HDFS写数据和读数据流程
HDFS数据存储
HDFS client上传数据到HDFS时,首先,在本地缓存数据,当数据达到一个block大小时。请求NameNode分配一个block。
NameNode会把block所在的DataNode的地址告诉HDFS client。 HDFS client会直接和DataNode通信,把数据写到DataNode节点一个block文件里。
核心类DistributedFileSystem
HDFS写数据流程
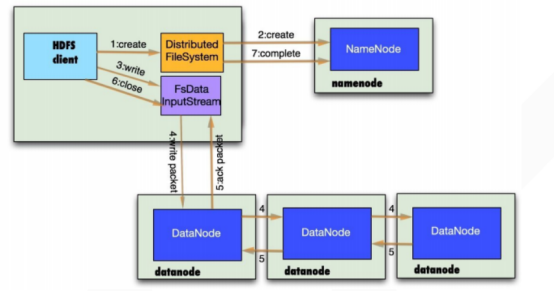
客户端要向HDFS写数据,首先要跟namenode通信以确认可以写文件并获得接收文件block的datanode,然后,
客户端按顺序将文件逐个block传递给相应datanode,并由接收到block的datanode负责向其他datanode复制block的副本。
具体流程如下:
1、与namenode通信请求上传文件,namenode检查目标文件是否已存在,父目录是否存在
2、namenode返回是否可以上传
3、client请求第一个 block该传输到哪些datanode服务器上
4、namenode返回3个datanode服务器ABC
5、client请求3台dn中的一台A上传数据(本质上是一个RPC调用,建立pipeline),A收到请求会继续调用B,然后B调用C,将整个pipeline建立完成,逐级返回客户端
6、client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,A收到一个packet就会传给B,B传给C;A每传一个packet会放入一个应答队列等待应答
7、当一个block传输完成之后,client再次请求namenode上传第二个block的服务器。
HDFS读数据流程
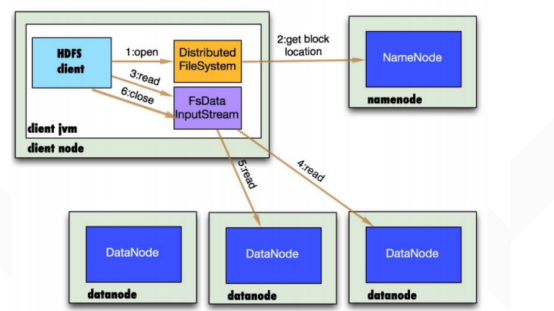
1、 读取文件名称
2、 向namenode获取文件第一批block位置,这个block会根据副本数返回对应数量的locations数,依据网络拓扑结构排序,距离client端的排在前面,
从原理来说,是通过DistributedFileSystem对象调用getFileBlockLocations来获取locations
3、 获取距离clinet最近的datanode并与其建立通信,数据会源源不断的写入clinet端,假设第一个block读取完成,则关闭指向该datanode的连接,接着读取下一个block,以此类推。
假设所有的块都读取完了,则把所有的流都关闭。
实际上,也是通过DistributedFileSystem来open一个流对象,将其封装到DFSInputStream对象当中,block读取可以查看接口BlockReader.
4、如果读取的过程出现DN出现异常(比如通信异常),则会尝试去读取第二个优先位置的datanode,并且记录该错误的datanode,剩余的blocks读取的时候直接跳过该datanode
DFSInputStream也会检查block数据校验和,假设发现一个坏的block,就会先报告到namenode节点,然后DFSInputStream在其它的datanode上读该block的镜像。
HDFS写数据和读数据流程的更多相关文章
- Hadoop(三)HDFS写数据的基本流程
HDFS写数据的流程 HDFS shell上传文件a.txt,300M 对文件分块,默认每块128M. shell向NameNode发送上传文件请求 NameNode检测文件系统目录树,看能否上传 N ...
- Hadoop源码分析之客户端向HDFS写数据
转自:http://www.tuicool.com/articles/neUrmu 在上一篇博文中分析了客户端从HDFS读取数据的过程,下面来看看客户端是怎么样向HDFS写数据的,下面的代码将本地文件 ...
- HDFS写数据的过程
- HDFS 读/写数据流程
1. HDFS 写数据流程 客户端通过 Distributed FileSystem 模块向 NameNode 请求上传文件, NameNode 检查目标文件是否已存在,父目录是否存在: NameNo ...
- HDFS读写数据流程
HDFS的组成 1.NameNode:存储文件的元数据,如文件名,文件目录结构,文件属性(创建时间,文件权限,文件大小) 以及每个文件的块列表和块所在的DataNode等.类似于一本书的目录功能. 2 ...
- 大数据:Hadoop(HDFS 读写数据流程及优缺点)
一.HDFS 写数据流程 写的过程: CLIENT(客户端):用来发起读写请求,并拆分文件成多个 Block: NAMENODE:全局的协调和把控所有的请求,提供 Block 存放在 DataNode ...
- 微信小程序之蓝牙开发(详细读数据、写数据、附源码)
本文将详细介绍微信小程序的蓝牙开发流程(附源码)准备:微信只支持低功耗蓝牙也就是蓝牙4.0,普通的蓝牙模块是用不了的,一定要注意. 蓝牙可以连TTL接到电脑上,再用XCOM调试 一开始定义的变量 va ...
- Linux启动kettle及linux和windows中kettle往hdfs中写数据(3)
在xmanager中的xshell运行进入图形化界面 sh spoon.sh 新建一个job
- HDFS写文件过程分析
转自http://shiyanjun.cn/archives/942.html HDFS是一个分布式文件系统,在HDFS上写文件的过程与我们平时使用的单机文件系统非常不同,从宏观上来看,在HDFS文件 ...
随机推荐
- AOP术语分析
初看这么多术语,一下子都不好接受,慢慢来,很快就会搞懂. 通知.增强处理(Advice) 就是你想要的功能,也就是上说的安全.事物.日子等.你给先定义好,然后再想用的地方用一下.包含Aspect的一段 ...
- Python基础学习之序列(1)
序列 序列类型有着相同的访问模式:它的每一个元素可以通过指定一个偏移量的方式得到.而多个元素可以通过切片操作的方式一次得到,下标偏移量是从0开始到总元素-1结束,之所以要减1是因为我们是从0开始计数的 ...
- ansible安装php
环境:Centos 7.x 独立php-fpm.conf配置文件 [root@master playbook]# tree php php ├── php-fpm.conf └── php.yml p ...
- Wampserver由橙变绿的解决过程
因为C盘的内存问题,就重装了win7系统,那么就面临着很对软件要重新进行安装,安装wampserver时,再次遇到了服务器的图标一直是橙色的而不变绿色,安装包地址: http://download.c ...
- FTP无法连接可能是安全狗设置的原因
防火墙已添加某端口,但仍无法连接.可能是安全狗导致的. 如果安装了安全狗,请按照以下步骤设置:
- COGS2287 [HZOI 2015]疯狂的机器人
[题目描述] 现在在二维平面内原点上有一只机器人 他每次操作可以选择向右走,向左走,向下走,向上走和不走(每次如果走只能走一格) 但是由于本蒟蒻施展的大魔法,机器人不能走到横坐标是负数或者纵坐标是负数 ...
- iOS逆向命令集
越狱命令行 破壳: 10.10.215.119 ssh root@10.10.215.119 ssh root@10.10.213.176 CCBMobileBank Fuqianlade-iPhon ...
- 【转】普及一下ARM和X86的区别,鉴于ATOM已经入驻手机,AMD也会…
这里简单来谈一下,ARM和X86之间为什么不太具有可比性的问题.要搞清楚这个问题首先要明白什么是架构,之前也有很多人提到了架构不同,但架构是什么意思?它是一个比较抽象的概念,不太容易用几句话就解释清楚 ...
- Object类的常用方法
Object类是Java中所有类的始祖.如果没有明确的指定继承,则默认继承Object类.在Java中除了基本类型外都是Object类型的对象,包括数组. 1)equals方法 Object: pub ...
- C#中索引器的实现过程,是否只能根据数字进行索引?
描述一下C#中索引器的实现过程,是否只能根据数字进行索引? 答:索引器是一种特殊的类成员,它能够让对象以类似数组的方式来存取, 使程序看起来更为直观,更容易编写,可以用任意类型.