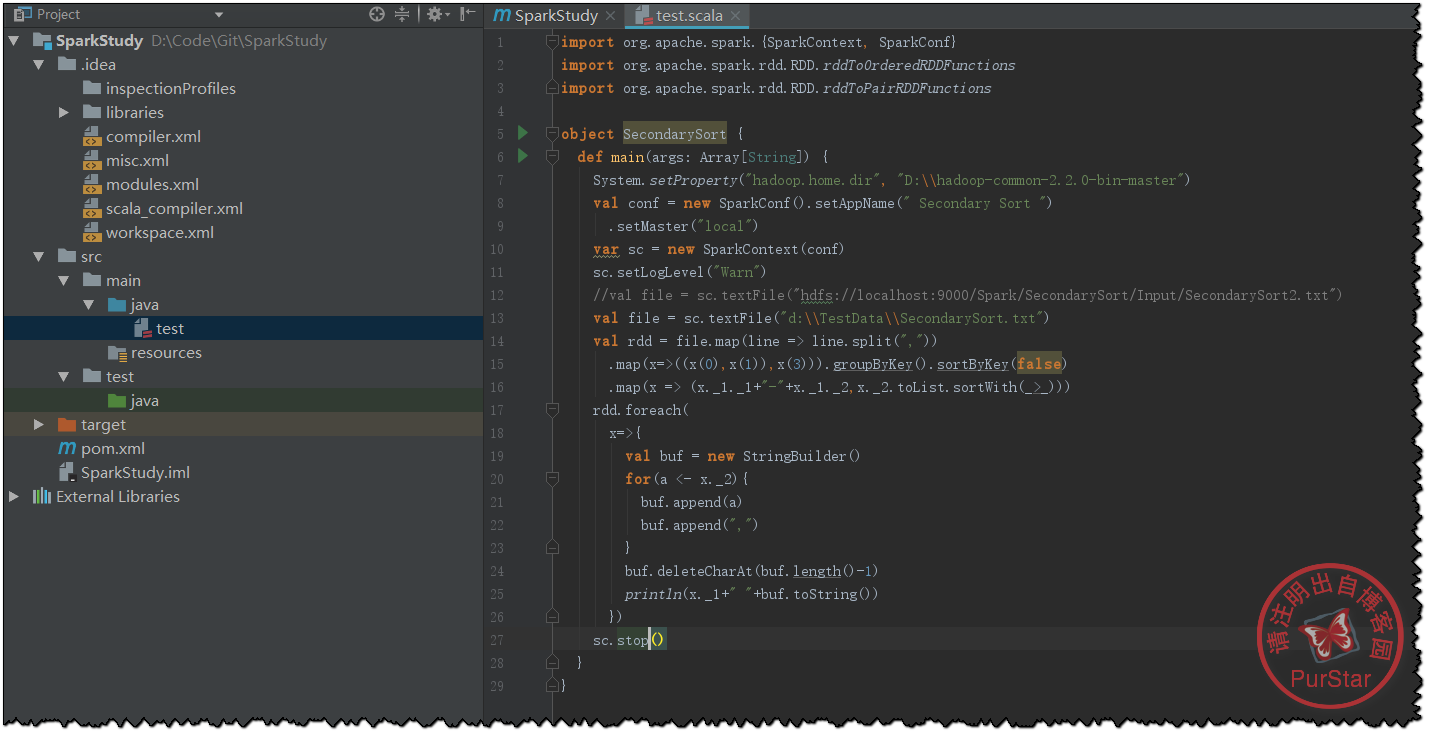
测试代码部分可以参照我之前写的一篇博客的后半部分:
分别使用Hadoop和Spark实现二次排序
为了大家方便这里复制出代码和测试文本:
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.rdd.RDD.rddToOrderedRDDFunctions
import org.apache.spark.rdd.RDD.rddToPairRDDFunctions
object SecondarySort {
def main(args: Array[String]) {
System.setProperty("hadoop.home.dir", "D:\\hadoop-common-2.2.0-bin-master")
val conf = new SparkConf().setAppName(" Secondary Sort ")
.setMaster("local")
var sc = new SparkContext(conf)
sc.setLogLevel("Warn")
//val file = sc.textFile("hdfs://localhost:9000/Spark/SecondarySort/Input/SecondarySort2.txt")
val file = sc.textFile("d:\\TestData\\SecondarySort.txt")
val rdd = file.map(line => line.split(","))
.map(x=>((x(0),x(1)),x(3))).groupByKey().sortByKey(false)
.map(x => (x._1._1+"-"+x._1._2,x._2.toList.sortWith(_>_)))
rdd.foreach(
x=>{
val buf = new StringBuilder()
for(a <- x._2){
buf.append(a)
buf.append(",")
}
buf.deleteCharAt(buf.length()-1)
println(x._1+" "+buf.toString())
})
sc.stop()
}
}
测试文本如下:
2000,12,04,10
2000,11,01,20
2000,12,02,-20
2000,11,07,30
2000,11,24,-40
2012,12,21,30
2012,12,22,-20
2012,12,23,60
2012,12,24,70
2012,12,25,10
2013,01,23,90
2013,01,24,70
2013,01,20,-10
注意:
D:\\hadoop-common-2.2.0-bin-master 是我解压后放入的路径。
d:\\TestData\\SecondarySort.txt 是测试数据的位置,用于程序的运行。 好了,这篇文章结束了,剩下就是你的动手操作了。
参考:
2017.10最新Spark、IDEA、Scala环境搭建
【spark】创建一个基于maven的spark项目所需要的pom.xml文件模板
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries
Spark2.2,IDEA,Maven开发环境搭建附测试的更多相关文章
- Spark Idea Maven 开发环境搭建
一.安装jdk jdk版本最好是1.7以上,设置好环境变量,安装过程,略. 二.安装Maven 我选择的Maven版本是3.3.3,安装过程,略. 编辑Maven安装目录conf/settings.x ...
- Scala java maven开发环境搭建
基于maven配置的scala开发环境,首先需要安装 idea 的scala plugin.然后就可以使用maven编译scala程序了.一般情况下都是java scala的混合,所以src下 ...
- Eclipse+maven开发环境搭建
版本描述: Eclipse 3.2.2 Maven 2.0.7 Jdk 1.5以上,本例是在jdk1.50版本测试通过 Maven配置过程 Maven官方下载地址:http://www.apache. ...
- Maven开发环境搭建
配置Maven流程: 1.下载Maven,官网:http://maven.apache.org/ 2.安装到本地: 1 ).解压apache-maven-x.x.x-bin.zip文件 2 ).配置M ...
- OpenCV开发环境搭建-并测试一个图像灰度处理程序
转载地址:http://blog.csdn.net/sjz_iron/article/details/8614070
- Qt for Android开发环境搭建及测试过程记录
最近学习了Qt的QML编程技术,感觉相较于以前的QtGUI来说更方便一些,使用QML可以将界面与业务逻辑解耦,便于开发. QML支持跨平台,包括支持Android平台,因此可以使用Qt的QML进行An ...
- Spark+ECLIPSE+JAVA+MAVEN windows开发环境搭建及入门实例【附详细代码】
http://blog.csdn.net/xiefu5hh/article/details/51707529 Spark+ECLIPSE+JAVA+MAVEN windows开发环境搭建及入门实例[附 ...
- Centos 基础开发环境搭建之Maven私服nexus
hmaster 安装nexus及启动方式 /usr/local/nexus-2.6.3-01/bin ./nexus status Centos 基础开发环境搭建之Maven私服nexus . 软件 ...
- Hadoop项目开发环境搭建(Eclipse\MyEclipse + Maven)
写在前面的话 可详细参考,一定得去看 HBase 开发环境搭建(Eclipse\MyEclipse + Maven) Zookeeper项目开发环境搭建(Eclipse\MyEclipse + Mav ...
随机推荐
- c#中通过事件实现按下回车跳转控件
//接受用户输入参数后回车事件 private void tb_KeyPress(object sender, KeyPressEventArgs e) { ) { SendKeys.Send(&qu ...
- Oracle,sqlserver,mySQl的区别和联系:
1.日期处理方式 2.对保留字和关键字的处理方式: Oracle,sqlserver,mySQl的保留字不可以用作列字段,关键字可以,但他们对关键字的处理方式又不同: Oracle:关键字作为列时:用 ...
- Bequeath Connection and SYS Logon
The following example illustrates how to use the internal_logon and SYSDBA arguments to specify the ...
- 原型&&原型链一语道破梦中人
一直对原型和原型链模模糊糊,今天看到一句话,通过这句话再结合我目前对原型和原型链的理解算是让我对原型和原型链有一个更清醒的认识;并且记忆更加深刻; 任何一个对象都有一个隐式原型:__proto__属性 ...
- unigui菜单【3】
unigui菜单TuniTreeView 根据数据库表中的内容,显示菜单的处理: function TMainForm.CreateMenu: Integer; var myMenuPoint : P ...
- 微信小程序如何引用iconfont图标
最近在研究微信小程序,自己写demo的时候想要引用巴里巴巴图标库的图标,于是: @font-face { font-family: 'iconfont'; src: url('iconfont.eot ...
- 2.1.6、SparkEnv中创建ShuffleManager
ShuffleManager负责管理本地以及远程的block数据的shuffle操作. ShffuleManager的创建是在SparkEnv中. // Let the user specify sh ...
- 洛谷 P2827 BZOJ 4721 UOJ #264 蚯蚓
题目描述 本题中,我们将用符号表示对c向下取整,例如:. 蛐蛐国最近蚯蚓成灾了!隔壁跳蚤国的跳蚤也拿蚯蚓们没办法,蛐蛐国王只好去请神刀手来帮他们消灭蚯蚓. 蛐蛐国里现在共有n只蚯蚓(n为正整数).每只 ...
- Java中处理线程同步
引自:http://blog.csdn.net/aaa1117a8w5s6d/article/details/8295527和http://m.blog.csdn.net/blog/undoner/1 ...
- 开源GIS软件 2
Android上的导航软件 AndNav AndNav 是一款 Android 手机上的 GPS导航软件(非开源).软件支持GPS定位信息,目的地查询,道路建议管理,导航提示等功能,十分强大的一款软件 ...