mysql分组排序加序号(不用存储过程,就简简单单sql语句哦)
做前端好长时间了,好久没动sql了。在追一个喜欢的女孩,做测试的,有这么个需求求助与本屌丝,机会难得,开始折腾起来,配置mysql,建库,建表....
一 建表
CREATE TABLE `my_test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`parent_code` varchar(255) DEFAULT NULL,
`code` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8;
二 模拟数据
INSERT INTO `my_test` ( `parent_code`, `code`) VALUES ('', '');
INSERT INTO `my_test` ( `parent_code`, `code`) VALUES ('', '');
INSERT INTO `my_test` ( `parent_code`, `code`) VALUES ('', '');
INSERT INTO `my_test` ( `parent_code`, `code`) VALUES ('', '');
INSERT INTO `my_test` ( `parent_code`, `code`) VALUES ('', '');
INSERT INTO `my_test` ( `parent_code`, `code`) VALUES ('', '');
INSERT INTO `my_test` ( `parent_code`, `code`) VALUES ('', '');
查询 结果如下:

三 不分组加序号
select (@i := @i + 1) rownum,my_test.* from my_test , (SELECT @i := 0) AS a group by parent_code ,code ,id order by parent_code
结果如下:
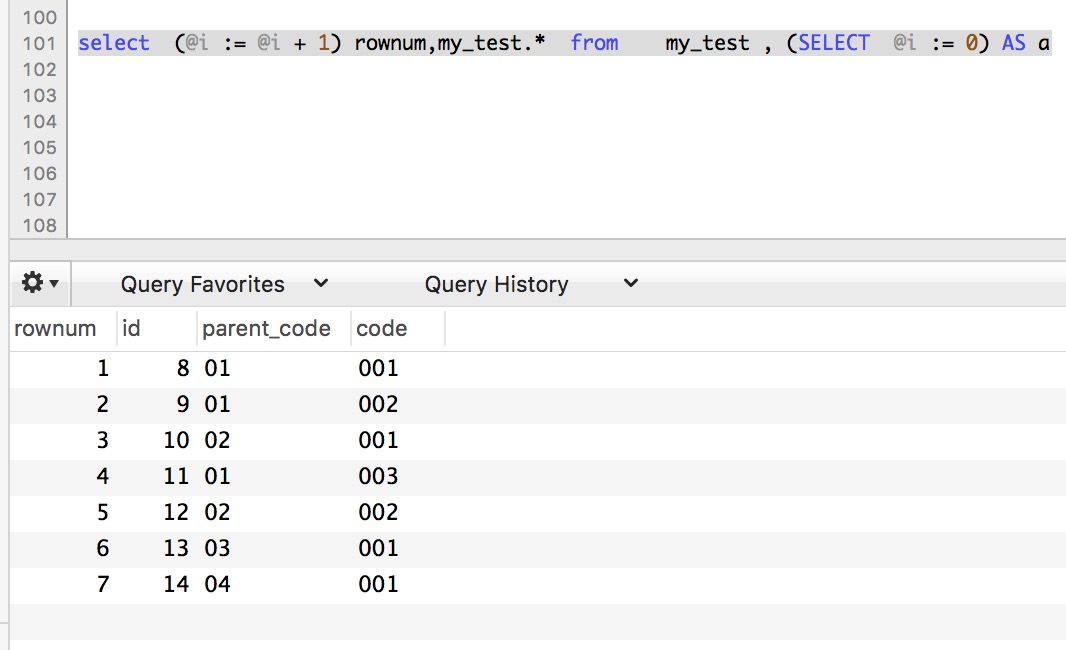
解释一下 这个地方用了@i变量 刚开始的 让 @i=0 然后 每查询一条 让 @i+=1
四 分组 排序 加 序号了
刚开始的没 思路,就度娘了 ,有用 存储过程 创建临时表 插入临时表实现的,还有用存储过程游标实现,对于好久没动sql,而且之前也没写过mysql 查询的 淫来说 好复杂,
好囧 ,赶脚要再我女神面前丢人了,but 多谢上天眷顾,查看我女神聊天记录的时候,灵感来了,为什么不继续发掘下变量的作用呢 。
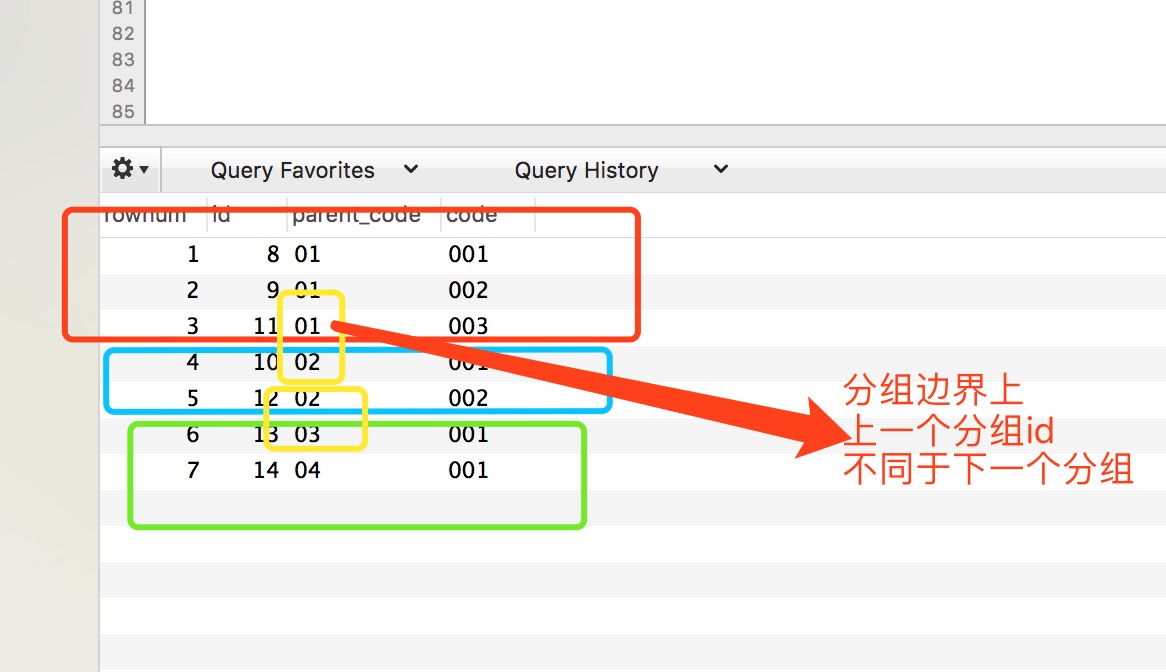
于是 再定义一个变量@pre_parent_code:='' 再存上一个 parent_code ,只要 pre_parent_code不等于当前的parent_code 让 @i:=0 else @i+=1 就ok了
select
-- rownum 判断 @pre_parent_code是否和当前的parent_code一样 ,true:让 @i+=1 false:重置@i (@i := case when @pre_parent_code=parent_code then @i + 1 else 1 end ) rownum, my_test.*,
-- 设置 @pre_parent_code等于上一个 parent_code
(@pre_parent_code:=parent_code) from my_test , (SELECT @i := 0, @pre_parent_code:='') AS a group by parent_code ,code ,id order by parent_code
结果如下图
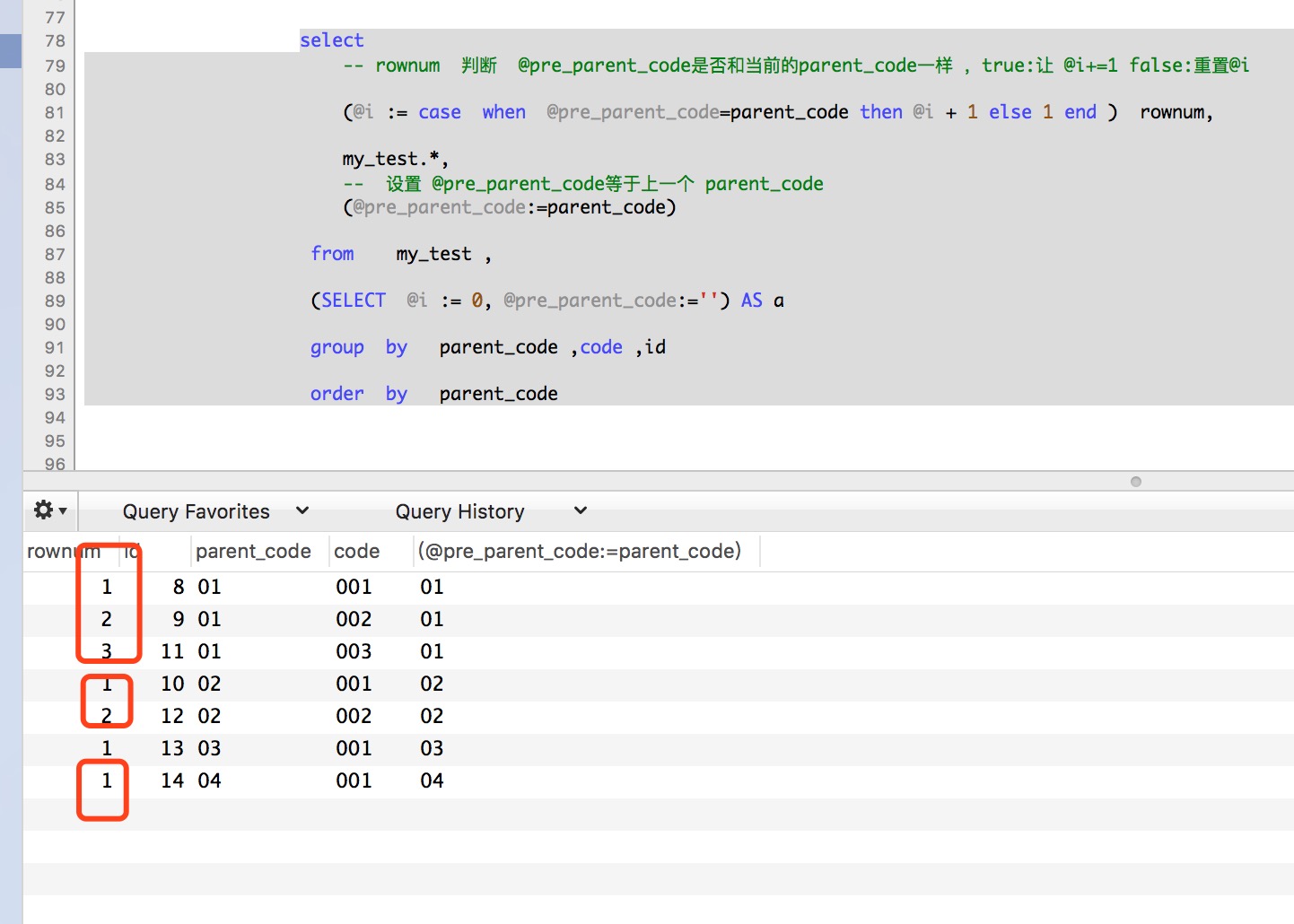
遇到难题千万别放弃,万一实现了呢,更何况这是 爱情的力量呢 ,哇O(∩_∩)O哈哈哈~
mysql分组排序加序号(不用存储过程,就简简单单sql语句哦)的更多相关文章
- mysql分组排序加序号
参照https://www.cnblogs.com/CharlieLau/p/6737243.html 一.需求 新加一个Sort 字段,初始值为1,按照parentID分组添加sort值. 根据原数 ...
- MySQL在按照某个字段分组、排序加序号
事情是这样的,最近领导给了一个新的需求,要求在一张订单表中统计每个人第一次和第二次购买的时间间隔,最后还需要按照间隔统计计数,求出中位数等数据. 由于MySQL不想Oracle那般支持行号.中位数等, ...
- mysql分组排序取最大值所在行,类似hive中row_number() over partition by
如下图, 计划实现 :按照 parent_code 分组, 取组中code最大值所在的整条记录,如红色部分.(类似hive中: row_number() over(partition by)) sel ...
- MySQL分组排序(取第一或最后)
MySQL分组排序(取第一或最后) 方法一:速度非常慢,跑了30分钟 SELECT custid, apply_date, rejectrule FROM ( SELECT *, IF ( , ) A ...
- mysql 存储过程动态执行sql语句
之前经常在程序中拼接sql语句,其实我们也可以在存储过程中拼接sql 语句,动态的执行~~ 代码如下: DROP PROCEDURE IF EXISTS SearchByDoctor;CREATE P ...
- SQL Server 存储过程 函数 和sql语句 区别
存储过程与sql语句 存储过程的优点: 1.具有更好的性能 存储过程是预编译的,只在创建时进行编译,以后每次执行存储过程都不需再重新编译, 而一般 SQL 语句每执行一次就编译一次,因此使用存 ...
- 使用C# 操作存储过程,执行sql语句通用类
如何使用C# 操作存储过程,执行sql语句? 闲话不多说,直接上代码: /// <summary> /// Sql通用类 /// </summary> ...
- mysql 分组排序前n + 长表转宽表
MySQL数据库优化的八种方式(经典必看) 建表 CREATE TABLE if not EXISTS `bb` ( `id` int not null primary key auto_increm ...
- mysql 分组排序取最值
查各个用户下单最早的一条记录 查各个用户下单最早的前两条记录 查各个用户第二次下单的记录 一.建表填数据: SET NAMES utf8mb4; -- 取消外键约束 ; -- ------------ ...
随机推荐
- Jmeter之非GUI模式(命令行)执行
在使用Jmeter进行性能测试时,建议使用非GUI模式执行. 命令行启动 1.进入jmeter安装的bin目录 2.执行Jmeter命令 如下: (1.jmeter.bat -n -t E:\apac ...
- Jmeter之检查点
检查点 Jmeter中检查点也叫断言,Jmeter中有很多类型的断言,但是最常用的是响应断言,即根据服务器返回的结果来判断测试是否通过. 响应断言 添加断言结果用于运行完毕后查看结果 测试通过 测试不 ...
- SpringMVC +Spring + MyBatis + Mysql + Redis(作为二级缓存) 配置
转载:http://blog.csdn.net/xiadi934/article/details/50786293 项目环境: 在SpringMVC +Spring + MyBatis + MySQL ...
- unity shader 热扭曲 (屏幕后处理)
效果: c# using System; using System.Collections; using System.Collections.Generic; using UnityEngine ...
- 手工设计神经MNIST使分类精度达到98%以上
设计了两个隐藏层,激活函数是tanh,使用Adam优化算法,学习率随着epoch的增大而调低 import tensorflow as tf from tensorflow.examples.tuto ...
- python+selenium浏览器截图
from selenium import webdriverfrom time import sleep driver = webdriver.Firefox() # 指定和打开浏览器driver.g ...
- linux系统管理基础知识
1.linux的安装配置 虚拟机安装 Linux安装和分区 IP地址的配置 ifup eth0,ifdoen eth0 关闭不常用的程序 关闭selinux 远程登录(多用户,多任务) 用户和角色划分 ...
- webpack收藏
收藏链接: https://www.jianshu.com/p/8ff8e71dcbc6
- 【React -- 4/100】 生命周期
生命周期 概述 意义:组件的生命周期有助于理解组件的运行方式,完成更复杂的组件功能.分析组件错误原因等 组件的生命周期: 组件从被创建到挂载到页面中运行,再到组件不在时卸载的过程 生命周期的每个阶段总 ...
- postman中x-www-form-urlencoded与form-data的区别
这是W3C定义的两种不同的表格类型,如果你想发送简单的text/ASCII数据,使用x-www-form-urlencoded , 这是默认的形式. 如果你想发送非ASCII文本或者大的二进制数据,使 ...