【转】Mysql索引最左匹配原则理解
作者:沈杰
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`cid` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `name_cid_INX` (`name`,`cid`),
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8
索引方面:id是主键,(name,cid)是一个多列索引。
-----------------------------------------------------------------------------
下面是你有疑问的两个查询:
EXPLAIN SELECT * FROM student WHERE cid=1;
<img src="https://pic1.zhimg.com/d3086a6c81bb2c77796cfc2249b610bc_b.png" data-rawwidth="1033" data-rawheight="60" class="origin_image zh-lightbox-thumb" width="1033" data-original="https://pic1.zhimg.com/d3086a6c81bb2c77796cfc2249b610bc_r.png">
EXPLAIN SELECT * FROM student WHERE cid=1 AND name='小红';
<img src="https://pic3.zhimg.com/53ab2cdea64b7e58e66c4ef86aa6b06a_b.png" data-rawwidth="1033" data-rawheight="49" class="origin_image zh-lightbox-thumb" width="1033" data-original="https://pic3.zhimg.com/53ab2cdea64b7e58e66c4ef86aa6b06a_r.png">
你的疑问是:sql查询用到索引的条件是必须要遵守最左前缀原则,为什么上面两个查询还能用到索引?
---------------------------------------------------------------------------------------------------------------------------
讲上面问题之前,我先补充一些知识,因为我觉得你对索引理解是狭隘的:
上述你的两个查询的explain结果中显示用到索引的情况类型是不一样的。,可观察explain结果中的type字段。你的查询中分别是:
1. type: index
2. type: ref
解释:
index:这种类型表示是mysql会对整个该索引进行扫描。要想用到这种类型的索引,对这个索引并无特别要求,只要是索引,或者某个复合索引的一部分,mysql都可能会采用index类型的方式扫描。但是呢,缺点是效率不高,mysql会从索引中的第一个数据一个个的查找到最后一个数据,直到找到符合判断条件的某个索引。
所以:对于你的第一条语句:
EXPLAIN SELECT * FROM student WHERE cid=1;
判断条件是cid=1,而cid是(name,cid)复合索引的一部分,没有问题,可以进行index类型的索引扫描方式。explain显示结果使用到了索引,是index类型的方式。
---------------------------------------------------------------------------------------------------------------------------
ref:这种类型表示mysql会根据特定的算法快速查找到某个符合条件的索引,而不是会对索引中每一个数据都进行一 一的扫描判断,也就是所谓你平常理解的使用索引查询会更快的取出数据。而要想实现这种查找,索引却是有要求的,要实现这种能快速查找的算法,索引就要满足特定的数据结构。简单说,也就是索引字段的数据必须是有序的,才能实现这种类型的查找,才能利用到索引。
有些了解的人可能会问,索引不都是一个有序排列的数据结构么。不过答案说的还不够完善,那只是针对单个索引,而复合索引的情况有些同学可能就不太了解了。
下面就说下复合索引:
以该表的(name,cid)复合索引为例,它内部结构简单说就是下面这样排列的:
<img src="https://pic2.zhimg.com/8c45fe417afbe97127e8c55fe1cd9395_b.png" data-rawwidth="149" data-rawheight="205" class="content_image" width="149">mysql创建复合索引的规则是首先会对复合索引的最左边的,也就是第一个name字段的数据进行排序,在第一个字段的排序基础上,然后再对后面第二个的cid字段进行排序。其实就相当于实现了类似 order by name cid这样一种排序规则。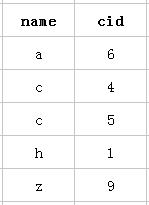
mysql创建复合索引的规则是首先会对复合索引的最左边的,也就是第一个name字段的数据进行排序,在第一个字段的排序基础上,然后再对后面第二个的cid字段进行排序。其实就相当于实现了类似 order by name cid这样一种排序规则。
所以:第一个name字段是绝对有序的,而第二字段就是无序的了。所以通常情况下,直接使用第二个cid字段进行条件判断是用不到索引的,当然,可能会出现上面的使用index类型的索引。这就是所谓的mysql为什么要强调最左前缀原则的原因。
那么什么时候才能用到呢?
当然是cid字段的索引数据也是有序的情况下才能使用咯,什么时候才是有序的呢?观察可知,当然是在name字段是等值匹配的情况下,cid才是有序的。发现没有,观察两个name名字为 c 的cid字段是不是有序的呢。从上往下分别是4 5。
这也就是mysql索引规则中要求复合索引要想使用第二个索引,必须先使用第一个索引的原因。(而且第一个索引必须是等值匹配)。
---------------------------------------------------------------------------------------------------------------------------
所以对于你的这条sql查询:
EXPLAIN SELECT * FROM student WHERE cid=1 AND name='小红';
没有错,而且复合索引中的两个索引字段都能很好的利用到了!因为语句中最左面的name字段进行了等值匹配,所以cid是有序的,也可以利用到索引了。
你可能会问:我建的索引是(name,cid)。而我查询的语句是cid=1 AND name='小红'; 我是先查询cid,再查询name的,不是先从最左面查的呀?
好吧,我再解释一下这个问题:首先可以肯定的是把条件判断反过来变成这样 name='小红' and cid=1; 最后所查询的结果是一样的。
那么问题产生了?既然结果是一样的,到底以何种顺序的查询方式最好呢?
所以,而此时那就是我们的mysql查询优化器该登场了,mysql查询优化器会判断纠正这条sql语句该以什么样的顺序执行效率最高,最后才生成真正的执行计划。所以,当然是我们能尽量的利用到索引时的查询顺序效率最高咯,所以mysql查询优化器会最终以这种顺序进行查询执行。
【转】Mysql索引最左匹配原则理解的更多相关文章
- Mysql索引最左匹配原则
先来看个例子: 1. 示例1:假设有如下的一张表: DROP TABLE IF EXISTS testTable; CREATE TABLE testTable ( ID BIGINT NOT NUL ...
- 【转】mysql索引最左匹配原则的理解
作者:沈杰 链接:https://www.zhihu.com/question/36996520/answer/93256153 来源:知乎 CREATE TABLE `student` ( `id` ...
- mysql索引最左匹配原则的理解
CREATE TABLE `student` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, `ci ...
- mysql索引最左匹配的理解(转载于知乎回答)
作者:沈杰链接:https://www.zhihu.com/question/36996520/answer/93256153来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出 ...
- MySQL组合索引最左匹配原则
几个重要的概念 1.对于mysql来说,一条sql中,一个表无论其蕴含的索引有多少,但是有且只用一条. 2.对于多列索引来说(a,b,c)其相当于3个索引(a),(a,b),(a,b,c)3个索引,又 ...
- MySQL索引最左原则
通过实例理解单列索引.多列索引以及最左前缀原则 实例:现在我们想查出满足以下条件的用户id: 因为我们不想扫描整表,故考虑用索引. 单列索引: ALTER TABLE people ADD INDEX ...
- mysql 索引最左原则原理
索引本质是一棵B+Tree,联合索引(col1, col2,col3)也是. 其非叶子节点存储的是第一个关键字的索引,而叶节点存储的则是三个关键字col1.col2.col3三个关键字的数据,且按照c ...
- mysql索引作用的简单理解
转自:http://blog.csdn.net/pengsidong/article/details/62104703,有添加 索引好比书的目录,好比新华字典的拼音.偏旁部首查字,可以帮助人快速查找到 ...
- Mysql最左匹配原则实践(原创)
mysql最左匹配原则 什么叫最左匹配原则 最左匹配原则的误区 实战 结论: 1 条件查询中条件顺序没有关系 2 在最左匹配原则中,有如下说明: 最左前缀匹配原则,非常重要的原则,mysql会一直向右 ...
随机推荐
- 【 D3.js 入门系列 --- 0 】 简介及安装
家是我的个人博客: http://www.ourd3js.com/ ,csdn博客首页为:http://blog.csdn.net/lzhlzz/.转载请注明出处,谢谢. D3的全称是(Data-D ...
- android网络开源框架volley(五岁以下儿童)——volley一些细节
最近的一次volley整理出下一个.我以前没有再次遭遇了一些小问题,在该记录: 1.HttpUrlConnection DELETE 信息不能加入body问题:java.net.ProtocolExc ...
- BLAS 与 Intel MKL 数学库
0. BLAS BLAS(Basic Linear Algebra Subprograms)描述和定义线性代数运算的规范(specification),而不是一种具体实现,对其的实现包括: AMD C ...
- WPF中制作无边框窗体
原文:WPF中制作无边框窗体 众所周知,在WinForm中,如果要制作一个无边框窗体,可以将窗体的FormBorderStyle属性设置为None来完成.如果要制作成异形窗体,则需要使用图片或者使用G ...
- ubuntu12.04单卡server(mentohust认证)再加上交换机做路由软件共享上网
最近成立了实验室的网络环境中,通过交换机连接的所有主机实验室.想要一个通过该server(单卡)做网关,使用mentohust认证外网,然后内网中的其它主机通过此网关来连接外网. 1.首先在serve ...
- OpenGL(八) 显示列表
OpenGL在即时模式(Immediate Mode)下绘图时,程序中每条语句产生的图形对象被直接送进绘图流水线,在显示终端立即绘制出来.当需要在程序中多次绘制同一个复杂的图像对象时,这种即时模式会消 ...
- GFS读后笔记
GFS读后笔记 Q&A 为什么存储三个副本?而不是两个或者四个? ANS: 可能取得某些平衡点 Chunk的大小为何选择64MB?这个选择主要基于哪些考虑? ANS: GFS主要支持appen ...
- CSS position财产
CSS在position位置信息要素用于表示属性. 有三个起飞值:static, absolute, relative. 假设元件不显式配置position财产,该元素默认position 值至sta ...
- 形态学-扩大-C代码
直接在代码,难.他们明白: void MorhpolotyDilate_ChenLee(unsigned char* pBinImg, int imgW, int imgH, Tpoint* mask ...
- VS发布到IIS Express外网Debug(如微信开发)
主要效果是本机调试网站,将网站发布到某域名(如m16758r728.iok.la),可以进入VS断点,不必再用远程调试!!! 环境 VS2015windows 10操作系统花生壳(可以用其他内网穿透的 ...