100W数据,测试复合索引
复合索引不是那么容易被catch到的。
两个查询条件都是等于的时候,才会被catch到。
mysql> select count(*) from tf_user_index where sex = 2 and score > 80;
+----------+
| count(*) |
+----------+
| 1261904 |
+----------+
1 row in set (10.65 sec)
mysql> select count(*) from tf_user where sex = 2 and score > 80;
+----------+
| count(*) |
+----------+
| 1261904 |
+----------+
1 row in set (4.38 sec)
mysql> explain select count(*) from tf_user_index where sex = 2 and score > 80;
+----+-------------+---------------+------+---------------+------+---------+-------+---------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------------+------+---------------+------+---------+-------+---------+-------------+
| 1 | SIMPLE | tf_user_index | ref | score,sex | sex | 1 | const | 4481227 | Using where |
+----+-------------+---------------+------+---------------+------+---------+-------+---------+-------------+
1 row in set (0.08 sec)
查询条件中,如果有大于号。那么优先抓取等于号对应的索引,也就是sex对应的索引。经过索引的一番折腾,查询时间反而更长了。
即便是把score放到前面,一样的效果。
mysql> explain select count(*) from tf_user_index where score> 80 and sex = 2;
+----+-------------+---------------+------+---------------+------+---------+-------+---------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------------+------+---------------+------+---------+-------+---------+-------------+
| 1 | SIMPLE | tf_user_index | ref | score,sex | sex | 1 | const | 4481227 | Using where |
+----+-------------+---------------+------+---------------+------+---------+-------+---------+-------------+
两个条件都为等于的时候,索引的效果就有点明显了。
mysql> select count(*) from tf_user_index where sex = 2 and score = 80;
+----------+
| count(*) |
+----------+
| 63230 |
+----------+
1 row in set (1.09 sec)
mysql> select count(*) from tf_user where sex = 2 and score = 80;
+----------+
| count(*) |
+----------+
| 63230 |
+----------+
1 row in set (2.61 sec)
mysql> explain select count(*) from tf_user_index where sex = 2 and score = 80;
+----+-------------+---------------+-------------+---------------+-----------+---------+------+--------+------------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------------+-------------+---------------+-----------+---------+------+--------+------------------------------------------------------+
| 1 | SIMPLE | tf_user_index | index_merge | score,sex | score,sex | 4,1 | NULL | 124004 | Using intersect(score,sex); Using where; Using index |
+----+-------------+---------------+-------------+---------------+-----------+---------+------+--------+------------------------------------------------------+
1 row in set (0.00 sec)
这个时候,并没有添加复合索引。
加了复合索引,如果查询条件是大于号,一样catch不到。
mysql> explain select count(*) from tf_user_index where sex = 2 and score > 80;
+----+-------------+---------------+------+---------------------+------+---------+-------+---------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------------+------+---------------------+------+---------+-------+---------+-------------+
| 1 | SIMPLE | tf_user_index | ref | score,sex,score_sex | sex | 1 | const | 4481227 | Using where |
+----+-------------+---------------+------+---------------------+------+---------+-------+---------+-------------+
1 row in set (0.01 sec)
mysql> select count(*) from tf_user_index where score > 80 and sex =2;
+----------+
| count(*) |
+----------+
| 1261904 |
+----------+
1 row in set (15.32 sec)
竟然执行了15秒之久。
这条sql语句可以优化一下,将sex也改为大于号。
mysql> select count(*) from tf_user_index where score > 80 and sex >1;
+----------+
| count(*) |
+----------+
| 1261904 |
+----------+
1 row in set (0.66 sec)
mysql> explain select count(*) from tf_user_index where score > 80 and sex >1;
+----+-------------+---------------+-------+---------------------+-----------+---------+------+---------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------------+-------+---------------------+-----------+---------+------+---------+--------------------------+
| 1 | SIMPLE | tf_user_index | range | score,sex,score_sex | score_sex | 4 | NULL | 4481227 | Using where; Using index |
+----+-------------+---------------+-------+---------------------+-----------+---------+------+---------+--------------------------+
1 row in set (0.00 sec)
这样就捕捉到了索引。
mysql> select count(*) from tf_user_index where score = 80 and sex = 1;
+----------+
| count(*) |
+----------+
| 62866 |
+----------+
1 row in set (0.01 sec)
mysql> explain select count(*) from tf_user_index where score = 80 and sex = 1;
+----+-------------+---------------+------+---------------------+-----------+---------+-------------+--------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------------+------+---------------------+-----------+---------+-------------+--------+-------------+
| 1 | SIMPLE | tf_user_index | ref | score,sex,score_sex | score_sex | 5 | const,const | 124794 | Using index |
+----+-------------+---------------+------+---------------------+-----------+---------+-------------+--------+-------------+
1 row in set (0.00 sec)
mysql> select count(*) from tf_user_index where sex = 1 and score=80;
+----------+
| count(*) |
+----------+
| 62866 |
+----------+
1 row in set (0.01 sec)
mysql> explain select count(*) from tf_user_index where sex = 1 and score=80;
+----+-------------+---------------+------+---------------------+-----------+---------+-------------+--------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------------+------+---------------------+-----------+---------+-------------+--------+-------------+
| 1 | SIMPLE | tf_user_index | ref | score,sex,score_sex | score_sex | 5 | const,const | 124794 | Using index |
+----+-------------+---------------+------+---------------------+-----------+---------+-------------+--------+-------------+
1 row in set (0.00 sec)
顺序并不重要。
索引,复合索引,确实可以提供查询的速度。关键是,要能够捕捉到。要能够找寻它们捕捉的规律。理解它们执行的过程。
合理的分析查询的规律,合理的给表添加索引。分析常用的查询,分析常用的查询字段。通过explain字段来进行sql语句的分析,优化sql语句。
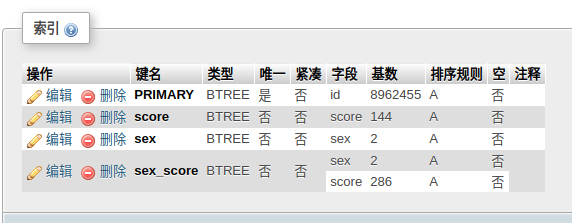
实践发现sex_score,score_sex查询的效果是一样的,关键是能否捕捉到。
mysql> explain select count(*) from tf_user_index where sex = 2 and score>80;
+----+-------------+---------------+-------+---------------------+-----------+---------+------+---------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------------+-------+---------------------+-----------+---------+------+---------+--------------------------+
| 1 | SIMPLE | tf_user_index | range | score,sex,sex_score | sex_score | 5 | NULL | 2446346 | Using where; Using index |
+----+-------------+---------------+-------+---------------------+-----------+---------+------+---------+--------------------------+
1 row in set (0.00 sec)
mysql> select count(*) from tf_user_index where sex = 2 and score>80;
+----------+
| count(*) |
+----------+
| 1261904 |
+----------+
1 row in set (0.31 sec)
我屮艸芔茻,sex_score竟然捕捉到了索引。看来顺序还是有所区别的。这个建索引还是多多的实验吧。孰能生巧。
100W数据,测试复合索引的更多相关文章
- 100W数据,测试索引
两张表,结构相同,数据内容相同.唯一不同的就是是否包含索引.tf_user_index表中包含索引. 这100w数据,我造了近一天时间. mysql> select count(*) from ...
- SQL Server 执行计划利用统计信息对数据行的预估原理二(为什么复合索引列顺序会影响到执行计划对数据行的预估)
本文出处:http://www.cnblogs.com/wy123/p/6008477.html 关于统计信息对数据行数做预估,之前写过对非相关列(单独或者单独的索引列)进行预估时候的算法,参考这里. ...
- 关于SQL查询效率,100w数据,查询只要1秒
1.关于SQL查询效率,100w数据,查询只要1秒,与您分享:机器情况p4: 2.4内存: 1 Gos: windows 2003数据库: ms sql server 2000目的: 查询性能测试,比 ...
- SQL Server创建复合索引时,复合索引列顺序对查询的性能影响
说说复合索引 写索引的博客太多了,一直不想动手写,有一下两个原因:一是觉得有炒剩饭的嫌疑,有兄弟曾说:索引吗,只要在查询条件上建索引就行了,真的可以这么暴力吗?二来觉得,索引是个非常大的话题,很难概括 ...
- SQL SERVER大话存储结构(4)_复合索引与包含索引
索引这块从存储结构来分,有2大类,聚集索引和非聚集索引,而非聚集索引在堆表或者在聚集索引表都会对其 键值有所影响,这块可以详细查看本系列第二篇文章:SQL SERVER大话存储结构 ...
- Mysql limit 优化,百万至千万级快速分页,--复合索引的引用并应用于轻量级框架
MySql 性能到底能有多高?用了php半年多,真正如此深入的去思考这个问题还是从前天开始.有过痛苦有过绝望,到现在充满信心!MySql 这个数据库绝对是适合dba级的高手去玩的,一般做一点1万篇新闻 ...
- MySQL复合索引探究
复合索引(又称为联合索引),是在多个列上创建的索引.创建复合索引最重要的是列顺序的选择,这关系到索引能否使用上,或者影响多少个谓词条件能使用上索引.复合索引的使用遵循最左匹配原则,只有索引左边的列匹配 ...
- Sql Server之旅——第九站 看公司这些DBA们设计的这些复合索引
这一篇再说下索引的最后一个主题,索引覆盖,当然学习比较好的捷径是看看那些大师们设计的索引,看从中能提取些什么营养的东西,下面我们看 看数据库中一个核心的Orders表. 一:查看表的架构 <1& ...
- Sql Server之旅——第八站 复合索引和include索引到底有多大区别?
周末终于搬进出租房了,装了宽带....才发现没网的日子...那是一个怎样的与世隔绝呀...再也受不了那样的日子了....好了,既然网 安上去了,还得继续我的这个系列. 索引和锁,这两个主题对我们开发工 ...
随机推荐
- mysql 远程连接超时解决办法
设置mysql远程连接root权限 在远程连接mysql的时候应该都碰到过,root用户无法远程连接mysql,只可以本地连,对外拒绝连接. 需要建立一个允许远程登录的数据库帐户,这样才可以进行在远程 ...
- poj1039 Pipe【计算几何】
含[求直线交点].[判断直线与线段相交]模板 Pipe Time Limit: 1000MS Memory Limit: 10000K Total Submissions:11940 Ac ...
- SDL结合QWidget的简单使用说明(2)
上篇主要讲了针对yv12流数据的渲染,但有时候我们显示视频还要求加一些信息,比如头像,昵称等等.一般的想法是在渲染窗口之上做一个小控件来负责: 但是很遗憾,你会发现你的控件被SDL的渲染完全遮住了,渲 ...
- 从LayoutInflater分析XML布局解析成View的树形结构的过程
上一篇博客分析了XML布局怎么载入到Activity上.不了解的能够參考 从setContentView方法分析Android载入布局流程 上一篇博客仅仅是分析了怎么讲XML布局加入到 Activit ...
- java-mybaits-00701-与spring整合
1.1 整合思路 需要spring通过单例方式管理SqlSessionFactory. spring和mybatis整合生成代理对象,使用SqlSessionFactory创建SqlSes ...
- python高级之Flask框架
目录: Flask基本使用 Flask配置文件 Flask路由系统 Flask模版 Flask请求与响应 Flask之Session Flask之蓝图 Flask之message 中间件 Flask插 ...
- 4.3 Routing -- Generated Objects
就像在routing guide中介绍的那样,不管什么时候你在路由器中定义一个新路径,Ember.js就会尝试寻找一个对应的route,controller,template,它们的命名都是根据命名约 ...
- cocos代码研究(8)持续动作子类学习笔记
理论部分 时间间隔动作(ActionInterval)是一个在一段时间内执行的动作. 它有一个开始时间和完成时间.完成时间等于起始时间加上持续时间. ActionInterval的子类与位置有关的动作 ...
- in `connect': SSL_connect returned=1 errno=0 state=SSLv3 read server certificate B: certificate verify failed (OpenSSL::SSL::SSLError)
最近在用ruby的一些库的时候,总是出现这个错误. 在使用net/imap库的时候,或者net/http库(主要是用到了https,https是用了ssl) 的时候,具体如下: 错误提示:E:/Rub ...
- DHCP服务器配置实践
实验背景:在LINUX系统上为一园区网络配置DHCP服务器,给网络内各主机自动分配IP地址,地址池范围为:192.168.X.100~192.168.X.200,配置作用域选项,其中网关为:192.1 ...