100W数据,测试复合索引
复合索引不是那么容易被catch到的。
两个查询条件都是等于的时候,才会被catch到。
mysql> select count(*) from tf_user_index where sex = 2 and score > 80;
+----------+
| count(*) |
+----------+
| 1261904 |
+----------+
1 row in set (10.65 sec)
mysql> select count(*) from tf_user where sex = 2 and score > 80;
+----------+
| count(*) |
+----------+
| 1261904 |
+----------+
1 row in set (4.38 sec)
mysql> explain select count(*) from tf_user_index where sex = 2 and score > 80;
+----+-------------+---------------+------+---------------+------+---------+-------+---------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------------+------+---------------+------+---------+-------+---------+-------------+
| 1 | SIMPLE | tf_user_index | ref | score,sex | sex | 1 | const | 4481227 | Using where |
+----+-------------+---------------+------+---------------+------+---------+-------+---------+-------------+
1 row in set (0.08 sec)
查询条件中,如果有大于号。那么优先抓取等于号对应的索引,也就是sex对应的索引。经过索引的一番折腾,查询时间反而更长了。
即便是把score放到前面,一样的效果。
mysql> explain select count(*) from tf_user_index where score> 80 and sex = 2;
+----+-------------+---------------+------+---------------+------+---------+-------+---------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------------+------+---------------+------+---------+-------+---------+-------------+
| 1 | SIMPLE | tf_user_index | ref | score,sex | sex | 1 | const | 4481227 | Using where |
+----+-------------+---------------+------+---------------+------+---------+-------+---------+-------------+
两个条件都为等于的时候,索引的效果就有点明显了。
mysql> select count(*) from tf_user_index where sex = 2 and score = 80;
+----------+
| count(*) |
+----------+
| 63230 |
+----------+
1 row in set (1.09 sec)
mysql> select count(*) from tf_user where sex = 2 and score = 80;
+----------+
| count(*) |
+----------+
| 63230 |
+----------+
1 row in set (2.61 sec)
mysql> explain select count(*) from tf_user_index where sex = 2 and score = 80;
+----+-------------+---------------+-------------+---------------+-----------+---------+------+--------+------------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------------+-------------+---------------+-----------+---------+------+--------+------------------------------------------------------+
| 1 | SIMPLE | tf_user_index | index_merge | score,sex | score,sex | 4,1 | NULL | 124004 | Using intersect(score,sex); Using where; Using index |
+----+-------------+---------------+-------------+---------------+-----------+---------+------+--------+------------------------------------------------------+
1 row in set (0.00 sec)
这个时候,并没有添加复合索引。
加了复合索引,如果查询条件是大于号,一样catch不到。
mysql> explain select count(*) from tf_user_index where sex = 2 and score > 80;
+----+-------------+---------------+------+---------------------+------+---------+-------+---------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------------+------+---------------------+------+---------+-------+---------+-------------+
| 1 | SIMPLE | tf_user_index | ref | score,sex,score_sex | sex | 1 | const | 4481227 | Using where |
+----+-------------+---------------+------+---------------------+------+---------+-------+---------+-------------+
1 row in set (0.01 sec)
mysql> select count(*) from tf_user_index where score > 80 and sex =2;
+----------+
| count(*) |
+----------+
| 1261904 |
+----------+
1 row in set (15.32 sec)
竟然执行了15秒之久。
这条sql语句可以优化一下,将sex也改为大于号。
mysql> select count(*) from tf_user_index where score > 80 and sex >1;
+----------+
| count(*) |
+----------+
| 1261904 |
+----------+
1 row in set (0.66 sec)
mysql> explain select count(*) from tf_user_index where score > 80 and sex >1;
+----+-------------+---------------+-------+---------------------+-----------+---------+------+---------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------------+-------+---------------------+-----------+---------+------+---------+--------------------------+
| 1 | SIMPLE | tf_user_index | range | score,sex,score_sex | score_sex | 4 | NULL | 4481227 | Using where; Using index |
+----+-------------+---------------+-------+---------------------+-----------+---------+------+---------+--------------------------+
1 row in set (0.00 sec)
这样就捕捉到了索引。
mysql> select count(*) from tf_user_index where score = 80 and sex = 1;
+----------+
| count(*) |
+----------+
| 62866 |
+----------+
1 row in set (0.01 sec)
mysql> explain select count(*) from tf_user_index where score = 80 and sex = 1;
+----+-------------+---------------+------+---------------------+-----------+---------+-------------+--------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------------+------+---------------------+-----------+---------+-------------+--------+-------------+
| 1 | SIMPLE | tf_user_index | ref | score,sex,score_sex | score_sex | 5 | const,const | 124794 | Using index |
+----+-------------+---------------+------+---------------------+-----------+---------+-------------+--------+-------------+
1 row in set (0.00 sec)
mysql> select count(*) from tf_user_index where sex = 1 and score=80;
+----------+
| count(*) |
+----------+
| 62866 |
+----------+
1 row in set (0.01 sec)
mysql> explain select count(*) from tf_user_index where sex = 1 and score=80;
+----+-------------+---------------+------+---------------------+-----------+---------+-------------+--------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------------+------+---------------------+-----------+---------+-------------+--------+-------------+
| 1 | SIMPLE | tf_user_index | ref | score,sex,score_sex | score_sex | 5 | const,const | 124794 | Using index |
+----+-------------+---------------+------+---------------------+-----------+---------+-------------+--------+-------------+
1 row in set (0.00 sec)
顺序并不重要。
索引,复合索引,确实可以提供查询的速度。关键是,要能够捕捉到。要能够找寻它们捕捉的规律。理解它们执行的过程。
合理的分析查询的规律,合理的给表添加索引。分析常用的查询,分析常用的查询字段。通过explain字段来进行sql语句的分析,优化sql语句。
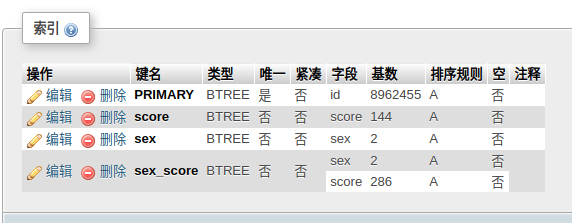
实践发现sex_score,score_sex查询的效果是一样的,关键是能否捕捉到。
mysql> explain select count(*) from tf_user_index where sex = 2 and score>80;
+----+-------------+---------------+-------+---------------------+-----------+---------+------+---------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------------+-------+---------------------+-----------+---------+------+---------+--------------------------+
| 1 | SIMPLE | tf_user_index | range | score,sex,sex_score | sex_score | 5 | NULL | 2446346 | Using where; Using index |
+----+-------------+---------------+-------+---------------------+-----------+---------+------+---------+--------------------------+
1 row in set (0.00 sec)
mysql> select count(*) from tf_user_index where sex = 2 and score>80;
+----------+
| count(*) |
+----------+
| 1261904 |
+----------+
1 row in set (0.31 sec)
我屮艸芔茻,sex_score竟然捕捉到了索引。看来顺序还是有所区别的。这个建索引还是多多的实验吧。孰能生巧。
100W数据,测试复合索引的更多相关文章
- 100W数据,测试索引
两张表,结构相同,数据内容相同.唯一不同的就是是否包含索引.tf_user_index表中包含索引. 这100w数据,我造了近一天时间. mysql> select count(*) from ...
- SQL Server 执行计划利用统计信息对数据行的预估原理二(为什么复合索引列顺序会影响到执行计划对数据行的预估)
本文出处:http://www.cnblogs.com/wy123/p/6008477.html 关于统计信息对数据行数做预估,之前写过对非相关列(单独或者单独的索引列)进行预估时候的算法,参考这里. ...
- 关于SQL查询效率,100w数据,查询只要1秒
1.关于SQL查询效率,100w数据,查询只要1秒,与您分享:机器情况p4: 2.4内存: 1 Gos: windows 2003数据库: ms sql server 2000目的: 查询性能测试,比 ...
- SQL Server创建复合索引时,复合索引列顺序对查询的性能影响
说说复合索引 写索引的博客太多了,一直不想动手写,有一下两个原因:一是觉得有炒剩饭的嫌疑,有兄弟曾说:索引吗,只要在查询条件上建索引就行了,真的可以这么暴力吗?二来觉得,索引是个非常大的话题,很难概括 ...
- SQL SERVER大话存储结构(4)_复合索引与包含索引
索引这块从存储结构来分,有2大类,聚集索引和非聚集索引,而非聚集索引在堆表或者在聚集索引表都会对其 键值有所影响,这块可以详细查看本系列第二篇文章:SQL SERVER大话存储结构 ...
- Mysql limit 优化,百万至千万级快速分页,--复合索引的引用并应用于轻量级框架
MySql 性能到底能有多高?用了php半年多,真正如此深入的去思考这个问题还是从前天开始.有过痛苦有过绝望,到现在充满信心!MySql 这个数据库绝对是适合dba级的高手去玩的,一般做一点1万篇新闻 ...
- MySQL复合索引探究
复合索引(又称为联合索引),是在多个列上创建的索引.创建复合索引最重要的是列顺序的选择,这关系到索引能否使用上,或者影响多少个谓词条件能使用上索引.复合索引的使用遵循最左匹配原则,只有索引左边的列匹配 ...
- Sql Server之旅——第九站 看公司这些DBA们设计的这些复合索引
这一篇再说下索引的最后一个主题,索引覆盖,当然学习比较好的捷径是看看那些大师们设计的索引,看从中能提取些什么营养的东西,下面我们看 看数据库中一个核心的Orders表. 一:查看表的架构 <1& ...
- Sql Server之旅——第八站 复合索引和include索引到底有多大区别?
周末终于搬进出租房了,装了宽带....才发现没网的日子...那是一个怎样的与世隔绝呀...再也受不了那样的日子了....好了,既然网 安上去了,还得继续我的这个系列. 索引和锁,这两个主题对我们开发工 ...
随机推荐
- js中的匿名函数和匿名自执行函数
1.匿名函数的常见场景 js中的匿名函数是一种很常见的函数类型,比较常见的场景: <input type="button" value="点击" id ...
- pandas将字段中的字符类型转化为时间类型,并设置为索引
假设目前已经引入了 pandas,同时也拥有 pandas 的 DataFrame 类型数据. import pandas as pd 数据集如下 df.head(3) date open close ...
- 阿里云ecs禁止ping,禁止telnet
现在的中小型企业服务器大多是云比较多,因此,可能会面临着服务器ping不通,或者是端口telnet不通的情况,但是服务器上的服务仍然是正常的情况,这个时候我们就要考虑是不是云上配置了访问规则了.废话不 ...
- 沈阳网络赛K-Supreme Number【规律】
26.89% 1000ms 131072K A prime number (or a prime) is a natural number greater than 11 that cannot be ...
- 全面解析Oracle等待事件的分类、发现及优化
一.等待事件由来 大家可能有些奇怪,为什么说等待事件,先谈到了指标体系.其实,正是因为指标体系的发展,才导致等待事件的引入.总结一下,Oracle的指标体系,大致经历了下面三个阶段: · 以命中率为主 ...
- Teigha.net读写dwg文件显示
官网:http://www.opendesign.com/ http://www.cnblogs.com/zhanglibo0626/archive/2011/11/04/2236238.html 下 ...
- EasyUI Droppable 可放置
通过 $.fn.droppable.defaults 重写默认的 defaults. 用法 通过标记创建可放置(droppable)区域. <div class="easyui-dro ...
- 详谈LABJS按需动态加载js文件
为了提高页面的打开和加载速度,我们经常把JS文件放在页面的尾部,但是有些JS必须放在页面前面,这样就会增加页面的加载时间:于是出现了按需动态加载的概念,这个概念就是当页面需要用到这个JS文件或者CSS ...
- PAT 1053 Path of Equal Weight[比较]
1053 Path of Equal Weight(30 分) Given a non-empty tree with root R, and with weight Wi assigned t ...
- java基础知识面试题(41-95)
41.日期和时间:- 如何取得年月日.小时分钟秒?- 如何取得从1970年1月1日0时0分0秒到现在的毫秒数?- 如何取得某月的最后一天?- 如何格式化日期?答:问题1:创建java.util.Cal ...