HDFS写数据和读数据流程
HDFS数据存储
HDFS client上传数据到HDFS时,首先,在本地缓存数据,当数据达到一个block大小时。请求NameNode分配一个block。
NameNode会把block所在的DataNode的地址告诉HDFS client。 HDFS client会直接和DataNode通信,把数据写到DataNode节点一个block文件里。
核心类DistributedFileSystem
HDFS写数据流程
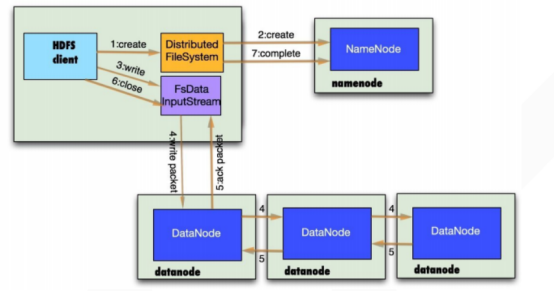
客户端要向HDFS写数据,首先要跟namenode通信以确认可以写文件并获得接收文件block的datanode,然后,
客户端按顺序将文件逐个block传递给相应datanode,并由接收到block的datanode负责向其他datanode复制block的副本。
具体流程如下:
1、与namenode通信请求上传文件,namenode检查目标文件是否已存在,父目录是否存在
2、namenode返回是否可以上传
3、client请求第一个 block该传输到哪些datanode服务器上
4、namenode返回3个datanode服务器ABC
5、client请求3台dn中的一台A上传数据(本质上是一个RPC调用,建立pipeline),A收到请求会继续调用B,然后B调用C,将整个pipeline建立完成,逐级返回客户端
6、client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,A收到一个packet就会传给B,B传给C;A每传一个packet会放入一个应答队列等待应答
7、当一个block传输完成之后,client再次请求namenode上传第二个block的服务器。
HDFS读数据流程
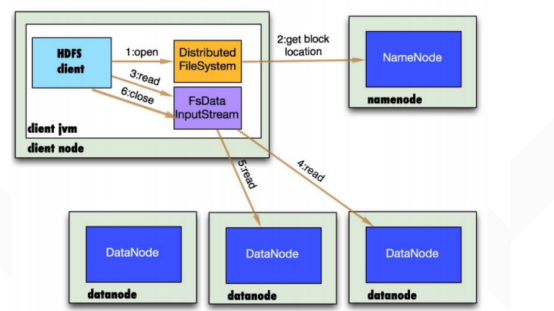
1、 读取文件名称
2、 向namenode获取文件第一批block位置,这个block会根据副本数返回对应数量的locations数,依据网络拓扑结构排序,距离client端的排在前面,
从原理来说,是通过DistributedFileSystem对象调用getFileBlockLocations来获取locations
3、 获取距离clinet最近的datanode并与其建立通信,数据会源源不断的写入clinet端,假设第一个block读取完成,则关闭指向该datanode的连接,接着读取下一个block,以此类推。
假设所有的块都读取完了,则把所有的流都关闭。
实际上,也是通过DistributedFileSystem来open一个流对象,将其封装到DFSInputStream对象当中,block读取可以查看接口BlockReader.
4、如果读取的过程出现DN出现异常(比如通信异常),则会尝试去读取第二个优先位置的datanode,并且记录该错误的datanode,剩余的blocks读取的时候直接跳过该datanode
DFSInputStream也会检查block数据校验和,假设发现一个坏的block,就会先报告到namenode节点,然后DFSInputStream在其它的datanode上读该block的镜像。
HDFS写数据和读数据流程的更多相关文章
- Hadoop(三)HDFS写数据的基本流程
HDFS写数据的流程 HDFS shell上传文件a.txt,300M 对文件分块,默认每块128M. shell向NameNode发送上传文件请求 NameNode检测文件系统目录树,看能否上传 N ...
- Hadoop源码分析之客户端向HDFS写数据
转自:http://www.tuicool.com/articles/neUrmu 在上一篇博文中分析了客户端从HDFS读取数据的过程,下面来看看客户端是怎么样向HDFS写数据的,下面的代码将本地文件 ...
- HDFS写数据的过程
- HDFS 读/写数据流程
1. HDFS 写数据流程 客户端通过 Distributed FileSystem 模块向 NameNode 请求上传文件, NameNode 检查目标文件是否已存在,父目录是否存在: NameNo ...
- HDFS读写数据流程
HDFS的组成 1.NameNode:存储文件的元数据,如文件名,文件目录结构,文件属性(创建时间,文件权限,文件大小) 以及每个文件的块列表和块所在的DataNode等.类似于一本书的目录功能. 2 ...
- 大数据:Hadoop(HDFS 读写数据流程及优缺点)
一.HDFS 写数据流程 写的过程: CLIENT(客户端):用来发起读写请求,并拆分文件成多个 Block: NAMENODE:全局的协调和把控所有的请求,提供 Block 存放在 DataNode ...
- 微信小程序之蓝牙开发(详细读数据、写数据、附源码)
本文将详细介绍微信小程序的蓝牙开发流程(附源码)准备:微信只支持低功耗蓝牙也就是蓝牙4.0,普通的蓝牙模块是用不了的,一定要注意. 蓝牙可以连TTL接到电脑上,再用XCOM调试 一开始定义的变量 va ...
- Linux启动kettle及linux和windows中kettle往hdfs中写数据(3)
在xmanager中的xshell运行进入图形化界面 sh spoon.sh 新建一个job
- HDFS写文件过程分析
转自http://shiyanjun.cn/archives/942.html HDFS是一个分布式文件系统,在HDFS上写文件的过程与我们平时使用的单机文件系统非常不同,从宏观上来看,在HDFS文件 ...
随机推荐
- WebRTC协议
webrtc协议介绍 MDN webrtc协议 ICE 交互式连接建立Interactive Connectivity Establishment (ICE) 是一个允许你的浏览器和对端浏览器建立连接 ...
- C#对bat脚本文件的操作示例
实现C#操作bat脚本文件 using System;using System.Collections.Generic;using System.ComponentModel;using System ...
- 百度开源项目插件 - Echarts 图表
<!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <m ...
- 前端必须要掌握的几个CSS3的属性
随着Css3和html5的风靡,越来越多的前端人员开始学习Css3,今天的文章就是来说说前端应该掌握10个Css3属性. 1. Border-radius Border-radius是一大堆CSS3属 ...
- 智能开关:orange pi one(arm linux)控制继电器
大家都知道,继电器是用小电流去控制大电流运作的一种“自动开关”,在我们生活.工作中随处可见.现在的“智能家居”概念,有很多功能模块其实就是“智能开关”,远程开关.定时开关.条件触发开关等等. 下面介绍 ...
- httpclient使用head添加cookie
最近在使用接口时候,我使用get请求时,需要携带登录态,所以在get请求的时候我需要在head里面把cookie给加上,添加方式get和post完全不一样 Post方式添加cookie httpPos ...
- vue中css动画原理
显示原理: <transition name='fade'> <div v-if='show'>hello world</div> </transition& ...
- ORA-00392: log 4 of thread 2 is being cleared, operation not allowed
alter database open resetlogs或者 alter database open resetlogs upgrade报错:ORA-00392 在rman restore 还原数 ...
- 7 MSSQL数据库备份与恢复
0 MSSQL数据库备份 1 SQLAgent配置 2 设置连接属性 3 输入SA账号密码 4 SQL备份脚本配置 5 生成SQL全量备份脚本 6 生成SQL差异备份脚本 7 修改SQL差异备份脚本 ...
- 【转】Android的setTag
前言 首先我们要知道setTag方法是干什么的,SDK解释为 Tags Unlike IDs, tags are not used to identify views. Tags are essent ...