史林枫:开源HtmlAgilityPack公共小类库封装 - 网页采集(爬虫)辅助解析利器【附源码+可视化工具推荐】
做开发的,可能都做过信息采集相关的程序,史林枫也经常做一些数据采集或某些网站的业务办理自动化操作软件。
获取目标网页的信息很简单,使用网络编程,利用HttpWebResponse、HttpWebRequest和WebClient就可以了。
复杂的是获取网页内容后,需要对关键信息进行过滤,最初史林枫主要使用正则表达式来匹配目标数据。
这样的匹配也能达到目的,但对于不熟悉正则表达式的开发者或初学者就比较吃力了,尤其是比较复杂的正则。
最好要有专门的工具先测试,再把正则放到程序中测试。这里推荐RegexTester.exe。
后来,一次偶然的机会接触到HtmlAgilityPack。这是个开源的类库。想研究源码的可以移步这里:HtmlAgilityPack源码
刚开始使用是比较随性的,需要用了就开始new 然后找跟节点,找目标节点,取属性或取文本。使用的多了,就有封装类库的想法,然后在使用过程中不断改进,更新,目前使用还是比较稳定的。
使用的时候需要引用HtmlAgilityPack.dll Visual Studio中的NuGet可以获取到
先上类库源码:
/// <summary>
/// html文档解析辅助类库
/// </summary>
public class HtmlParse {
private readonly HtmlDocument doc = new HtmlDocument(); /// <summary>
/// 构造函数 初始化文档并解析 默认utf-8模式
/// </summary>
/// <param name="htmlOrUrl">获取的html字符串或url链接</param>
public HtmlParse(string htmlOrUrl) {
InitDoc(htmlOrUrl);
} /// <summary>
/// 构造函数 初始化文档并解析 默认utf-8模式
/// </summary>
/// <param name="htmlOrUrl">获取的html字符串或url链接</param>
/// <param name="encode">字符编码</param>
public HtmlParse(string htmlOrUrl, string encode) {
InitDoc(htmlOrUrl, encode);
} /// <summary>
/// 根据url或html字符串获取文档并解析
/// </summary>
/// <param name="htmlOrUrl">html字符串或url</param>
/// <param name="encode">网站编码</param>
/// <returns></returns>
public HtmlDocument InitDoc(string htmlOrUrl, string encode = "utf-8") {
if (htmlOrUrl.Trim().StartsWith("http")) {
htmlOrUrl = NetHelper.GetPageStr(htmlOrUrl, "", encode);
}
doc.LoadHtml(htmlOrUrl);
return doc;
} /// <summary>
/// 获取节点集合
/// </summary>
/// <param name="xPath"></param>
/// <returns></returns>
public HtmlNodeCollection GetNodes(string xPath) {
return doc.DocumentNode.SelectNodes(xPath);
} /// <summary>
/// 获取单个节点
/// </summary>
/// <param name="xPath"></param>
/// <returns></returns>
public HtmlNode GetNode(string xPath) {
return doc.DocumentNode.SelectSingleNode(xPath);
} /// <summary>
/// 获取节点的属性值
/// </summary>
/// <param name="node">节点</param>
/// <param name="attrName">属性名称</param>
/// <returns></returns>
public string GetNodeAttr(HtmlNode node, string attrName) {
if (node == null || node.Attributes[attrName] == null) {
return string.Empty;
}
return node.Attributes[attrName].Value;
} /// <summary>
/// 获取节点的InnerText的值
/// </summary>
/// <param name="node"></param>
/// <returns></returns>
public string GetNodeText(HtmlNode node) {
if (node == null) {
return string.Empty;
}
return node.InnerText;
} /// <summary>
/// 获取节点的InnerHtml或OuterHtml值
/// </summary>
/// <param name="node">节点</param>
/// <param name="isOuter">是否要获取OuterHtml</param>
/// <returns></returns>
public string GetNodeHtml(HtmlNode node, bool isOuter = false) {
if (node == null) {
return string.Empty;
}
if (isOuter) {
return node.OuterHtml;
}
return node.InnerHtml;
} /// <summary>
/// 根据Xpath和属性名称获取属性值
/// </summary>
/// <param name="xPath"></param>
/// <param name="attrName"></param>
/// <returns></returns>
public string GetNodeAttr(string xPath, string attrName) {
var node = GetNode(xPath);
return GetNodeAttr(node, attrName);
} /// <summary>
/// 根据XPath获取节点的InnerText
/// </summary>
/// <param name="xPath"></param>
/// <returns></returns>
public string GetNodeText(string xPath) {
var node = GetNode(xPath);
return GetNodeText(node);
} /// <summary>
/// 根据XPath获取节点的InnerHtml或OuterHtml值
/// </summary>
/// <param name="xPath"></param>
/// <param name="isOuter"></param>
/// <returns></returns>
public string GetNodeHtml(string xPath, bool isOuter = false) {
var node = GetNode(xPath);
return GetNodeHtml(node);
}
}
提示:想要熟练的使用HtmlAgilityPack,必须要了解XPath的相关知识。不懂的可以移步这里:XPath入门教程
实际上XPath主要注意几个要点就可以解决80%的问题。
1.以/开头的是从根节点开始选取,以//开头的是模糊选取,而不考虑它们的位置
2.可以使用属性来定位要选取的节点或节点集合 比如//span[@class="time"] 就是选择文档中所有class="time"的span元素。
3.节点集合中的某一个使用[i]的方式选取 比如 //span[@class="time"][1] 就是选择文档中所有class="time"的span元素中的第一个span。注意在这里选择节点的索引是从1开始的,而不是0
4.使用| 来做容错选择,比如一个网页中某个数据可能在<div class="a1"></div>中 也可能在<div class="a2"></div> 这时就可以用 //div[@class="a1"]|//div[@class="a2"] 作为XPath
5.XPath中需要用到的引号 可以使用单引号 因为C#中字符串需要用双引号,XPath中需要引号的使用单引号即可,这样不用转义了。
上面还用到了一个NetHelper。主要用于获取Url的内容。这东西网上一大堆,这里就不献丑了。自行结合即可。
使用方法也很简单:
// 比如这里获取我的博客首页内容 并解析当前文章列表
var doc = new HtmlParse("http://www.cnblogs.com/jayshsoft/");
var nodeList = doc.GetNodes("//div[@class='post post-list-item']");
foreach (var node in nodeList) {
//这里写自己的逻辑
}
自从封装好类库后,采集内容就变得非常Easy了,只要把流程分析好即可,Html文章中的元素任你宰割,蹂躏。。。
另外,推荐一个FireFox浏览器插件:XPath Checker

有了它 你就可以在浏览器中直接写好XPath,直接看到结果 一目了然
直接上图
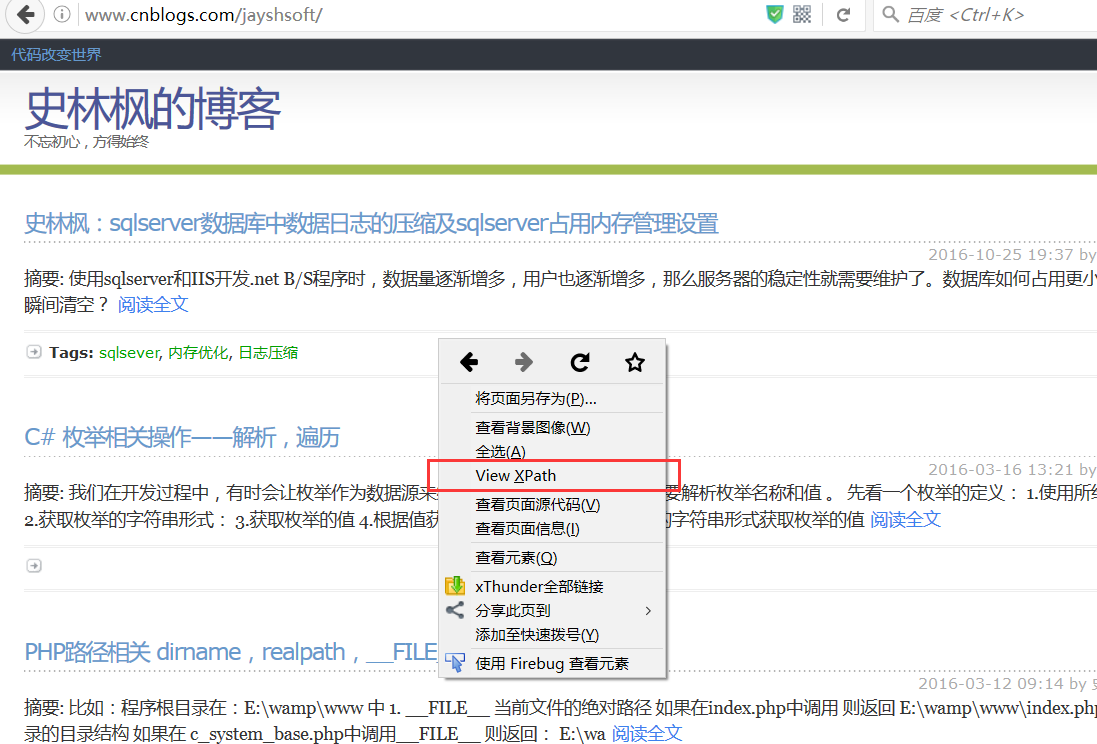
右键点击网页空白处 选择View XPath
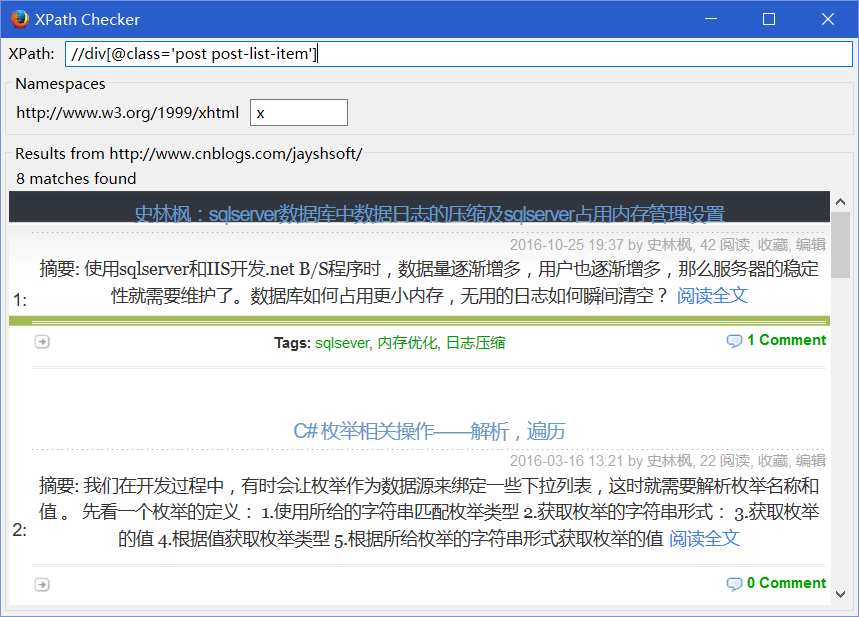
输入XPath 就可以得到你想要的数据了。是不是很直观?是就推荐一下 嘿嘿。。。
史林枫:开源HtmlAgilityPack公共小类库封装 - 网页采集(爬虫)辅助解析利器【附源码+可视化工具推荐】的更多相关文章
- Python的开源人脸识别库:离线识别率高达99.38%(附源码)
Python的开源人脸识别库:离线识别率高达99.38%(附源码) 转https://cloud.tencent.com/developer/article/1359073 11.11 智慧上云 ...
- 微信小程序版博客——开发汇总总结(附源码)
花了点时间陆陆续续,拼拼凑凑将我的小程序版博客搭建完了,这里做个简单的分享和总结. 整体效果 对于博客来说功能页面不是很多,且有些限制于后端服务(基于ghost博客提供的服务),相关样式可以参考截图或 ...
- Java豆瓣电影爬虫——小爬虫成长记(附源码)
以前也用过爬虫,比如使用nutch爬取指定种子,基于爬到的数据做搜索,还大致看过一些源码.当然,nutch对于爬虫考虑的是十分全面和细致的.每当看到屏幕上唰唰过去的爬取到的网页信息以及处理信息的时候, ...
- 开源方案搭建可离线的精美矢量切片地图服务-8.mapbox 之sprite大图图标文件生成(附源码)
项目成果展示(所有项目文件都在阿里云的共享云虚拟主机上,访问地图可以会有点慢,请多多包涵). 01:中国地图:http://test.sharegis.cn/mapbox/html/3china.ht ...
- C#轻量级通通讯组件StriveEngine —— C/S通信开源demo(2) —— 使用二进制协议 (附源码)
前段时间,有几个研究ESFramework通信框架的朋友对我说,ESFramework有点庞大,对于他们目前的项目来说有点“杀鸡用牛刀”的意思,因为他们的项目不需要文件传送.不需要P2P.不存在好友关 ...
- 微信小程序之蓝牙开发(详细读数据、写数据、附源码)
本文将详细介绍微信小程序的蓝牙开发流程(附源码)准备:微信只支持低功耗蓝牙也就是蓝牙4.0,普通的蓝牙模块是用不了的,一定要注意. 蓝牙可以连TTL接到电脑上,再用XCOM调试 一开始定义的变量 va ...
- 日志组件Log2Net的介绍和使用(附源码开源地址)
Log2Net是一个用于收集日志到数据库或文件的组件,支持.NET和.NetCore平台. 此组件自动收集系统的运行日志(服务器运行情况.在线人数等).异常日志.程序员还可以添加自定义日志. 该组件支 ...
- 自制小工具大大加速MySQL SQL语句优化(附源码)
引言 优化SQL,是DBA常见的工作之一.如何高效.快速地优化一条语句,是每个DBA经常要面对的一个问题.在日常的优化工作中,我发现有很多操作是在优化过程中必不可少的步骤.然而这些步骤重复性的执行,又 ...
- JS小游戏:贪吃蛇(附源码)
javascript小游戏:贪吃蛇 此小游戏采用的是面向对象的思想,将蛇,食物,和游戏引擎分为3个对象来写的. 为方便下载,我把js写在了html中, 源码中暂时没有注释,等有空我在添加点注释吧. 游 ...
随机推荐
- 第9章 初识HAL固件库
本章参考资料:<STM32F76xxx参考手册>.<STM32F7xx规格书>.<Cortex-M3权威指南>, STM32 HAL库帮助文档:<STM32F ...
- SQL之Case when 语句
--case简单函数 (把多列变成单列) ' then '女' when ' then '男' else '其他' end from [Northwind].[dbo].[Users] --case搜 ...
- C#静态成员和非静态成员
一.C#静态成员和非静态成员 1. C#静态成员和非静态成员 当类中的某个成员使用static修饰符时,就会被声明为静态成员.类中的成员要么是静态成员,要么是非静态成员.一般情况下,静态成员属于整个类 ...
- python while循环与for循环
今天刚看了一下python的while和for循环,所以打算记录一下: while语句是python中的循环条件语句,while 判断条件 : pass break 例如: i = 1 sum = 1 ...
- this指向问题(2)
4.显示绑定 指的是apply.bind.call (1).apply 和 call 相同点: <1> 这两个方法的用途是在特定的作用域中调用函数,实际上等于设置函数体内 this 对象的 ...
- 【复杂度分析】loj#6043. 「雅礼集训 2017 Day7」蛐蛐国的修墙方案
感觉有点假 题目大意 数据范围:$n<=100$ 题目分析 由于题目给出的是 置换,所以相当于只需枚举每个环的两个状态. 主要是复杂度分析这里: 一元环:不存在 二元环:特判保平安 三元环:不存 ...
- mysql 自增主键为什么不是连续的?
由于自增主键可以让主键索引尽量地保持递增顺序插入,避免了页分裂,因此索引更紧凑 MyISAM 引擎的自增值保存在数据文件中 nnoDB 引擎的自增值,其实是保存在了内存里,并且到了 MySQL 8.0 ...
- 配置intellij idea中的欢迎页而不使用默认的index.jsp
在web.xml中添加 <welcome-file-list> <welcome-file>abc.jsp</welcome-file> </welcome- ...
- 【CodeBase】【转】php随机生成汉字
本方法是通过生成GB2312编码的汉字后,再转码为UTF-8编码.之所以这样做是因为UTF-8的常用汉字太过分散,随机生成会出现大量生僻字,而使用GB2312编码的好处在于其收录的大部分汉字为常用汉字 ...
- 【HTML】placeholder中换行
表示回车 表示换行 案例 <textarea rows="10" placeholder="测试换行 新的一行"></textarea>