2、Spark基本工作原理与RDD
一、基本工作原理
1、特点
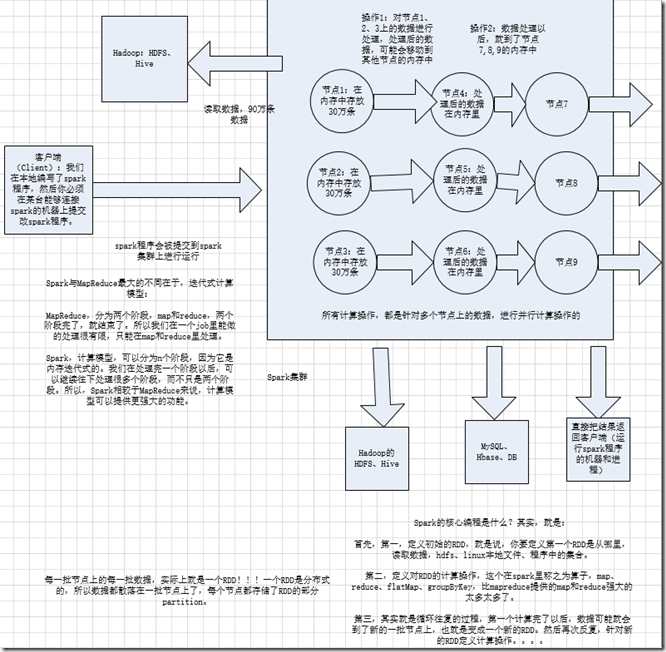
分布式; 主要是基于内存(少数情况基于磁盘); spark与,MapReduce最大的不同在于迭代式计算; MR分为两个阶段,map和reduce,两个阶段完了,job就结束了,所以我们在一个job里能做的处理很有限,只能是在map和reduce里处理; spark计算模型,可以分为n个阶段,因为它是内存迭代式的,我们在处理完一个阶段以后,可以继续往下处理很多个阶段,而不只是两个阶段,所以,spark相较于MR,
计算模型可以提供更强大的功能
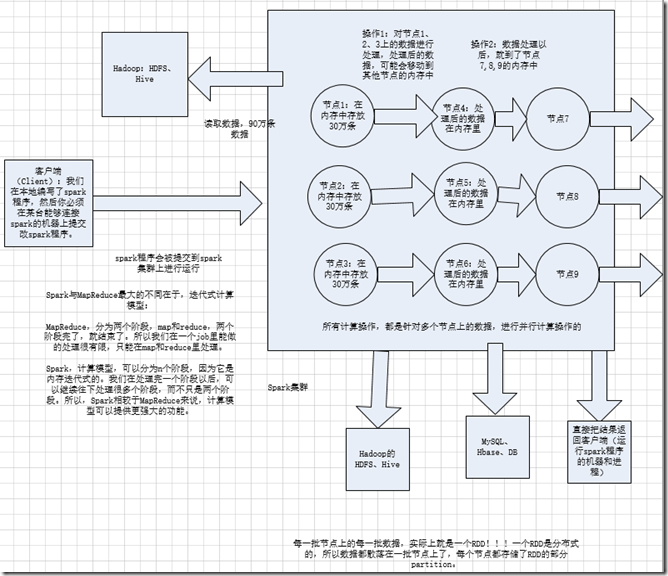
二、RDD
1、
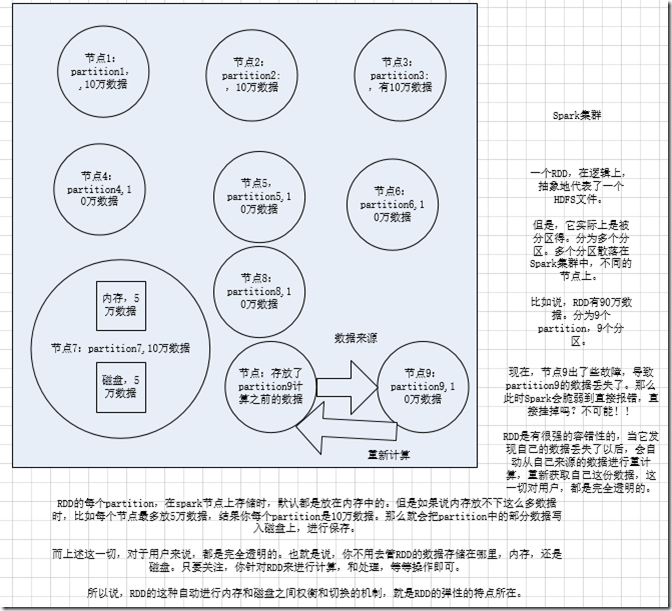
1、RDD是Spark提供的核心抽象,全称为Resillient Distributed Dataset,即弹性分布式数据集。
2、RDD在抽象上来说是一种元素集合,包含了数据。它是被分区的,分为多个分区,每个分区分布在集群中的不同节点上,从而让RDD中的数据可以被并行操作。
(分布式数据集)
3、RDD通常通过Hadoop上的文件,即HDFS文件或者Hive表,来进行创建;有时也可以通过应用程序中的集合来创建。
4、RDD最重要的特性就是,提供了容错性,可以自动从节点失败中恢复过来。即如果某个节点上的RDD partition,因为节点故障,导致数据丢了,那么RDD会自动通过自己的数据来源重新计算该partition。这一切对使用者是透明的。
5、RDD的数据默认情况下存放在内存中的,但是在内存资源不足时,Spark会自动将RDD数据写入磁盘。(弹性)
三、spark编程
1、
1、核心开发:离线批处理 / 延迟性的交互式数据处理
2、SQL查询:底层都是RDD和计算操作
3、实时计算:底层都是RDD和计算操作
2、Spark基本工作原理与RDD的更多相关文章
- 4.Apache Spark的工作原理
Apache Spark的工作原理 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark ...
- 46、Spark SQL工作原理剖析以及性能优化
一.工作原理剖析 1.图解 二.性能优化 1.设置Shuffle过程中的并行度:spark.sql.shuffle.partitions(SQLContext.setConf()) 2.在Hive数据 ...
- Spark Streaming初步使用以及工作原理详解
在大数据的各种框架中,hadoop无疑是大数据的主流,但是随着电商企业的发展,hadoop只适用于一些离线数据的处理,无法应对一些实时数据的处理分析,我们需要一些实时计算框架来分析数据.因此出现了很多 ...
- spark提交运算原理
前面几天元旦过high了,博客也停了一两天,哈哈,今天我们重新开始,今天我们介绍的是spark的原理 首先先说一个小贴士: spark中,对于var count = 0,如果想使count自增,我们不 ...
- Hive架构与工作原理
组成及作用: 用户接口:ClientCLI(hive shell).JDBC/ODBC(java访问hive).WEBUI(浏览器访问hive) 元数据:Metastore 元数据包括:表名.表所属的 ...
- 【原】Learning Spark (Python版) 学习笔记(三)----工作原理、调优与Spark SQL
周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =.这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark ...
- 49、Spark Streaming基本工作原理
一.大数据实时计算介绍 1.概述 Spark Streaming,其实就是一种Spark提供的,对于大数据,进行实时计算的一种框架.它的底层,其实,也是基于我们之前讲解的Spark Core的. 基本 ...
- Spark基本工作流程及YARN cluster模式原理(读书笔记)
Spark基本工作流程及YARN cluster模式原理 转载请注明出处:http://www.cnblogs.com/BYRans/ Spark基本工作流程 相关术语解释 Spark应用程序相关的几 ...
- 一图看懂hadoop Spark On Yarn工作原理
hadoop Spark On Yarn工作原理
随机推荐
- 如何在 Eclipse 中使用命令行
虽然我们已经有了像 Eclipse 这样高级的 IDE,但是我们有时候也是需要在开发的时候使用 Windows 的命令行,来运行一些独立的程序.在两个程序中切换来切换去是很麻烦的.所以 Eclipse ...
- hd acm1048
Problem Description Julius Caesar lived in a time of danger and intrigue. The hardest situation Caes ...
- Oracle角色管理
--创建角色 create role role_name [not identified |--无需验证的方式 identified by [password]--密码验证的方式 | identifi ...
- BZOJ 3626 [LNOI2014]LCA:树剖 + 差分 + 离线【将深度转化成点权之和】
题目链接:http://www.lydsy.com/JudgeOnline/problem.php?id=3626 题意: 给出一个n个节点的有根树(编号为0到n-1,根节点为0,n <= 50 ...
- java中properties
一.Java Properties类 Java中有个比较重要的类Properties(Java.util.Properties),主要用于读取Java的配置文件,各种语言都有自己所支持的配置文件,配置 ...
- R基础之批处理--R IN ACTION
1.5 批处理多数情况下,我们都会交互式地使用R:在提示符后输入命令,接着等待该命令的输出结果.偶尔,我们可能想要以一种重复的.标准化的.无人值守的方式执行某个R程序,例如,你可能需要每个月生成一次相 ...
- django使用bootstrap前端框架
一.下载bootstrap相关文件,放在项目目录中.在blog 应用中新建static目录,bootstrap文件放在此目录下. bootstrap下载网址:http://v3.bootcss.com ...
- HashMap,Hashtable,TreeMap ,Map
package com.wzy.list; import java.util.HashMap; import java.util.Hashtable; import java.util.Iterato ...
- numpy.ndarray类型的数组元素输出时,保留小数点后4位
因为计算结果数组中每个值都是很长的一串小数,看起来比较乱,想格式化一下输出方式. 这是个看起来很简单的问题,但是方法找了很久. 方法也是看起来很简单,用 numpy.set_printoptions( ...
- OpenCV - Windows(win10)编译opencv + opencv_contrib
在之前的几篇文章中,我提到了在Android.Linux中编译opencv + opencv_contrib,这篇文章主要讲在Windows中编译opencv + opencv_contrib. 首先 ...