python类库32[多进程通信Queue+Pipe+Value+Array]
多进程通信
queue和pipe的区别: pipe用来在两个进程间通信。queue用来在多个进程间实现通信。 此两种方法为所有系统多进程通信的基本方法,几乎所有的语言都支持此两种方法。
1)Queue & JoinableQueue
queue用来在进程间传递消息,任何可以pickle-able的对象都可以在加入到queue。
multiprocessing.JoinableQueue 是 Queue的子类,增加了task_done()和join()方法。
task_done()用来告诉queue一个task完成。一般地在调用get()获得一个task,在task结束后调用task_done()来通知Queue当前task完成。
join() 阻塞直到queue中的所有的task都被处理(即task_done方法被调用)。
代码:
import multiprocessing
import time class Consumer(multiprocessing.Process):
def __init__(self, task_queue, result_queue):
multiprocessing.Process.__init__(self)
self.task_queue = task_queue
self.result_queue = result_queue def run(self):
proc_name = self.name
while True:
next_task = self.task_queue.get()
if next_task is None:
# Poison pill means shutdown
print ('%s: Exiting' % proc_name)
self.task_queue.task_done()
break
print ('%s: %s' % (proc_name, next_task))
answer = next_task() # __call__()
self.task_queue.task_done()
self.result_queue.put(answer)
return class Task(object):
def __init__(self, a, b):
self.a = a
self.b = b
def __call__(self):
time.sleep(0.1) # pretend to take some time to do the work
return '%s * %s = %s' % (self.a, self.b, self.a * self.b)
def __str__(self):
return '%s * %s' % (self.a, self.b) if __name__ == '__main__':
# Establish communication queues
tasks = multiprocessing.JoinableQueue()
results = multiprocessing.Queue()
# Start consumers
num_consumers = multiprocessing.cpu_count()
print ('Creating %d consumers' % num_consumers)
consumers = [ Consumer(tasks, results)
for i in range(num_consumers) ]
for w in consumers:
w.start()
# Enqueue jobs
num_jobs = 10
for i in range(num_jobs):
tasks.put(Task(i, i))
# Add a poison pill for each consumer
for i in range(num_consumers):
tasks.put(None) # Wait for all of the tasks to finish
tasks.join()
# Start printing results
while num_jobs:
result = results.get()
print ('Result:', result)
num_jobs -= 1
注意小技巧: 使用None来表示task处理完毕。
运行结果:
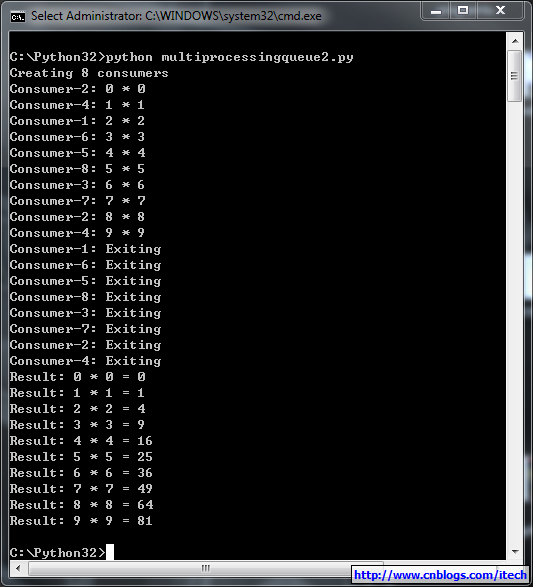
2) pipe
代码:
from multiprocessing import Process, Pipe def f(conn):
conn.send([42, None, 'hello'])
conn.close() if __name__ == '__main__':
parent_conn, child_conn = Pipe()
p = Process(target=f, args=(child_conn,))
p.start()
p.join()
print(parent_conn.recv()) # prints "[42, None, 'hello']"
3)Value + Array
Value + Array 是python中共享内存 映射文件的方法,速度比较快。
from multiprocessing import Process, Value, Array def f(n, a):
n.value = n.value + 1
for i in range(len(a)):
a[i] = a[i] * 10 if __name__ == '__main__':
num = Value('i', 1)
arr = Array('i', range(10)) p = Process(target=f, args=(num, arr))
p.start()
p.join() print(num.value)
print(arr[:])
p2 = Process(target=f, args=(num, arr))
p2.start()
p2.join() print(num.value)
print(arr[:]) # the output is :
# 2
# [0, 10, 20, 30, 40, 50, 60, 70, 80, 90]
# 3
# [0, 100, 200, 300, 400, 500, 600, 700, 800, 900]
参考:
The Python Standard Library By Example
http://www.doughellmann.com/PyMOTW/multiprocessing/communication.html
完!
python类库32[多进程通信Queue+Pipe+Value+Array]的更多相关文章
- python类库32[多进程同步Lock+Semaphore+Event]
python类库32[多进程同步Lock+Semaphore+Event] 同步的方法基本与多线程相同. 1) Lock 当多个进程需要访问共享资源的时候,Lock可以用来避免访问的冲突. imp ...
- ython实现进程间的通信有Queue,Pipe,Value+Array等,其中Queue实现多个进程间的通信,而Pipe实现两个进程间通信,而Value+Array使用得是共享内存映射文件的方式,所以速度比较快
1.Queue的使用 from multiprocessing import Queue,Process import os,time,random #添加数据函数 def proc_write(qu ...
- python进程之间的通信——Queue
我们知道进程之间的数据是互不影响的,但有时我们需要在进程之间通信,那怎么办呢? 认识Queue 可以使用multiprocessing模块的Queue实现多进程之间的数据传递,Queue本身是一个消息 ...
- python类库32[序列化和反序列化之pickle]
一 pickle pickle模块用来实现python对象的序列化和反序列化.通常地pickle将python对象序列化为二进制流或文件. python对象与文件之间的序列化和反序列化: pi ...
- python学习笔记——多进程中共享内存Value & Array
1 共享内存 基本特点: (1)共享内存是一种最为高效的进程间通信方式,进程可以直接读写内存,而不需要任何数据的拷贝. (2)为了在多个进程间交换信息,内核专门留出了一块内存区,可以由需要访问的进程将 ...
- Python 多进程编程之 进程间的通信(Queue)
Python 多进程编程之 进程间的通信(Queue) 1,进程间通信Process有时是需要通信的,操作系统提供了很多机制来实现进程之间的通信,而Queue就是其中的一个方法----这是操作系统开辟 ...
- python 守护进程、同步锁、信号量、事件、进程通信Queue
一.守护进程 1.主进程创建守护进程 其一:守护进程会在主进程代码执行结束后就终止 其二:守护进程内无法再开启子进程,否则抛出异常:AssertionError: daemonic processes ...
- Python 多线程、多进程 (二)之 多线程、同步、通信
Python 多线程.多进程 (一)之 源码执行流程.GIL Python 多线程.多进程 (二)之 多线程.同步.通信 Python 多线程.多进程 (三)之 线程进程对比.多线程 一.python ...
- python进程间通信 queue pipe
python进程间通信 1 python提供了多种进程通信的方式,主要Queue和Pipe这两种方式,Queue用于多个进程间实现通信,Pipe是两个进程的通信 1.1 Queue有两个方法: Put ...
随机推荐
- 缓存融合(Cache Fusion)介绍
概念 简单地说,缓存融合就是把Oracle RAC数据库中所有数据库缓存作为一个共享的数据库缓存,并被RAC中的所有节点共享.它是实现RAC的基本技术. 缓存融合主要有如下四个功能: (1) 提供扩展 ...
- LeetCode.993-二叉树中的堂兄弟(Cousins in Binary Tree)
这是悦乐书的第374次更新,第401篇原创 01 看题和准备 今天介绍的是LeetCode算法题中Easy级别的第235题(顺位题号是993).在二叉树中,根节点在深度0处,并且每个深度为k的节点的子 ...
- Shell编程、part4
本节内容 1. shell函数 2. shell正则表达式 shell函数 shell中允许将一组命令集合或语句形成一段可用代码,这些代码块称为shell函数.给这段代码起个名字称为函数名,后续可以直 ...
- 【VS开发】使用 NuGet 管理项目库
NuGet 使用 NuGet 管理项目库 Phil Haack 无论多么努力,Microsoft 也没办法提供开发人员所需要的每一个库. 虽然 Microsoft 在全球的员工人数接近 90,000, ...
- python 并发编程 多线程 GIL与多线程
GIL与多线程 有了GIL的存在,同一时刻同一进程中只有一个线程被执行 多进程可以利用多核,但是开销大,而python的多线程开销小,但却无法利用多核优势 1.cpu到底是用来做计算的,还是用来做I/ ...
- python 爬取网页内的代理服务器列表(需调整优化)
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Date : 2017-08-30 20:38:23 # @Author : EnderZhou (z ...
- GPIB、USB、PCI、PCI Express和以太网/LAN/LXI
GPIB 我们研究的第一个总线是IEEE 488总线,较为熟悉的称谓是GPIB(通用接口总线).GPIB是一种在业界已经得到证明的专为仪器控制应用设计的总线.GPIB在过去30年来一直是鲁棒的.可靠的 ...
- numpy中的快速的元素级数组函数
numpy中的快速的元素级数组函数 一元(unary)ufunc 对于数组中的每一个元素,都将元素代入函数,将得到的结果放回到原来的位置 >>> import numpy as np ...
- luogu 黑题 P3724大佬
#include<bits/stdc++.h> using namespace std; #define ll long long #define RG register #define ...
- spark日志+hivesql
windows本地读取hive,需要在resource里面将集群中的hive-site.xml下载下来. <?xml version="1.0" encoding=" ...