gdbt与adboost(或者说boosting)区别
boosting 是一种将弱分类器转化为强分类器的方法统称,而adaboost是其中的一种,或者说AdaBoost是Boosting算法框架中的一种实现

https://www.zhihu.com/question/37683881
gdbt(Gradient Boosting Decision Tree,梯度提升决策树)
gbdt通过多轮迭代,每轮迭代产生一个弱分类器,每个分类器在上一轮分类器的残差基础上进行训练。
弱分类器一般会选择为CART TREE(也就是分类回归树)。由于上述高偏差和简单的要求 每个分类回归树的深度不会很深。最终的总分类器 是将每轮训练得到的弱分类器加权求和得到的(也就是加法模型)。
模型最终可以描述为:
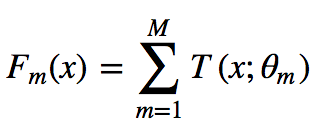
模型一共训练M轮,每轮产生一个弱分类器 T(x;θm)。弱分类器的损失函数
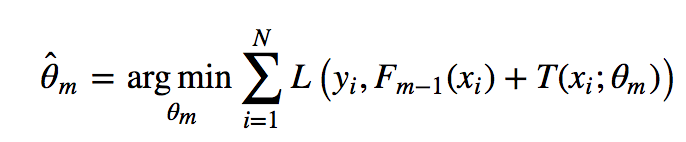
看公式就知道其实每次学习的是T,即当前的那个分类器
Fm−1(x)为当前的模型,gbdt 通过经验风险极小化来确定下一个弱分类器的参数。具体到损失函数本身的选择也就是L的选择,有平方损失函数,0-1损失函数,对数损失函数等等。如果我们选择平方损失函数,那么这个差值其实就是我们平常所说的残差。
- 但是其实我们真正关注的,1.是希望损失函数能够不断的减小,2.是希望损失函数能够尽可能快的减小。所以如何尽可能快的减小呢?
- 让损失函数沿着梯度方向的下降。这个就是gbdt 的 gb的核心了。 利用损失函数的负梯度在当前模型的值作为回归问题提升树算法中的残差的近似值去拟合一个回归树。gbdt 每轮迭代的时候,都去拟合损失函数在当前模型下的负梯度。
- 这样每轮训练的时候都能够让损失函数尽可能快的减小,尽快的收敛达到局部最优解或者全局最优解。
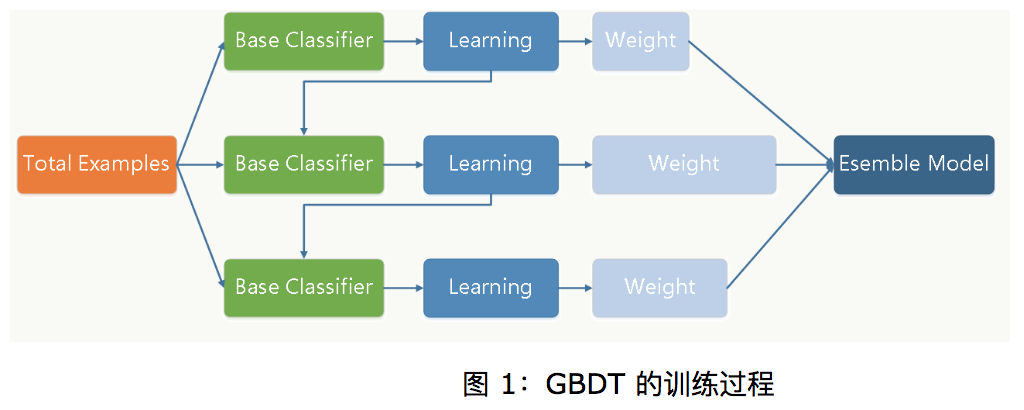
首先明确gbdt也属于boosting,但他和adboost不同,他不是每次训练部门数据,而是整个数据集(如上图所示)。那他为什么又属于boosting呢?个人认为:1.gdbt也是串行的 2.每次迭代需要上次的返回结果,这是这里的返回结果和adboost不同。(之前认为总分类器是将每轮训练得到的弱分类器加权求和得到的,但bagging是vote或者求平均。但是后来发现,bagging里面vote也可以通过软vote获得加权和)
https://www.cnblogs.com/ModifyRong/p/7744987.html
区别:1.adboost是优化错分数据权重,gdbt是通过残差优化每一轮的分类器
2.adboost是指数损失函数,gdbt是平方损失函数
gdbt与adboost(或者说boosting)区别的更多相关文章
- Boosting学习笔记(Adboost、GBDT、Xgboost)
转载请注明出处:http://www.cnblogs.com/willnote/p/6801496.html 前言 本文为学习boosting时整理的笔记,全文主要包括以下几个部分: 对集成学习进行了 ...
- RF 和 GBDT联系和区别
1.RF 原理 用随机的方式建立一个森林,森林里面有很多的决策树,随机森林的每一棵决策树之间是没有关联的.在得到森林之后,当有一个新的输入样本进入的时候,就让森林中的每一棵决策树分别进行一下判断,看看 ...
- bagging and boosting
bagging 侧重于降低方差 方差-variance 方差描述的是预测值的变化范围,离散程度,也就是离期真实值的距离.方差过大表现为过拟合,训练数据的预测f-score很高,但是验证或测试数据的预测 ...
- rf, xgboost和GBDT对比;xgboost和lightGbm
1. RF 随机森林基于Bagging的策略是Bagging的扩展变体,概括RF包括四个部分:1.随机选择样本(放回抽样):2.随机选择特征(相比普通通bagging多了特征采样):3.构建决策树:4 ...
- 随机森林和GBDT
1. 随机森林 Random Forest(随机森林)是Bagging的扩展变体,它在以决策树 为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入了随机特征选择,因此可以概括RF ...
- RF,GBDT,XGBoost,lightGBM的对比
转载地址:https://blog.csdn.net/u014248127/article/details/79015803 RF,GBDT,XGBoost,lightGBM都属于集成学习(Ensem ...
- AI面试刷题版
(1)代码题(leetcode类型),主要考察数据结构和基础算法,以及代码基本功 虽然这部分跟机器学习,深度学习关系不大,但也是面试的重中之重.基本每家公司的面试都问了大量的算法题和代码题,即使是商汤 ...
- AI涉及到数学的一些面试题汇总
[LeetCode] Maximum Product Subarray的4种解法 leetcode每日解题思路 221 Maximal Square LeetCode:Subsets I II (2) ...
- Jackknife,Bootstraping, bagging, boosting, AdaBoosting, Rand forest 和 gradient boosting的区别
引自http://blog.csdn.net/xianlingmao/article/details/7712217 Jackknife,Bootstraping, bagging, boosting ...
随机推荐
- 五、standalone运行模式
在上文中我们知道spark的集群主要有三种运行模式standalone.yarn.mesos,其中常被使用的是standalone和yarn,本文了解一下什么是standalone运行模式,它的运行流 ...
- JDBC数据库连接池
用户每次请求都需要向数据库获得链接,而数据库创建连接通常需要消耗相对较大的资源,创建时间也较长.假设网站一天10万访问量,数据库服务器就需要创建10万次连接,极大的浪费数据库的资源,并且极易造成数据库 ...
- C#学习笔记-中英文切换(XML)
这几天因为软件需要加英文版本,所以查了好久的资料找到了相关的信息,原资料参考:http://blog.csdn.net/softimite_zifeng 上网查的中英文切换大约有两种方式:1.动态加载 ...
- javascript之url转义escape()、encodeURI()和decodeURI(),ifram父子传参参数有中文时出现乱码
ifram父子传参参数有中文时出现乱码,可先在父级页面用encodeURI转义,在到子页面用进行decodeURI()解码 我们可以知道:escape()除了 ASCII 字母.数字和特定的符号外,对 ...
- C# Time Class using MySQL
http://www.csharphelp.com/2007/09/c-time-class/ /* datatypes. Time class is writen in C# and .NET 2. ...
- JS全国城市三级联动
HTML <select id="s_province" name="s_province"></select> <select ...
- MongoDB Limit/限制记录
Limit() 方法 要限制 MongoDB 中的记录,需要使用 limit() 方法. limit() 方法接受一个数字型的参数,这是要显示的文档数. 语法: limit() 方法的基本语法如下 & ...
- MySQL数据库(9)----从命令行获取元数据
1. mysqlshow 命令提供的信息与某些 SHOW 语句很相似,因此可以从命令行提示符获取数据库和表的信息. (i)列出服务器所管理的数据库: root@javis:~$ mysqlshow - ...
- [转]Linux芯片级移植与底层驱动(基于3.7.4内核)
1. SoC Linux底层驱动的组成和现状 为了让Linux在一个全新的ARM SoC上运行,需要提供大量的底层支撑,如定时器节拍.中断控制器.SMP启动.CPU hotplug以及底层的G ...
- Android8.0适配那点事(二)
小伙伴们,咱们今天咱继续对Android8.0的适配进行分解,今天将针对启动页,版本适配和系统限制等进行“啃食” 猛戳这里查看Android8.0适配那点事(一): 1.启动页适配 近日,我无意中发现 ...