KMP算法匹配原理以及C++实现
原创作品,转载请注明出处:点我



#ifndef __KMP__H__
#define __KMP__H__
#include <string>
#include <vector>
using namespace std; class KMP{
public:
//void static getNext(const string &str,vector<int> &vec);
int kmp();
KMP(){}
KMP( const string &target,const string &pattern):mTarget(target),mPattern(pattern){}
void setTarget(const string &target);
void setPattern(const string &pattern);
private:
vector< int> mVec;
string mTarget;
string mPattern;
void getNext();
};
#endif
下面是源代码实现
#include "KMP.h"
#include <iostream>
#include <vector>
using namespace std; //获取字符串str的所有子串中相同子集的长度
//比如字符串ababacb,分别获取字符串a,ab,aba,abab,ababa,ababac,ababacb中D
//最前面和最后面相同的子串的最大长度,比如
//a:因为aa为a单个字符,所以最前面和最后面相同的子串的最大长度为a0
//aba,最前面一个a和最后面一个元a素a相同,所以值为a1,abab最前面2个ab和最后面两个ab相同,值为a2
//ababa最前面3个为aaba,最后面3个为aaba,所以值为a3
void KMP::getNext()
{
mVec.clear(); //清空?ec
//vec.push_back(0);//为a了使用方便,vec的第一个数据不用
mVec.push_back(); //第一个字符的下一个位置一定是0,比如"ababacb",首字符a的值为0
string::const_iterator start = mPattern.begin();
string::const_iterator pos = start + ;
while(pos != mPattern.end())
{
string subStr(start,pos+); //获取子字符串
int strLen = subStr.size() - ;//获取子串中D前后相同的子子串的最大长度
do
{
string prefix(subStr,,strLen); //获取subStr中D的前面strLen子集
string postfix(subStr,subStr.size()-strLen,strLen); //获取subStr中D的前面?trLen子集
if(prefix == postfix)
{
mVec.push_back(strLen);
break;
}
--strLen;
/如果前后相同的子集的长度小于一
/说明没有相同的,则把0压栈
if(strLen < )
mVec.push_back();
} while(strLen > ); ++pos;
}
} void KMP::setPattern(const string &pattern)
{
mPattern = pattern;
} void KMP::setTarget(const string &target)
{
mTarget = target;
} int KMP::kmp()
{
getNext(); //首先获取next数据
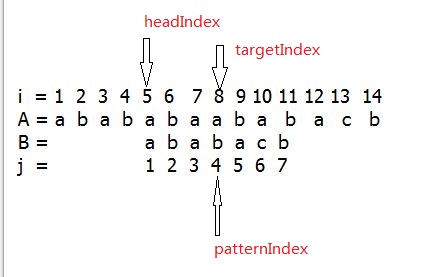
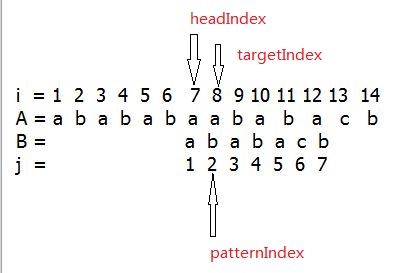
int targetIndex = ;
int patternIndex = ;
int headIndex = ;//指向跟pattern匹配的Target的第一个元素的索引
while(patternIndex != mPattern.size() && targetIndex != mTarget.size())
{
for(int i = ; i < mPattern.size()-;++i)
{
if(mPattern[patternIndex] == mTarget[targetIndex])
{
++patternIndex;
++targetIndex;
if(mPattern.size()== patternIndex)//如果已经匹配成功,则退出循环
break;
}
else
{
if( == patternIndex)//如果第一个字符就不匹配,则把mTarget左移一位
++headIndex;
else
{
headIndex += patternIndex - mVec[patternIndex-];//由于vector索引从零开始,所以要减去一
patternIndex = mVec[patternIndex-];//更新patternIndex索引
}
targetIndex = headIndex + patternIndex;//跟新targetIndex索引
break;
} }
} return headIndex;
}
KMP算法匹配原理以及C++实现的更多相关文章
- 字符串匹配--kmp算法原理整理
kmp算法原理:求出P0···Pi的最大相同前后缀长度k: 字符串匹配是计算机的基本任务之一.举例,字符串"BBC ABCDAB ABCDABCDABDE",里面是否包含另一个字符 ...
- [Algorithm] 字符串匹配算法——KMP算法
1 字符串匹配 字符串匹配是计算机的基本任务之一. 字符串匹配是什么?举例来说,有一个字符串"BBC ABCDAB ABCDABCDABDE",我想知道,里面是否包含另一个字符串& ...
- 深入理解KMP算法
前言:本人最近在看<大话数据结构>字符串模式匹配算法的内容,但是看得很迷糊,这本书中这块的内容感觉基本是严蔚敏<数据结构>的一个翻版,此书中给出的代码实现确实非常精炼,但是个人 ...
- KMP算法详解 --- 彻头彻尾理解KMP算法
前言 之前对kmp算法虽然了解它的原理,即求出P0···Pi的最大相同前后缀长度k. 但是问题在于如何求出这个最大前后缀长度呢? 我觉得网上很多帖子都说的不是很清楚,总感觉没有把那层纸戳破, 后来翻看 ...
- 模式匹配KMP算法
关于KMP算法的原理网上有很详细的解释,我试着总结理解一下: KMP算法是什么 以这张图片为例子 匹配到j=5时失效了,BF算法里我们会使i=1,j=0,再看s的第i位开始能不能匹配,而KMP算法接下 ...
- 数据结构(复习)---------字符串-----KMP算法(转载)
字符串匹配是计算机的基本任务之一. 举例来说,有一个字符串"BBC ABCDAB ABCDABCDABDE",我想知道,里面是否包含另一个字符串"ABCDABD" ...
- KMP算法详解 --从july那学的
KMP代码: int KmpSearch(char* s, char* p) { ; ; int sLen = strlen(s); int pLen = strlen(p); while (i &l ...
- KMP算法的一次理解
1. 引言 在一个大的字符串中对一个小的子串进行定位称为字符串的模式匹配,这应该算是字符串中最重要的一个操作之一了.KMP本身不复杂,但网上绝大部分的文章把它讲混乱了.下面,咱们从暴力匹配算法讲起,随 ...
- 字符串匹配KMP算法详解
1. 引言 以前看过很多次KMP算法,一直觉得很有用,但都没有搞明白,一方面是网上很少有比较详细的通俗易懂的讲解,另一方面也怪自己没有沉下心来研究.最近在leetcode上又遇见字符串匹配的题目,以此 ...
随机推荐
- iOS打包framework - Swift完整项目打包Framework,嵌入OC项目使用
场景说明: -之前做的App,使用Swift框架语言,混合编程,内含少部分OC代码. -需要App整体功能打包成静态库,完整移植到另一个App使用,该App使用OC. -所以涉及到一个语言互转的处理, ...
- windows named pipe 客户端 服务器
可以实现多客户端对一服务端,服务端为客户端提供服务. 其实一服务端对应每一个client pipe都新建立了一个pipe.windows允许建立多个同名pipe 效果: 服务端代码: #define ...
- linux系统新建用户ssh远程登陆显示-bash-4.1$解决方法,ssh-bash-4.1
linux系统新建的用户用ssh远程登陆显示-bash-4.1$,不显示用户名路径 网络上好多解决办法,大多是新建.bash_profile文件然后输入XXXXX....然而并没有什么用没有用.... ...
- api 和 C# 里的接口的区别?
从狭义上讲,接口指的是借由 interface 定义的结构,接口中只对方法做定义,不做实现.具体实现由最终实现接口的类提供. interface 作为一种类型,可以用于定义方法,我们只关心类实现了接口 ...
- Jmeter----HTTP Request Defaults
一.HTTP Request Defaults的作用: 该组件可以为我们的http请求设置默认的值.假如,我们创建一个测试计划有很多个请求且都是发送到相同的server,这时我们只需添加一个Http ...
- OGG_GoldenGate日常维护(案例)
2014-03-12 Created By BaoXinjian
- Concurrency Managed Workqueue(一)workqueue基本概念
一.前言 workqueue是一个驱动工程师常用的工具,在旧的内核中(指2.6.36之前的内核版本)workqueue代码比较简单(大概800行),在2.6.36内核版本中引入了CMWQ(Concur ...
- ECharts 与struts的后台交互之柱状图
ECharts主页: http://echarts.baidu.com/index.html ECharts-2.1.8下载地址: http://echarts.baidu.com/build/e ...
- FreeSWITCH检测DTMF数据的方法
一.RFC2833 1. 介绍: RFC2833为带内检测方式,通过RTP传输,由特殊的rtpPayloadType即TeleponeEvent来标示RFC2833数据包.同一个DTMF按键通常会对应 ...
- mysql-5.7 收缩系统表空间详解
innodb 系统表空间是一个逻辑上的概念,它的物理表现就是innodb系统表空间文件:在讲扩展系统表空间时我们说到 可以用增加文件,增加autoextend标记 这两种方式来解决:但是问题到了收缩表 ...