袋鼠云研发手记 | 开源·数栈-扩展FlinkSQL实现流与维表的join

作为一家创新驱动的科技公司,袋鼠云每年研发投入达数千万,公司80%员工都是技术人员,袋鼠云产品家族包括企业级一站式数据中台PaaS数栈、交互式数据可视化大屏开发平台Easy[V]等产品也在迅速迭代。在进行产品研发的过程中,技术小哥哥们能文能武,不断提升产品性能和体验的同时,也把这些提升和优化过程记录下来,现录入“袋鼠云研发手记”专栏中,以和业内童鞋们分享交流。
下为“袋鼠云研发手记”专栏第三期,本期作者为袋鼠云数栈引擎团队。
袋鼠云数栈引擎团队
袋鼠云数栈引擎团队拥有多名专家级别,经验丰富的后端开发工程师,分别支撑公司大数栈产品线的不同子项目的开发需求,从项目中提取并开源了FlinkX(基于Flink的数据同步),Jlogstash(logstash 的java 版本实现),FlinkStreamSQL(扩展原生FlinkSQL,实现流与维表的join)多个项目。
在长期的项目实践与产品迭代过程中,团队成员在 Hadoop技术栈上不断深耕探索,积累了丰富的经验与最佳实践。
第三期
数栈·开源 拓展FlinkSQL实现流与维表的join
FlinkStreamSQL 已经开源在Github上 目前已获380+Star
1、为什么要扩展FlinkSQL?
实时计算需要完全SQL化
SQL是数据处理中使用最广泛的语言。它允许用户简明扼要地声明他们的业务逻辑。大数据批计算使用SQL很常见,但是支持SQL的实时计算并不多。其实,用SQL开发实时任务可以极大降低数据开发的门槛,在袋鼠云数栈-实时计算模块,我们决定实现完全SQL化。
数据计算采用SQL的优势
☑ 声明式。用户只需要表达我想要什么,至于怎么计算那是系统的事情,用户不用关心。
☑ 自动调优。查询优化器可以为用户的 SQL 生成最有的执行计划。用户不需要了解它,就能自动享受优化器带来的性能提升。
☑ 易于理解。很多不同行业不同领域的人都懂 SQL,SQL 的学习门槛很低,用 SQL 作为跨团队的开发语言可以很大地提高效率。
☑ 稳定。SQL 是一个拥有几十年历史的语言,是一个非常稳定的语言,很少有变动。所以当我们升级引擎的版本时,甚至替换成另一个引擎,都可以做到兼容地、平滑地升级。
实时计算还需要流与维表的JOIN
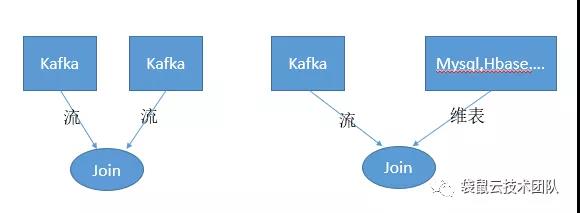
在实时计算的世界里不只是流与流的JOIN
还需要流与维表的JOIN
在实时计算的世界里不只是流与流的JOIN,还需要流与维表的JOIN。在去年,袋鼠云数栈V3.0版本研发期间,当时最新版本——flink1.6中FlinkSQL,已经将SQL的优势应用到Flink引擎中,但还未支持流与维表的JOIN。
关于FlinkSQL
FlinkSQL于2017年7月开始面向阿里巴巴集团开放流计算服务的,虽然是一个非常年轻的产品,但是到双11期间已经支撑了数千个作业,在双11期间,Blink 作业的处理峰值达到了5+亿每秒,而其中仅 Flink SQL 作业的处理总峰值就达到了3亿/秒。
参考链接:https://yq.aliyun.com/articles/457438
这里先解释下什么是维表;维表是动态表,表里所存储的数据有可能不变,也有可能定时更新,但是更新频率不是很频繁。在业务开发中一般的维表数据存储在关系型数据库如mysql,oracle等,也可能存储在hbase,redis等nosql数据库。
2、所以要用FlinkSQL实现流与维表的join 分两步:
一、用Flink api实现维表的功能
要实现维表功能就要用到 Flink Aysnc I/O 这个功能,是由阿里巴巴贡献给Apache Flink的。
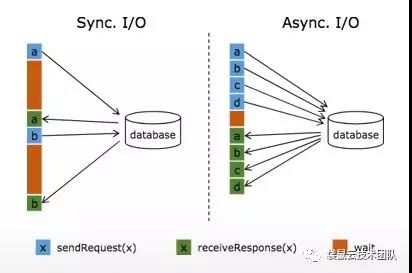
Async I/O 是由阿里巴巴贡献给社区的,于1.2版本引入,主要目的是为了解决与外部系统交互时网络延迟成为了系统瓶颈的问题。具体介绍可以看这篇文章:http://wuchong.me/blog/2017/05/17/flink-internals-async-io/
对应到Flink 的api就是RichAsyncFunction 这个抽象类,继层这个抽象类实现里面的open(初始化),asyncInvoke(数据异步调用),close(停止的一些操作)方法,最主要的是实现asyncInvoke 里面的方法。
流与维表的join会碰到两个问题:
第一个是性能问题。因为流速要是很快,每一条数据都需要到维表做下join,但是维表的数据是存在第三方存储系统,如果实时访问第三方存储系统,不仅join的性能会差,每次都要走网络io;还会给第三方存储系统带来很大的压力,有可能会把第三方存储系统搞挂掉。
所以解决的方法就是维表里的数据要缓存,可以全量缓存,这个主要是维表数据不大的情况,还有一个是LRU缓存,维表数据量比较大的情况。
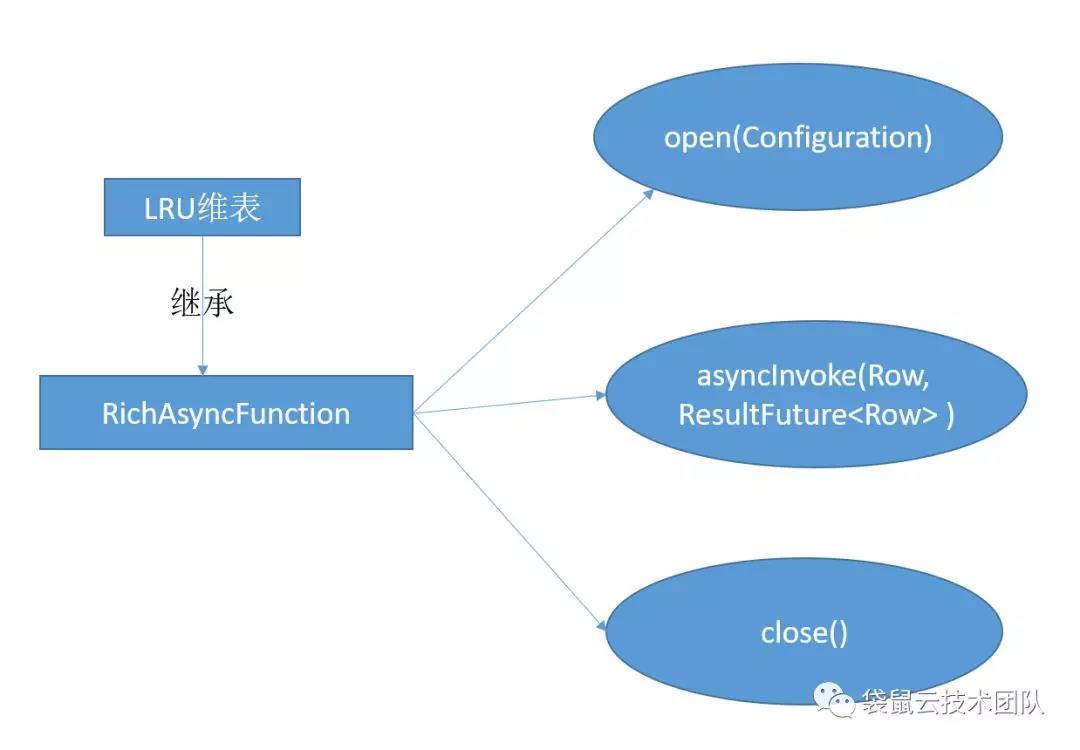
LRU维表的实现
第二个问题是流延迟过来的数据这么跟之前的维表数据做关联。这个就涉及到维表数据需要存储快照数据,所以这样的场景用HBase 做维表是比较适合的,因为HBase 是天生支持数据多版本的。
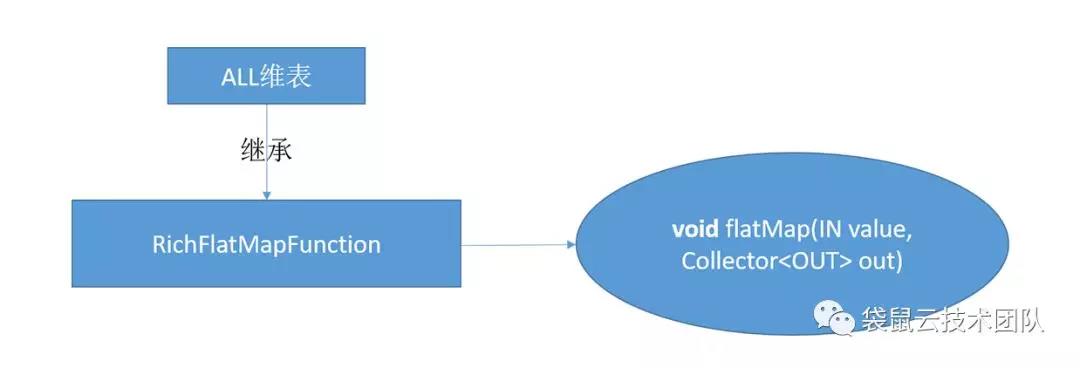
ALL维表的实现
二、解析流与维表join的SQL语法转化成底层的FlinkAPI
因为FlinkSQL已经做了大部分SQL场景,我们不可能在去解析SQL的所有语法,在把他转化成底层FlinkAPI。
所以我们做的就是解析SQL语法,来找到join表里有没有维表,如果有维表,那我们会把这个join的维表的语句单独拆来,用Flink的TableAPI和StreamAPi 生成新DataStream,在把这个DataStream与其他的表在做join这样就能用SQL来实现流与维表的join语法了。
SQL解析的工具就是用Apache calcite,Flink也是用这个框架做SQL解析的。所以所有语法都是可以解析的。
1. DEMO SQL

2. Calcite解析Insert into语句,拆分出子语句

3. Calcite继续解析select语句

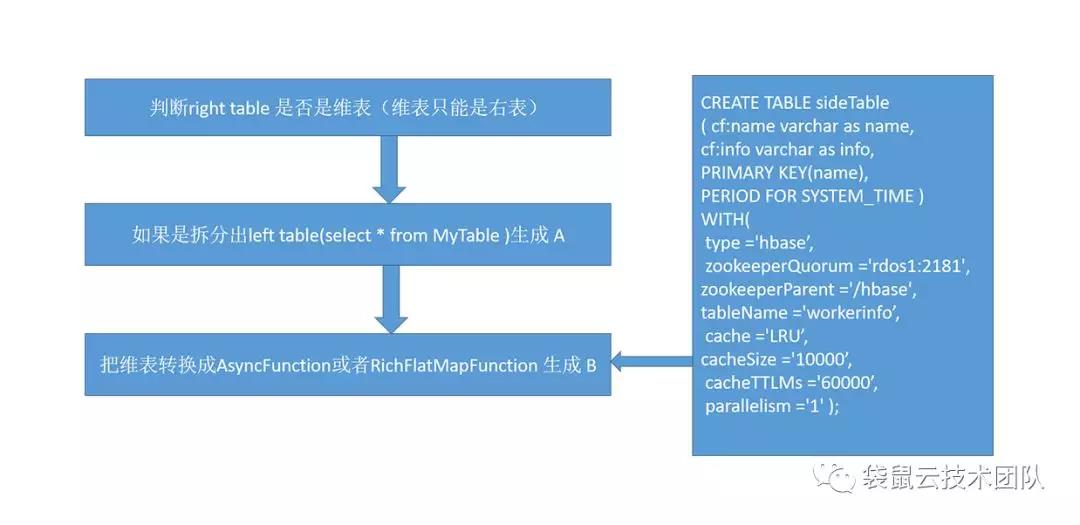
Calcite继续解析select语句
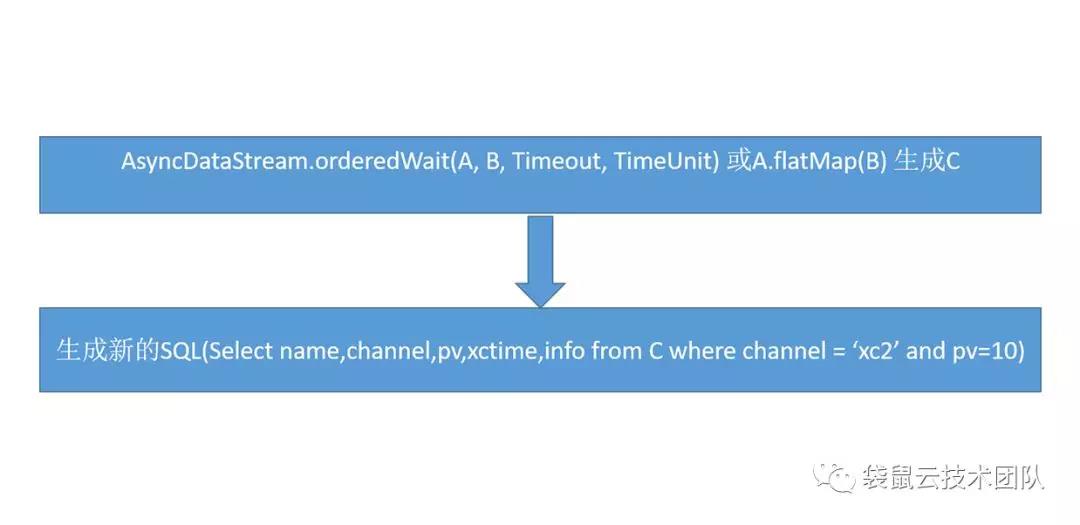
Calcite继续解析select语句
袋鼠云研发手记 | 开源·数栈-扩展FlinkSQL实现流与维表的join的更多相关文章
- 袋鼠云研发手记 | 数栈·开源:Github上400+Star的硬核分布式同步工具FlinkX
作为一家创新驱动的科技公司,袋鼠云每年研发投入达数千万,公司80%员工都是技术人员,袋鼠云产品家族包括企业级一站式数据中台PaaS数栈.交互式数据可视化大屏开发平台Easy[V]等产品也在迅速迭代.在 ...
- 袋鼠云研发手记 | 袋鼠云EasyManager的TypeScript重构纪要
作为一家创新驱动的科技公司,袋鼠云每年研发投入达数千万,公司80%员工都是技术人员,袋鼠云产品家族包括企业级一站式数据中台PaaS数栈.交互式数据可视化大屏开发平台Easy[V]等产品也在迅速迭代.在 ...
- Molecule实现数栈至简前端开发新体验
Keep It Simple, Stupid. 这是开发人耳熟能详的 KISS 原则,也像是一句有调侃意味的善意提醒,提醒每个前端人,简洁易懂的用户体验和删繁就简的搭建逻辑就是前端开发的至简大道. 这 ...
- 数栈运维实例:Oracle数据库运维场景下,智能运维如何落地生根?
从马车到汽车是为了提升运输效率,而随着时代的发展,如今我们又希望用自动驾驶把驾驶员从开车这项体力劳动中解放出来,增加运行效率,同时也可减少交通事故发生率,这也是企业对于智能运维的诉求. 从人工运维到自 ...
- 华夏基金X袋鼠云:基金业数字化转型,为什么说用户才是解题答案?
"精准营销是以客户为中心,运用各种可利用的方式,在恰当的时间,以恰当的价格,通过恰当的渠道,向恰当的顾客提供恰当的产品." 这是学者许瑾在科特勒精准营销理论的基础上,从实践的角度对 ...
- 联万物,+智能,为行业,华为云升级OceanConnect IoT全栈云服务
[中国,上海,2019年9月19日] 9月18日,在HUAWEI CONNECT 2019期间,华为云CTO张宇昕在华为云峰会上升级OceanConnect IoT全栈云服务,发布包括端.边.管.云. ...
- 厉害了,龙果!开源中国颁发了证书:GVP-码云最有价值开源项目
roncoo-pay (龙果支付系统) roncoo-pay是国内首款开源的互联网支付系统,其核心目标是汇聚所有主流支付渠道,打造一款轻量.便捷.易用,且集支付.资金对账.资金清结算于一体的支付系统, ...
- 袋鼠云旗下新公司云掣科技启航,深耕云MSP业务助推企业数字化转型
1983年3月15日,国际消费者联盟组织将3月15日确立为国际消费者权益日. 2019年3月15日,袋鼠云举办三周年年会. 一生二,二生三,三生万物.植树节后,万物生长. 年会现场,袋鼠云宣布成立新公 ...
- 【FAR 方云研发绩效】助力于解决管理难题
方云研发绩效(farcloud.com)自发布以来,助力多家企业完成研发管理数字化转型,并有效解决产研绩效这一普遍存在的管理难题. 研发管理是许多企业面临的管理难题,首先,技术构成的信息壁垒,让内部沟 ...
随机推荐
- ora.ctssd OBSERVER
[grid@ydb1 ~]$ crsctl status res -t -init ora.ctssd 1 ONLINE ONLINE ydb1 ...
- oAuth2.0认证流程图
这两天在看oAuth2.0的东西,简单的使用visio画了个流程图.演示的是用户登录慕课网,使用qq登录的流程:
- Windows Server2012,启动黑屏,只会弹出一个cmd命令窗口的解决办法
Windows Server2012 服务器.在添加删除一个角色功能的时候,有可能会误删除Net Framework 4.5这个电脑基本功能组件. 就会影响到GUI界面的显示,所以服务器打开就只会黑屏 ...
- activemq的高级特性:消息存储持久化
activemq的高级特性之消息存储持久化 有基于文件的,数据库的,内存的.默认的是基于文件的,在安装目录/data/kahadb.在conf/activemq.xml文件中. <persist ...
- HBase的详细安装部署
一.部署 1.Zookeeper正常部署,并且启动 2.Hadoop正常部署,并且启动 3.Hbase的解压 解压HBase到指定目录 tar -xvf /HBase.tar.gz -C /airP ...
- 使用jdk生成自签发证书(过程总结)
前言: 最近在做华为NB-IoT接口开发,需要用到双向认证,就去学了一下. 然后我将过程总结了一下. 相关华为论坛链接:http://developer.huawei.com/ict/forum/th ...
- 2016-2017-2 20155322 实验三 敏捷开发与XP实践
2016-2017-2 20155322 实验三 敏捷开发与XP实践 实验内容 XP基础 XP核心实践 相关工具 实验知识点 敏捷开发(Agile Development)是一种以人为核心.迭代.循序 ...
- # 20155337 2017-2018-1 《信息安全系统设计基础》第二周课堂实践+myod
20155337 2017-2018-1 <信息安全系统设计基础>第二周课堂实践+myod 因为在课上已经提交了四个实验,还欠缺最后一个实验,反省一下自己还是操作不熟练,平时在课下应该多多 ...
- class kind type sort区别
class多用于 级别比如高级货就是 first class,primary class等等,以此类推kind 和sort 基本一样,就像你说的,译为 种类,what kind of疑问,回答时用so ...
- [agc002D]Stamp Rally-[并查集+整体二分]
Description 题目大意:给你一个n个点m个条边构成的简单无向连通图,有Q组询问,每次询问从两个点x,y走出两条路径,使这两条路径覆盖z个点,求得一种方案使得路径上经过的边的最大编号最小.n, ...